







前言🪐
本文由VAD原作Bo Jiang(蒋博)博士梳理,站在原作视角,对VAD系列的两项工作都做了详细的介绍。
蒋博,华中科技大学Vision Lab博士研究生,师从刘文予教授和王兴刚教授,提出VAD, VADv2等算法,在nuScenes和Carla端到端自动驾驶任务上取得多次第一。
VAD系列论文信息:
VAD: Vectorized Scene Representation for Efficient Autonomous Driving
作者:
Bo Jiang, Shaoyu Chen*, Qing Xu, Bencheng Liao, Jiajie Chen, Helong
Zhou, Qian Zhang, Wenyu Liu, Chang Huang, Xinggang Wang*项目主页:https://github.com/hustvl/VAD
VADv2: End-to-End Vectorized Autonomous Driving via Probabilistic Planning
作者:
Shaoyu Chen, Bo Jiang*, Hao Gao, Bencheng Liao, Qing Xu, Qian Zhang,
Chang Huang, Wenyu Liu, Xinggang Wang*项目主页:https://hgao-cv.github.io/VADv2
VADv1:基于矢量场景表征的端到端自动驾驶
自动驾驶系统通常采用分阶段模块化的设计,即感知、预测、规划等模块相互解耦,独立优化。但对于模块化方案,模块间无法协同优化,存在误差累积,感知的漏检误检将会影响规划的安全性。近年来,端到端自动驾驶逐渐受到业界的关注。端到端方案基于数据驱动的方式优化整个系统,打通了各个模块的壁垒,并减少了繁琐的后处理,具有很高的研究价值。然而,之前的端到端方案往往基于栅格化的环境表征(如图1)。这种密集的表征不具备高层级的语义信息,并且需要较高的计算代价。
在ICCV 2023上,我们提出基于矢量化场景表征的端到端自动驾驶算法——VAD。VAD摈弃了栅格化表征,对整个驾驶场景进行矢量化建模(如图2),并利用矢量环境信息对自车规划轨迹进行约束。相比于之前的方案,VAD在规划性能和推理速度上具有明显的优势。

图1|栅格化场景表征©️【深蓝AI】

图2|矢量化场景表征©️【深蓝AI】
1. VAD架构——基于Transformer的端到端模型

图3|VAD模型框架©️【深蓝AI】
VAD的各个子模块都是基于统一的Transformer结构(如图3所示)。其实BEV Encoder用于编码输入的环视图像,并将其转化为鸟瞰图视角(BEV)下的特征图;Vectorzied Motion Transformer提取场景中的动态目标信息,实现动态目标检测和矢量化的轨迹预测;Vectorzied Map Transformer提取场景中矢量化的静态元素信息(如车道线,路沿和人行道);Planning Transformer以隐式的动静态场景特征作为输入,提取其中与驾驶决策规划相关的信息,并完成自动驾驶车辆的轨迹规划。另外在模型训练阶段,VAD基于矢量场景表征,对自车的规划轨迹进行矢量化约束,从而提升规划的安全性。

图4|基于矢量场景表征的规划约束©️【深蓝AI】
2. 基于矢量场景表征的规划约束
此前的工作大多采用各种后处理策略对规划轨迹进行优化,以提升规划安全性。例如,使用占据图预测结果对规划轨迹进行微调,从而使规划轨迹位于可行驶区域内。这种方法破坏了模型的端到端学习能力,另外后处理也会带来额外的计算开销,降低模型的推理速度。VAD完全摈弃了后处理策略,而是选择在训练阶段,使用驾驶先验知识优化规划表现,从而在不引入额外推理计算开销的前提下,提升了规划的安全性。
●自车-他车碰撞约束
基于场景中其他动态目标预测的矢量化轨迹和自车规划轨迹的碰撞约束。VAD将自车安全边界分解为横向和纵向的安全距离,当规划轨迹在任一方向与他车预测轨迹的距离小于指定的安全阈值时,则惩罚该轨迹,从而避免自车规划轨迹与他车预测轨迹相交。
●自车-边界越界约束
基于预测的矢量化边界线,VAD约束自车规划轨迹始终在可行驶区域内。当自车规划轨迹越出道路边界线时,则惩罚该轨迹。
●自车-道路方向约束
VAD基于预测的道路线方向,约束自车规划轨迹朝向与道路前进方向保持一致。当自车规划轨迹朝向与道路前进方向有较大差异时,则惩罚该轨迹。
3. VAD规划性能
VAD在nuScenes开环验证和CARLA闭环验证中均取得了state-of-the-art的规划性能。除此之外,相比之前的方案,大幅提升了模型的推理速度。

图5|nuScenes开环规划性能©️【深蓝AI】
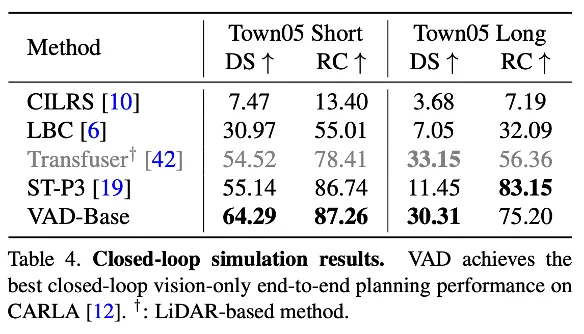
图6|CARLA闭环规划性能©️【深蓝AI】
VAD初步探索了基于矢量化场景表征的端到端自动驾驶算法框架。如何建模驾驶决策中的不确定性和多模态特性,从而实现更鲁棒精准的规划决策表现,将在VADv2的工作中展开。
VADv2: 基于概率性规划的端到端自动驾驶
大语言模型(Large Languague Model)通过在互联网级别语料库上的预训练,学习到语法、语义和概念关系等高维知识,进而涌现通用智能。驾驶场景中同样存在着数量庞大并且源源不断产生的人类驾驶数据。从人类驾驶数据中学习拟人的驾驶策略,具备成熟的数据基础。但在算法层面,如何建模和训练,仍需进一步的探索。VADv1初步探索了基于矢量化场景表征的端到端自动驾驶算法框架。在VADv1的基础上,VADv2基于概率性规划,以数据驱动的范式从大量驾驶数据中学习端到端驾驶策略。
1. 概率性规划
与感知不同,规划中存在着更多的不确定性,对于同一场景,存在不同的合理的决策规划结果。环境信息到决策规划不存在明确的映射关系,因此学习拟人的驾驶策略极具挑战性。以往的基于学习的规划方法确定性地通过MLP回归出规划轨迹,无法应对环境信息和决策规划之间不明确的映射关系。同时基于神经网络输出的轨迹无法保证满足运动学约束,仍需要后端的轨迹优化。
VADv2采用概率性规划的方法,从大量的人类驾驶数据中,拟合每一时刻基于环境信息的自车轨迹概率分布,将问题转化为预测每一条轨迹和环境信息的相关性,从而应对规划中的不确定性。
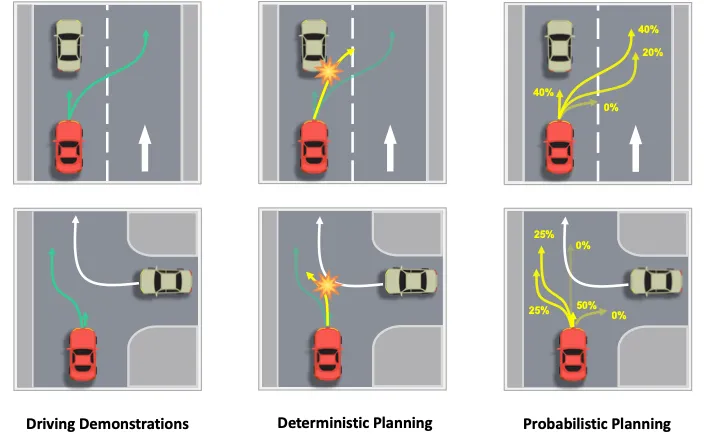
图7|规划中的不确定性©️【深蓝AI】
2. 算法框架
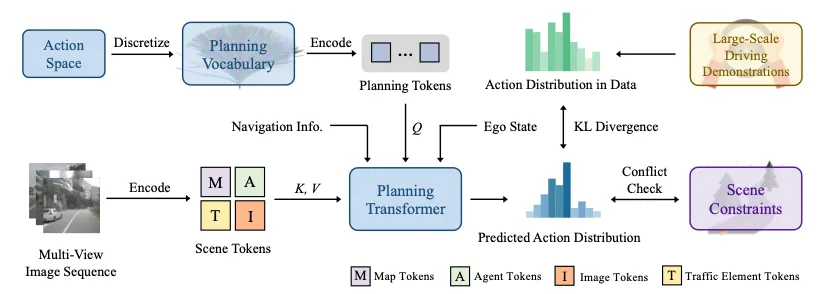
图8|VADv2算法框架©️【深蓝AI】
如图8所示,VADv2以车载相机采集的流式图像序列作为输入。鉴于图像信息稀疏性,VADv2将图像信息转换为具有高层语义信息的tokens。具体地,VADv2基于MapTRv2从环视图像数据中提取地图物理层和逻辑层的map tokens,同时从图像中提取关于动态障碍物的agent tokens和交通信号灯的traffic element tokens。此外,由于在连续的动作空间上学习概率分布较为困难,VADv2将动作空间离散化,通过最远轨迹采样的方式从真实的轨迹数据中筛选出N条轨迹构建轨迹集合,用于表征整个动作空间。VADv2将轨迹通过正余弦编码方式编码为planning tokens。planning tokens基于堆叠的Transformer结构与包含环境信息的tokens交互,同时结合稀疏导航信息和自车状态信息,输出每一条轨迹的概率:
p ( a ) = M L P ( T r a n s f o r m e r ( E ( a ) , E e n v ) + E n a v i + E s t a t e ) p(a) = {\rm MLP (\rm Transformer}(E(a), E_{\rm env}) + E_{\rm navi} + E_{\rm state}) p(a)=</
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 536
536

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









