









24年3月谷歌deepmind的论文“RT-H: Action Hierarchies Using Language”。
语言提供了一种将复杂概念分解为易于理解片段的方法。最近在机器人模仿学习方面的工作,提出了学习语言条件策略,该策略在给定视觉观察和语言中指定的高级任务情况下预测动作。在多任务数据集中,这些方法利用自然语言在结构语义相似的任务(例如,“pick coke can”和“pick an apple”)之间共享数据。然而,随着任务在语义上变得更加多样化(例如,“pick coke can”和“pour cup”),任务之间的数据共享变得更加困难,因此学习将高级任务映射到行动需要更多的演示数据。
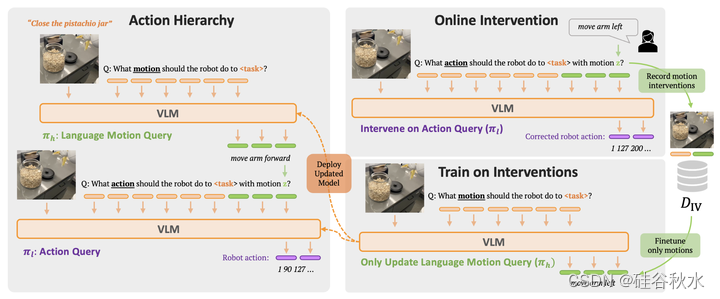
为了弥合任务和动作之间的差距,一个见解是教机器人动作的语言,用更精细的短语来描述低级别的动作,比如“向前移动手臂”或“闭合抓手”。将这些语言动作预测为高级任务和行动之间的中间步骤,迫使策略在看似不同的任务中学习低级动作的共享结构。此外,以语言动作为条件的策略可以在执行过程中通过人类指定的语言动作轻松地进行校正。
这为灵活的政策提供了一种新的范式,可以从人类对语言的干预中学习。RT-H使用语言动作建立了一个动作分层:它首先学习预测语言动作,并以此为条件,结合高级任务,然后在所有阶段使用视觉上下文预测动作。实验表明,RT-H利用这种语言动作分层结构,有效地利用多任务数据集,学习更鲁棒、更灵活的策略。
RT-H如图所示,有两个关键阶段:它首先从任务描述和视觉观察中预测语言运动(语言运动查询,见左上图),然后对预测的语言运动、任务和观察进行条件设置,推断精确的动作(动作查询,见左下图)。用VLM主干实例化RT-H,并遵循RT-2[4]中的训练过程。与RT-2类似,通过联合训练,利用互联网规模数据中自然语言和图像处理方面的巨大先验知识。为了将这些先验知识纳入动作分层,单个模型学习同时语言动作和动作查询。
从预训练的检查点开始,如RT-2相同,采用PaLI-X训练混合[52],对RT-H进行联合训练。ViT编码器被冻结用于此联合训练。RT-H以相同的采样率用语言运动和动作查询替换RT-2中的动作预测查询。使用单个模型简化训练过程,并使语言动作和动作查询从PaLI-X训练混合的广泛先验知识中受益。
为了在每一集的每个时间步长廉价地提取可靠的语言动作z,作者开发了一种依赖于机器人本体感觉(proprioception)信息的自动标注方案。首先,将机器人末端执行器姿势变化的每个维度连接到一个空间维度(例如,位置变化的z轴映射为上和下)。对所有9个动作维度(delta位置的3个维度,delta方向的3个维度,基座移动的2个维度,以及夹具的1个维度)进行此操作,确定一组机器人当前的主要空间运动,例如“向上和向右移动臂”、“闭合夹具”、“逆时针旋转臂”或“向左转动基座”。然后,可以过滤出低于所选“小动作”阈值的维度,然后按照动作幅度的顺序组合所产生的动作。例如,如果机器人主要向前移动手臂,但也开始闭合夹持器,将提取“向前移动手臂并闭合夹持器”。通过这种方式,语言的组合性从一组简单的已知运动中提取2500多个语言运动。此外,由于这些语言运动直接来源于动作,因此在RT-H中运行动作查询时,对动作本身具有很高的预测能力。重要的是,无论任务如何,都会为所有实验和数据集固定此过程的细节,因此设计此过程对开发人员来说是一次性的固定成本。
在测试时,RT-H首先运行语言动作查询来推断技能,然后在动作查询中使用该推断的技能来计算动作。但是,由于两个查询必须在每个时间步长按顺序运行,因此此过程会使推理时间翻倍。虽然对于较小的模型来说不是问题,但对于较大的模型(如RT-H中使用的55B模型大小),将经历不可避免的查询滞后。为了应对这一挑战,有两种语言运动推理模式:(1)异步查询:只在RT-H中训练语言运动查询,预测未来的技能。然后在测试时,用上一个时间步长的推断语言运动来查询动作,同时还预测下一个时间步骤的语言运动。这能够对查询进行批处理,从而实现与RT-2几乎相同的查询滞后。(2) 固定频率:可以每H步评估一次技能查询,也减少了分期滞后。在实验中,选择异步查询,因为技能通常需要在精确的时间步长进行更改,而这些时间步长可能与固定频率不一致。
还可以显示当前预测的语言运动,以提高透明度,并为用户提供额外的上下文,这样他们就知道机器人计划做什么,并可以更好地选择他们的更正。然后,在固定频率下,要求用户输入新的语言动作校正,继续运行之前输入的语言动作校正法,或者退出校正模式。固定频率请求,为用户提供了更新校正或决定让模型再次接管的时间。















 1034
1034











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









