







SE-SSD

Key Knowledgeable:
-
Teacher-Student SSD

SE-SSD网络核心框架主要包括Teacher SSD和Student SSD两个部分。
SSD由Voxelization、SPConvNet、BEVConvNet、MT-Head组成。
Teacher SSD为Student SSD的训练提供soft target:不像groundtruth准确,唯一,过于死板,Teacher 预测的box产生更多信息,更利于student学习。同时Teacher和Student的预测目标相近,利于Student的微调。
Student SSD为Teacher SSD通过EMA提供参数进行迭代。可以理解为Teacher SSD是Student SSD一段时间内的一个稳定状态。 -
Conistency Loss
先通过置信度阈值、Student与Teacherbox之间的IoU阈值过滤不相关的box。
N为初始的预测box数量,N’为过滤之后的box数量。
之后计算一致性loss:Student和Teacher预测的loss,以使它们的预测一致。
一致性loss使用Smooth-L1计算box坐标、大小、角度、分类。均匀优化不同维度的特征。
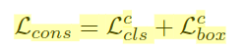
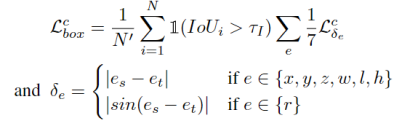
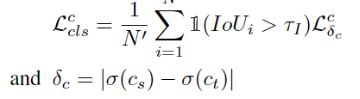
-
Orientation-Aware Ditance-IoU Loss
直接使用SmoothL1计算IoU作为box的loss无法在稀疏的点云数据中得到准确的预测。
加上额外的两个值作为loss:中心之间的距离与BEV角度上的偏差,提高了预测的性能:
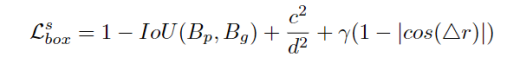
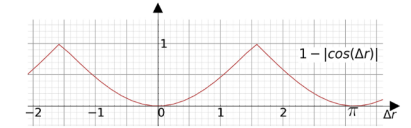
c为中心点距离,d为包含predicted与groundtruth的最小矩形对角线(将c转为相对值),∆r为BEV的角度差。
1-|cos(∆r)|的曲线图:利于训练过程的快速收敛与缓慢微调。
类别预测与方向预测使用Focal loss 和cross-entropyloss。
最后总的Student Loss由不同的权重超参数的ODIoU loss、consistency loss组成
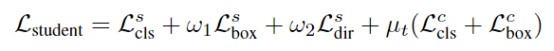
-
Data Augmetation
真实数据可能遇到的遮挡、距离远近变化的大小、形状多样性引起的变化等情况导致某一类别的点云数据发生变化,对训练的点云数据进行一系列操作来模拟这些情况以此提高模型的泛化能力。
global transformations
将Teacher SSD提供的soft target,groundtruth提供的hard target进行随机平移、翻转和缩放等操作。
Shape-Aware Data Augmetation
将groundtruth box的中心与box的8个点相连,将box内的点划分为6个集合,接下来对以集合为元素进行3个操作:
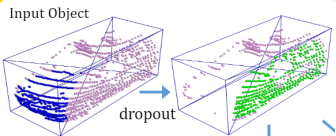
I. random dropout
随机选一个box的一个集合丢弃。
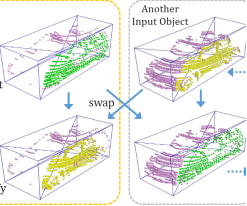
II .random swap
随机选一个box的一个集合与另一个box的一个集合进行交换。
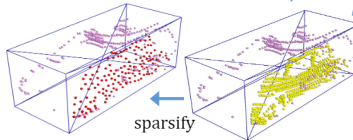
III.random sparsifying
随机选一个box的一个集合FPS采样。















 1448
1448











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









