






24年5月MIT的论文“Probing Multimodal LLMs as World Models for Driving”。
主要对多模态大语言模型(MLLM)在自动驾驶领域的应用进行了审视,并挑战/验证了一些常见的假设,重点关注它们通过图像/帧序列推理和解释在闭环控制环境中动态驾驶场景的能力。 尽管 GPT-4V 等 MLLM 取得了显着进步,但它们在复杂、动态驾驶环境中的性能在很大程度上仍未经过测试,并且存在广泛的探索领域。 作者进行了一项全面的实验研究,从固定车载摄像头的角度评估各种 MLLM 作为世界驾驶模型的能力。 研究结果表明,虽然这些模型能够熟练地解释单个图像,但在为描述动态行为合成的连贯叙述或逻辑图像序列方面存在很大困难。 实验表明,预测 (i) 基本车辆动力学(前进/后退、加速/减速、右转或左转)、(ii) 与其他道路参与者的交互(例如,识别超速车或交通拥堵)、(iii) 轨迹规划,以及(iv)开放集动态场景推理,表明模型训练数据存在偏差。 为了进行这项实验研究,引入了一个模拟器,DRIVESIM,旨在生成不同的驾驶场景,为评估驾驶领域的 MLLM 提供一个平台。 此外,还有完整的开源代码和新数据集“EVAL-LLM-DRIVE”,用于评估驾驶中的 MLLM。 其结果凸显最先进的 MLLM 当前能力的关键差距,强调需要增强基础模型以提高其在现实世界动态环境中的适用性。
如图所示:实验结果发现,MLLM 很难从动态场景中创建连贯的序列或叙述,因此无法推理汽车运动/动力学、超速汽车、交通等。 为此,用 DRIVESIM 模拟器生成驾驶数据集,并将其与数据一起开源以供未来探索。 研究结果强调 MLLM 当前能力的关键差距,表明需要改进模型以增强其现实世界的适用性。

为了满足实验设置的要求,需要受控环境和反事实测试(例如生成与原始数据集不同的反事实数据,而不是 MLLM 的反事实推理),作者在 nuScenes 数据集之上开发了一个数据驱动的模拟器 [45]。 这种方法有效地平衡了传感器合成真实性[46]、[47]、闭环仿真[48]、[44]和场景设置可控性[49]、[50],使其成为用例的理想匹配。
实验方法的基石涉及决策的闭环执行,探索 MLLM 的推理,特别是提出以下问题: “如果汽车采取的操作与数据集中的动作不同怎么办?”
解决这个问题需要实施传感器合成来适应假设的“假设”场景。 从自车的初始位置开始,采用车辆动力学进行闭环控制,将输入空间表征如下:(i)使用自行车模型的加速度和转向速度,(ii)通过自行车模型集成版的速度和转向角,以及(iii)相对于局部坐标系的直接姿态调整(用于无动力学运动规划)。
为了促进传感器数据合成,用实际传感器测量与重模拟技术[44]相结合,结合地图信息(对于后续部分中的目标/角色合成和行为建模也至关重要)。 在较高层面上,地图信息包括互连的车道段和描绘各种道路组成部分的其他几何元素,例如停车线和交通标志。 沿着每个车道段,都有样本点,每个样本点都与传感器测量结果相关联,例如相机图像。 该姿态源自车辆动力学,与地图上最近的样本点相匹配,与传感器的方向一起为渲染和行为建模提供局部坐标系。 对于渲染,最初通过应用于 RGB 图像和稀疏 LiDAR 点的深度补全技术 [51] 来获取深度信息。 随后,用针孔相机模型将 RGB 像素投影到 3D 空间中,创建可以从不同视点渲染的 3D 网格。 利用基于重模拟的相关 RGB 图像的本地坐标系计算的外部参数以及用户定义的相机内部参数,可以对最终图像执行渲染。
“假设”实验设置的另一个方面涉及解决诸如 “如果路边突然出现一只鹿怎么办?” 这就需要能够模拟场景中的合成目标或角色。 基于所描述的 3D 重建流程,将所需目标和角色的 3D 网格无缝集成到场景中。 通过利用LLM对其注释的文本理解能力,可以从 Objaverse 数据集 [52] 有效地获取这些网格。 例如,可以识别表明相应网格代表动物的注释。 利用地图的几何和语义信息,战略性地将网格放置在合理的位置和方向。 例如,在与自车相同的车道旁边、交通灯下方、停车线上方等。
在添加合成交通参与者的基础上,这些参与者的行为或运动对于 MLLM 的推理过程变得至关重要。 这就引入了探索诸如以下场景的必要性:“如果飞机从上空飞过或降落在路上怎么办?”或 “如果汽车因交通堵塞而减速怎么办?”
对于地面车辆的行为,用PID控制器[53]进行转向控制,跟踪从地图或运动规划导出的参考路径; 对于加速控制,用IDM[54],专注于自车前方最近的参与者,该参与者正在朝着可能导致与自车发生碰撞的方向移动。 对于运动规划,部署一个五次多项式轨迹生成功能的状态格规划器(lattice planner)[55],其中目标状态格被确定为在当前车道或相邻车道局部坐标系中本车前方的特定距离。 为了对其他角色行为进行建模,在预定义的开始和结束姿势之间执行样条插值来创建轨迹。 重点是模拟合成角色对自车、它们自己以及场景中其他预先存在的角色或目标的反应,而不是对那些已经存在的实体行为进行建模。
MLLM 作为世界模型在 DRIVESIM 提出的关键场景中的性能,主要是如图 所示的类别:(i) 自车动力学、(ii) 其他道路参与者、(iii) 轨迹规划,以及(iv)开放集动态场景推理。
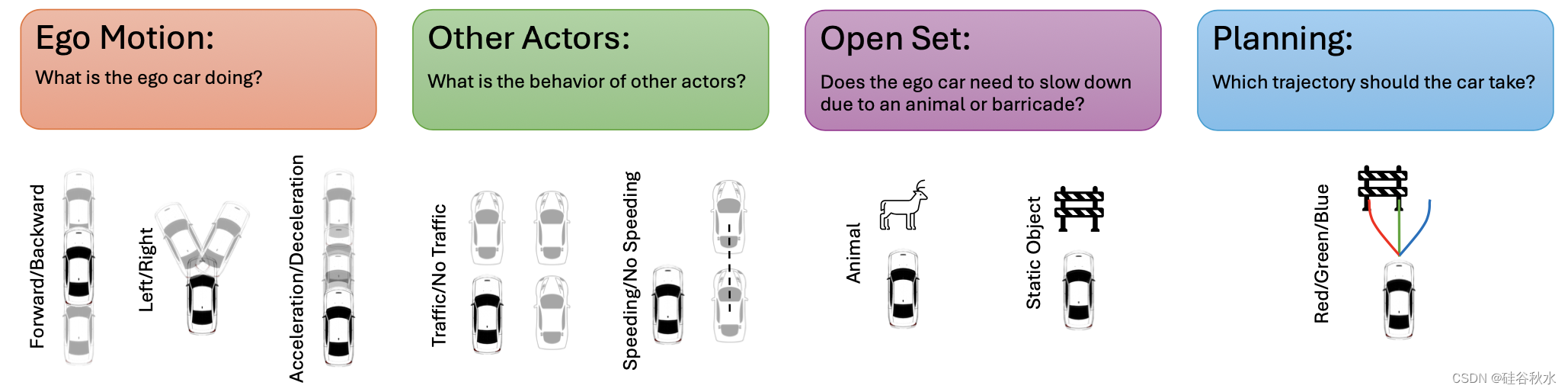
具体来说,对于驾驶,测试MLLM作为世界模型确定自车运动的能力:汽车是向前还是向后行驶? 加速还是减速? 是左转还是右转? 一切都以明确的方式进行。 然后,评估街道上其他因素的推理能力,以确定是否检测到超速车(是否有超速车?)或交通拥堵(是否有交通拥堵?)。 此外,还基于开放集(甚至奇怪的)环境测试 MLLM 的决策,例如提供突然出现的动物或静态目标甚至飞机着陆的图像(自车能否继续移动) 同一条车道?。 最终可以测试 MLLM 的能力,选择绕过障碍物导航的最佳轨迹,同时尝试保持在车道上(哪条轨迹最好遵循?)。
下表 展示 Claude3、GPT-4V、LLaVA-1.6、InstructBLIP 和 MiniGPT4-v2 在这些情况下的表现。

如图是一些DRIVESIM提供的合成例子:



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









