







作者 | Julia Kho
编译 | CDA数据分析师
热图是数据的图形表示,也就是说,它使用颜色来向读者传达价值。当您拥有大量数据时,这是一个很好的工具,可以帮助观众了解最重要的区域。
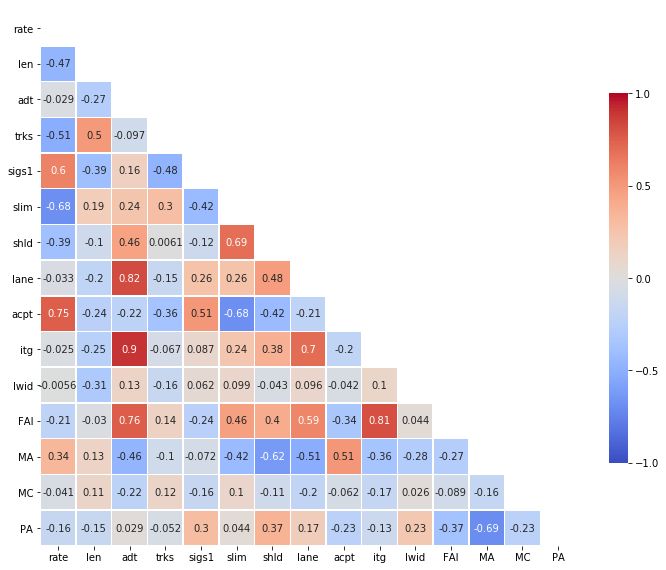
在本文中,我将指导您通过5个简单步骤创建自己的相关矩阵注释热图。
- 导入数据
- 创建关联矩阵
- 设置mask隐藏上三角
- 在Seaborn中创建热图
- 导出热图
1)导入数据
df = pd.read_csv("Highway1.csv",index_col = 0)
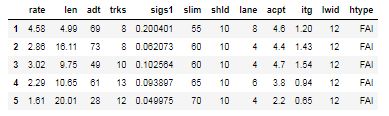
该公路事故数据集包含汽车事故率,每百万车辆英里的事故以及若干设计变量。
2)创建相关矩阵
corr_matrix = df.corr()
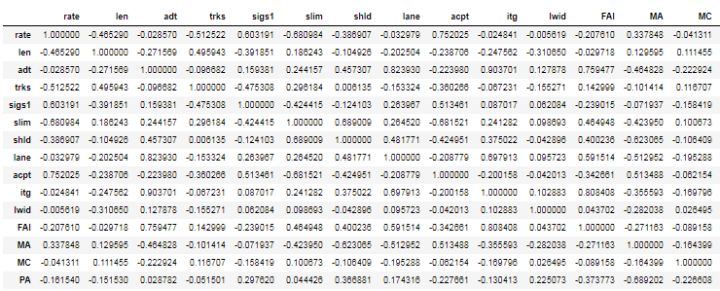
我们使用的是.corr 创建相关矩阵 。请注意,此矩阵中不存在htype列,因为它不是数字。我们需要使用htype来计算相关性。
df_dummy = pd.get_dummies(df.htype)
df = pd.concat([df,df_dummy],axis = 1)
另外,请注意,相关矩阵的上三角部分与下三角对称。因此,我们的热图不需要显示整个矩阵。我们将在下一步隐藏上三角形。
3)设置mask隐藏上三角
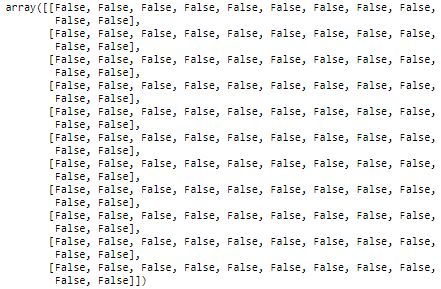
mask = np.zeros_like(corr_matrix,dtype = np.bool)
mask[np.triu_indices_from(mask)] =True
让我们打破上面的代码吧。 np.zeros_like() 返回一个零数组,其形状和类型与给定的数组相同。通过传递相关矩阵,我们得到如下的零数组。

该 dtype=np.bool 参数会覆盖数据类型,因此我们的数组是一个布尔数组。
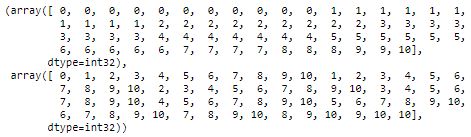
np.triu_indices_from(mask) 返回数组上三角形的索引。
现在,我们将上三角形设置为True。 mask[np.triu_indices_from(mask)]= True
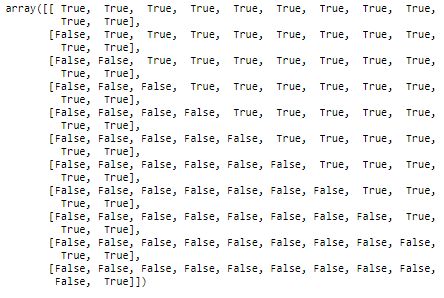
现在,我们有一个掩码可以用来生成热图。
4)在Seaborn中创建热图
f,ax = plt.subplots(figsize =(11,15))
heatmap=sns.heatmap(corr_matrix,
mask = mask,
square = True,
linewidths = .5,
cmap ='coolwarm',
cbar_kws = {'shrink':.4,
'ticks':[-1,-.5,0,0.5,1]},
vmin = -1,
vmax = 1,
annot = True,
annot_kws = {"size":12})
增加列名做为标签
ax.set_yticklabels(corr_matrix.columns,rotation = 0)
ax.set_xticklabels(corr_matrix.columns)
sns.set_style({'xtick.bottom':True},{'ytick.left':True})
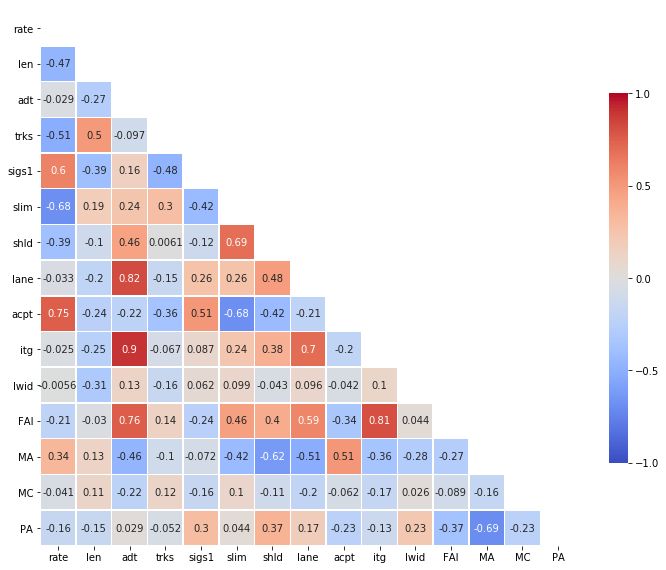
为了创建我们的热图,我们传递步骤3中的相关矩阵和我们在步骤4中创建的蒙版以及自定义参数,以使我们的热图看起来更好。如果您有兴趣了解每条线的作用,请参考以下参数说明。
使每个单元格成方形
square = True,
设置将每个单元格划分为.5的行的宽度
linewidths = .5,
Map数据值到coolwarm颜色空间
cmap ='coolwarm',
Shrink在[-1,-.5,0,0.5,1]处的图例大小和标签刻度线
cbar_kws = {'shrink':.4,'ticks':[-1,-.5,0,0.5,1]},
设置颜色条的最小值
vmin = -1,
设置颜色条的最大值
vmax = 1,
转到相关值的注释
annot = True,
将注释设置为12
annot_kws = {"size":12}
将列名添加到x标签
ax.set_xticklabels(corr_matrix.columns)
将列名添加到y标签并将文本旋转到0度
ax.set_yticklabels(corr_matrix.columns,rotation = 0)
在热图的底部和左侧显示标记
sns.set_style({'xtick.bottom':True},{'ytick.left':True})
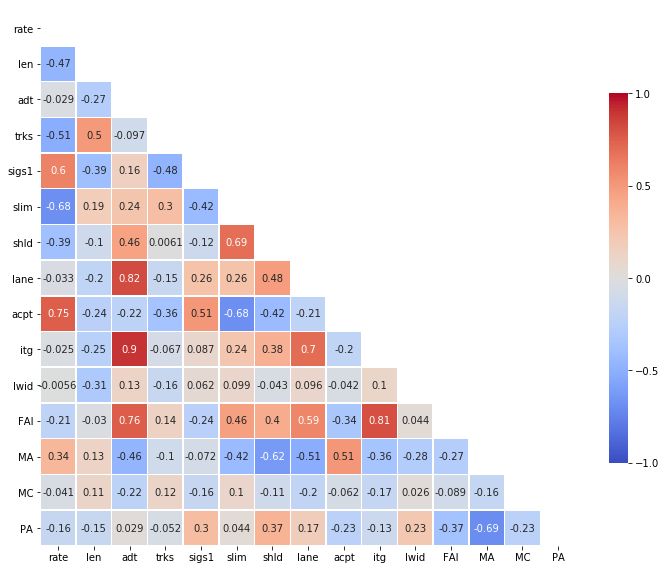
5)导出热图 现在你有热图,让我们把它导出。
heatmap.get_figure().savefig('heatmap.png', bbox_inches='tight')
如果您发现有一个非常大的热图不能正确导出,请使用bbox_inches = 'tight' 以防止图像被切断。

搜索进入小程序,解锁更多精彩资讯和优质内容,不要错过哟!














 175
175











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









