










23年11月来自KIT的论文“MUVO: A Multimodal Generative World Model for Autonomous Driving with Geometric Representations“。
学习无人监督的自动驾驶世界模型有可能显著提高当今系统的推理能力。然而,大多数工作忽略了世界的物理属性,只关注传感器数据。提出MUVO,一个具有几何体素表示的多模态世界模型。用原始相机和激光雷达数据来学习传感器不可知的世界几何表示,可以直接用于下游任务,如规划。在多模态的未来预测,几何表示改进了相机图像和激光雷达点云的预测质量。
该模型以动作为条件,利用自动驾驶汽车的高分辨率图像和激光雷达传感器数据,来预测原始相机和激光雷达数据,以及未来多步的3D占用率表示。MUVO模型由三个阶段组成,如图所示。首先,用基于Transformer的架构处理、编码和融合高分辨率RGB相机数据和激光雷达点云。其次,将传感器数据的潜表示提供给转换模型,导出当前状态的概率模型,然后进行采样,同时预测未来状态的概率模型并从中进行采样。最后,从概率模型中解码当前和未来状态,预测多帧的原始RGB图像、点云以及未来的3D占用网格。
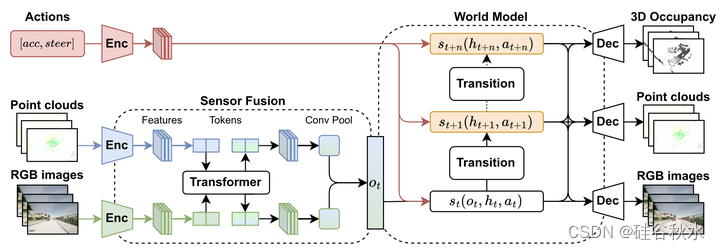
先前的世界模型主要学习数据中的模式,而不是对真实世界进行建模[97]。MUVO无监督方法,学习传感器无关的几何占用表示,为模型提供了对物理世界的根本理解。















 2000
2000

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









