







2022/05/16
(一)目的
掌握利用CUDA进行矩阵相乘的两种方式(全局内存和共享内存)
(二)内容
完成矩阵乘法的并行程序的实现
任务描述:
考虑计算两个大规模的矩阵乘法: C=A*B。其中A的大小为1000×800,B矩阵大小为800×1200,C矩阵大小为1000×1200。矩阵初始化要求如下:
(1)A矩阵的初始化:每一行第1个位置为学号最后1位,以后位置为第1个位置依次加1。
(2)B矩阵的初始化:每一行第1个位置为学号倒数第2位,以后位置为第1个位置依次加1。
实现过程中需要完成如下函数:
(1)int verify_result(int *input, int *ref, int row, int col); //对结果进行的正确性进行校验。其中input为待校验结果(C_gm或者C_sm),ref为正确结果(C_ref);
(2)void MatrixMulCPU(int *p_A, int *p_B, int *p_C, int A_row, int A_col, int B_col); //CPU 串行矩阵乘法,因为C矩阵的row=A矩阵的row,C矩阵的col=B矩阵的col,这里进行了简化只传了A_row, A_col, B_col 三个参数;
(3)void MatrixMul_gm(int *p_A, int *p_B, int *p_C, int A_row, int A_col, int B_col); //GPU global memory矩阵乘法
(4)void MatrixMul_sm(int *p_A, int *p_B, int *p_C, int A_row, int A_col, int B_col); //GPU share memory矩阵乘法。
并行思路:
global memory:使用多个block进行并行计算,但GPU线程访问都是在global memory中。
shared memory :对矩阵A*B=C,用block去划分C矩阵,得到若干个子矩阵p_C。利用分块矩阵乘法公式,在计算某一个p_C时,只取对应的A和B的子块,并读到shared memory中。
CPU代码
int matrixMutilCPU(float* A, float* B, int rowA, int colA, int rowB, int colB, float* C) {
float tmp;
if (colA != rowB)
return -1;
for (int i = 0; i < rowA; i++) {
for (int j = 0; j < colB; j++) { //loop for C
tmp = 0;
for (int k = 0; k < colA; k++) {
tmp += (A[colA * i + k] * B[colB * k + j]);
}
C[i * colB + j] = tmp;
}
}
return 0;
}
GPU代码
__global__ void matrixMutilGPU(float* A, float* B, int colA, int colB, float* C) {
int xb = blockIdx.x;
int yb = blockIdx.y;
int x = threadIdx.x;
int y = threadIdx.y;
float* BeginA = A + yb * blockSize * colA;
float* EndA = BeginA + colA;
float* BeginB = B + blockSize * xb;
int stepA = blockSize;
int stepB = blockSize * colB;
float tsum = 0;
//每一个block A和B的子块首地址
for (; BeginA < EndA; BeginA += stepA, BeginB += stepB) {
__shared__ float As[blockSize][blockSize];
__shared__ float Bs[blockSize][blockSize];
// 每个线程load一个元素到shared mem中
As[y][x] = *(BeginA + y * colA + x);
Bs[y][x] = *(BeginB + y * colB + x);
__syncthreads();//同步
for (int k = 0; k < blockSize; k++) {
tsum = tsum + As[y][k] * Bs[k][x];
}
__syncthreads();//同步,确保该块内所有线程都完成了计算。下次循环,要重复利用共享内存。
}
//写入结果 注意坐标的计算方法
C[yb * blockSize * colB + y * colB + xb * blockSize + x] = tsum;
}
__global__ void matrixMutilGPU_slow(float* p_A, float*p_ B, int A_col, int B_col, float* A_row) {
//计算结果矩阵的二维坐标
int row = blockDim.y * blockIdx.y + threadIdx.y;
int col = blockDim.x * blockIdx.x + threadIdx.x;
float tsum = 0;
for (int k = 0; k < B_col; k++) {
tsum += (p_A [row * A_col + k] * p_B[k * B_col + col]);
}
//写入结果
p_C[row * B_col + col] = tsum;
}
结果
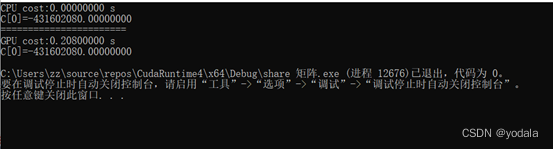


















 717
717

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









