










24年2月地平线的论文“VADv2: End-to-End Vectorized Autonomous Driving via Probabilistic Planning”。
从大规模的驾驶演示中学习类似人类的驾驶策略是有希望的,但规划的不确定性和不可定性使其具有挑战性。在这项工作中,为了应对不确定性问题,提出了一种基于概率规划的端到端驾驶模型VADv2。VADv2以流方式将多视图图像序列作为输入,将传感器数据转换为环境tokens嵌入,输出动作的概率分布,并对一个动作进行采样以控制车辆。只有使用摄像头传感器,VADv2才能在CARLA Town05基准上实现最先进的闭环性能,显著优于所有现有方法。即使没有基于规则的封装,它也能在完全端到端方式稳定运行。闭环演示展示在 https://hgao-cv.github.io/VADv2 。
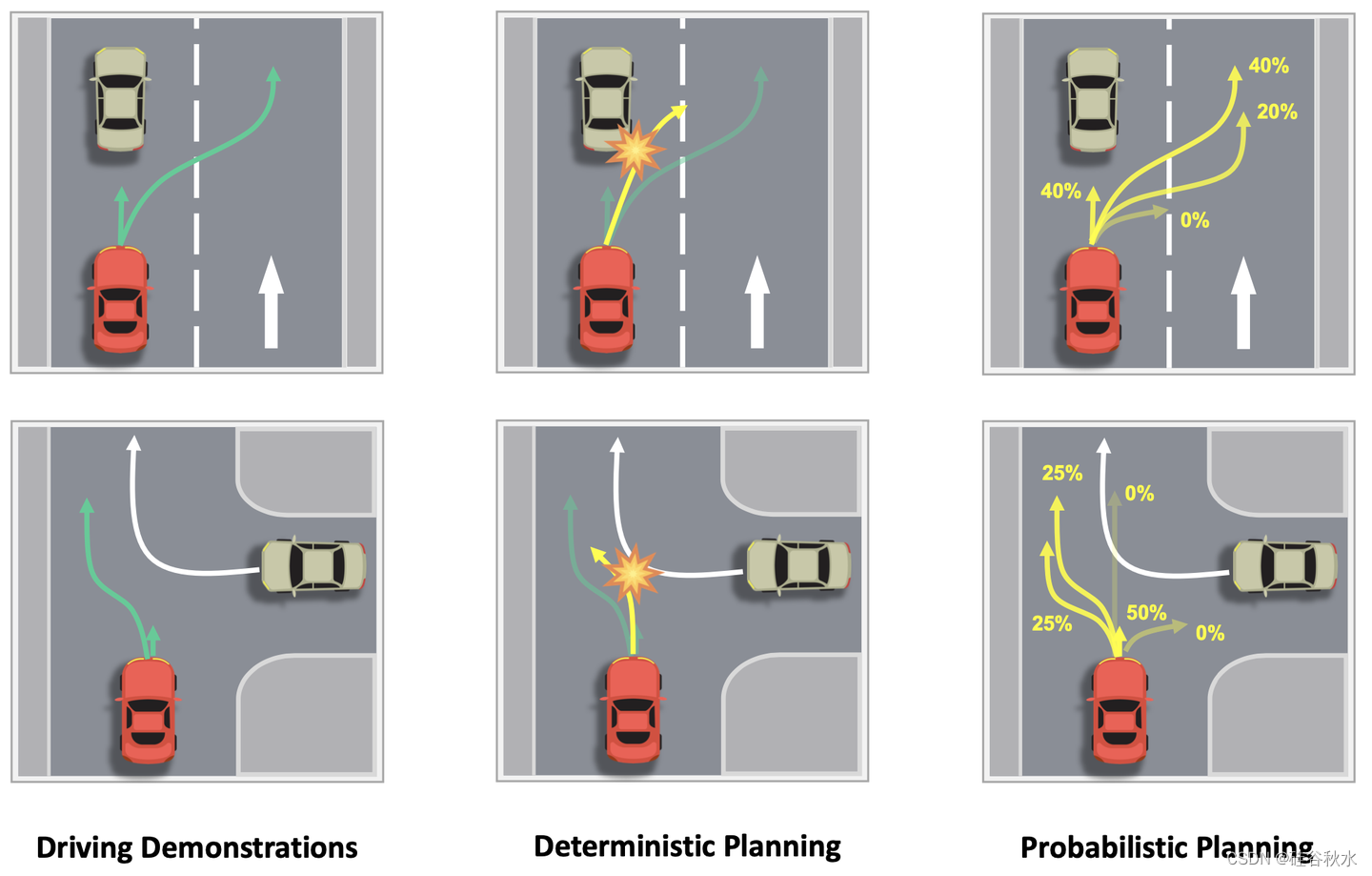
如图所示是规划中存在不确定性。环境和动作之间不存在确定性的关系。确定性规划无法对这种不确定性进行建模,尤其是当可行解空间是非凸的。VAD v2基于概率规划,并从大规模驾驶演示中学习环境条件下的动作概率分布。
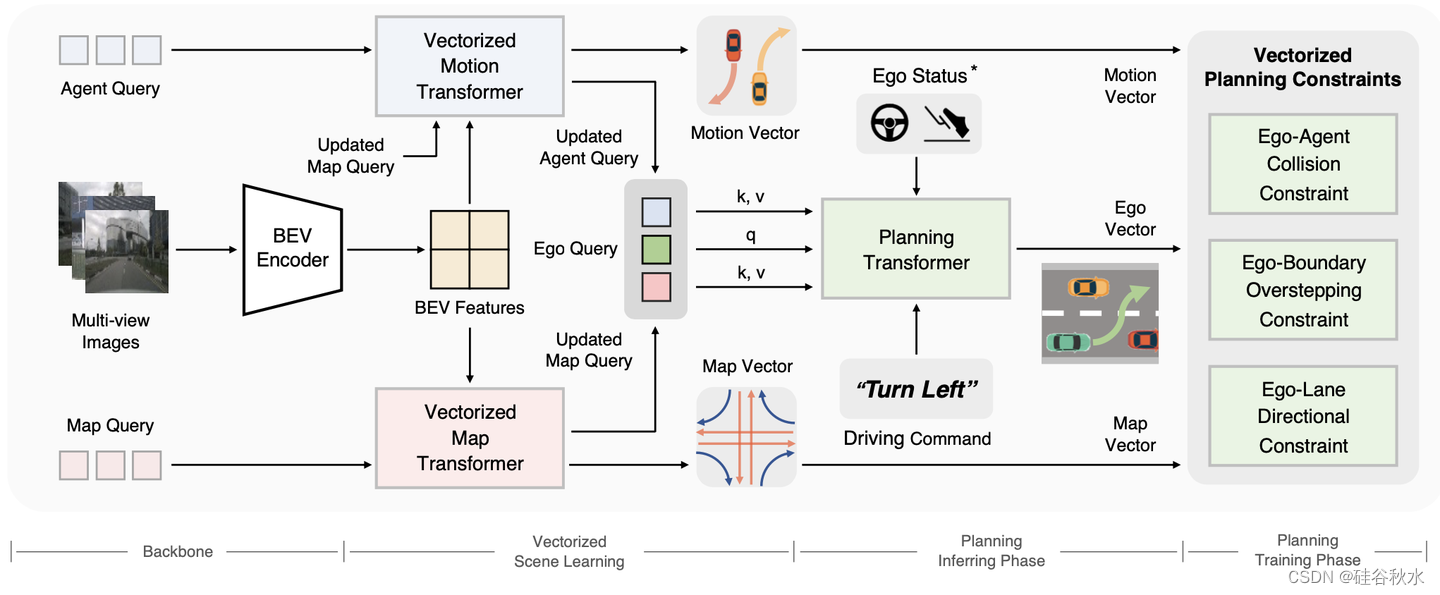
先介绍一下参考的VAD方法。如图是VAD的总体架构:VAD的整个流水线分为四个阶段。主干包括图像特征提取器和BEV编码器,将图像特征投影到BEV特征。矢量化场景学习旨在将场景信息编码为智体查询和地图查询,并用运动矢量和地图矢量表示场景。在规划的推断阶段,VAD利用自查询通过查询交互可提取地图和智体信息,并输出规划轨迹(表示为自向量)。所提出的矢量化规划约束使训练阶段的规划轨迹规则化。注:* = optional
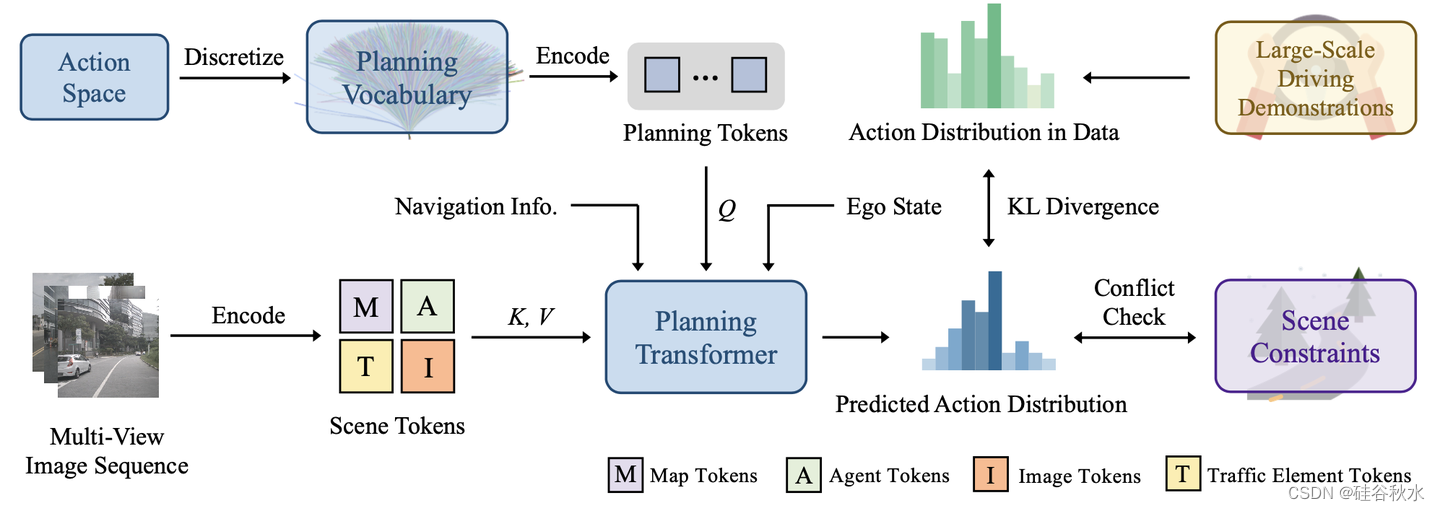
如图是VADv2的总体架构。VADv2以流方式将多视图图像序列作为输入,将传感器数据转换为环境tokens嵌入,输出动作的概率分布,并对一个动作进行采样以控制车辆。使用大规模驾驶演示和场景约束来监督预测的分布。
作者提出概率规划来应对规划的不确定性。将规划策略建模为环境条件下的非平稳随机过程,公式化为p(a|o)。基于大规模驾驶示范,将规划动作空间近似为概率分布,并在每个时间步长从分布中采样一个动作来控制车辆。
规划行动空间是一个高维连续时空空间a={a}。由于直接拟合连续规划行动空间是不可行的,将规划行动空间离散为一个大的规划词汇集V={ai}i=1~N。具体来说,收集驾驶示范中的所有规划动作,并采用最远轨迹采样来选择N个具有代表性的动作作为规划词汇。V中的每个轨迹都是从驾驶演示中采样的,因此自然满足自车的运动学约束,这意味着当轨迹转换为控制信号(转向、油门和制动)时,控制信号值不会超过可行范围。默认情况下,N设置为4096。
将规划词汇表中的每个动作表示为航路点序列a=(x1,y1,x2,y2,…,xT,yT)。每个航路点对应一个未来的时间戳。假设概率p(a)相对于a是连续的,并且对a的小偏差不敏感,即lim∆a→0[p(a)−p(a+∆a)]=0。受NeRF[35]对5D空间(x,y,z,θ,φ)上的连续辐射场进行建模的启发,采用概率场对从动作空间a到概率分布{p(a)|a}的连续映射进行建模。将每个动作(轨迹)编码为高维规划tokens嵌入E(a),用级联的Transformer解码器与环境信息Eenv进行交互,并与导航信息Enavi和自我状态Estate组合以输出概率,即:
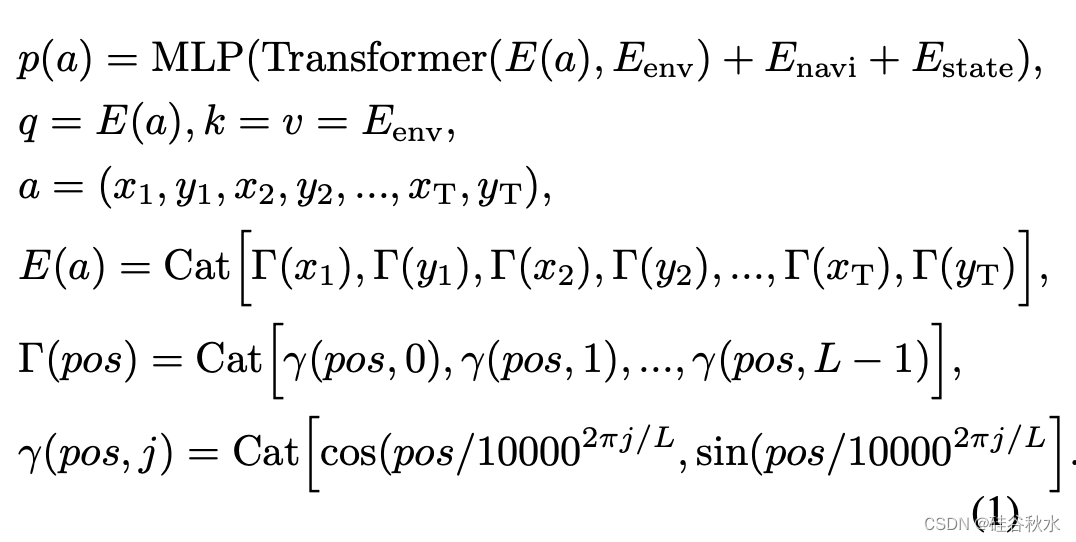
训练的损失包括三项:分布,冲突和场景token
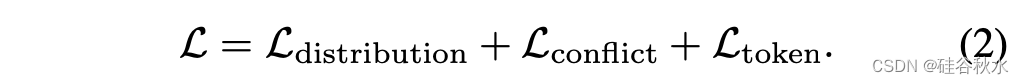
场景tokens包括地图、智体和交通元素,智体包括检测和运动预测,交通元素分为交通牌和红绿灯两个。















 424
424

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









