









23年10月来自香港大学、浙江大学、华为和悉尼大学的论文“DRIVEGPT4: INTERPRETABLE END-TO-END AUTONOMOUS DRIVING VIA LARGE LANGUAGE MODEL“。
过去的十年自动驾驶在学术界和工业界都得到了快速发展。然而,其有限的可解释性仍然是一个悬而未决的重大问题,严重阻碍了自动驾驶汽车的商业化和进一步发展。以前用小语言模型的方法,由于缺乏灵活性、泛化能力和鲁棒性而未能解决这个问题。最近,多模态大语言模型(LLM)因其通过文本处理和推理非文本数据(如图像和视频)的能力而受到研究界的极大关注。本文介绍DriveGPT4,一个利用LLM可解释的端到端自动驾驶系统。DriveGPT4能够解释车辆动作并提供相应的推理,以及回答人类用户提出的各种问题,增强交互。此外,DriveGPT4以端到端的方式预测车辆低级控制信号。这些功能源于专门为自动驾驶设计定制的视觉指令调整数据集。DriveGPT4可以以零样本的方式进行推广,适应更多未见的场景。
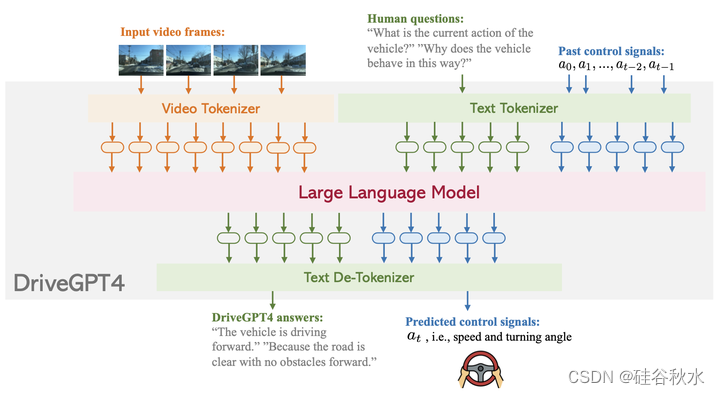
视频和标签是从BDD-X数据集(Kim 2018)中收集的,该数据集包含约20000个样本,包括16803个用于训练的片段和2123个用于测试的片段。每个剪辑被采样为8个图像。此外,它还提供每帧的控制信号数据(例如,车辆速度和车辆转弯角度)。BDD-X为每个视频剪辑提供了关于车辆动作描述和动作理由的文本注释。如图是DriveGPT4概述:DriveGPT4是一个综合的多模态语言模型,能够处理包括视频、文本和控制信号在内的输入。视频序列使用专用视频token化模块进行token化,而文本和控制信号共享一个token化模块。在token化之后,高级语言模型可以同时生成对人类查询的响应,并预测下一步的控制信号。
在以前的工作中,ADAPT(Jin 2023)训练字幕网络来预测描述和理由。但是,提供的描述和正确标签是固定的和刚性的。如果人类用户希望了解更多关于车辆的信息并提出日常问题,那么过去的工作可能会功亏一篑。因此,仅BDD-X不足以满足可解释自动驾驶的要求。
由ChatGPT/GPT4生成的指令调优数据已被证明在自然语言处理(Peng 2023)、图像理解(Liu 2021)和视频理解(Li 2020 3c;Zhang 2023)中对性能增强是有效的。ChatGPT/GPT4可以访问特许信息(例如,图像标记的字幕、真实边框),并被提示生成对话、描述和推理。目前,还没有为自动驾驶定制的视觉指令听从数据集。作者在ChatGPT的辅助下,基于BDD-X创建了自己的数据集。
由于BDD-X为每个视频片段提供了车辆动作描述、动作理由和控制信号序列标签,因此直接用ChatGPT基于这些标签生成一组三轮问答(QA)。
首先,创建三个问题集:Qa、Qj和Qc。
Qa包含相当于“该车当前的行动是什么?”的问题。随机选择的问题qa与动作描述标签形成qa对。
Qj包含相当于“为什么车会有这种行为?”的问题。一个随机选择的问题qj与动作正确标签形成一个QA对。
Qc包含相当于“预测下一帧车的速度和转弯角度”的问题。随机选择的问题Qc与控制信号标签形成QA对。
LLM可以学习同时预测和解释车辆动作。但是,如前所述,这些QA对,具有固定和严格的格式。由于缺乏多样性,仅对这些QA进行训练会降低LLM的推理能力,会无法回答其他形式的问题。
为了解决上述问题,ChatGPT被用作教师,产生更多关于自车的对话。提示通常遵循LLaVA中使用的提示设计。为了使ChatGPT能够“看到”视频,采用YOLOv8(Reis2023)检测视频每帧中常见的目标(例如,车辆、行人)。所获得的边框坐标被标准化并作为特许信息发送到ChatGPT。除了目标检测结果外,ChatGPT还可以访问视频剪辑的真值控制信号序列和字幕。基于这些特许信息,ChatGPT会被提示生成关于自车、红绿灯、转弯方向、变道、周围目标、目标之间的空间关系等多轮多类型的对话。
最后,收集了28K的视频文本指令如下样本,包括由ChatGPT生成的16K固定QA和12K对话。生成的示例如表所示:上半部展示了YOLOv8获得的输入信息,包括视频字幕、控制信号和目标检测结果。下半部显示生成的固定QA和ChatGPT生成的对话。

DriveGPT4是一款多功能多模态LLM,能够处理各种输入类型,包括视频、文本和控制信号。视频被均匀地采样到固定数量的图像中,并用基于Valley的视频token化模块(Luo 2023)将视频帧转换为文本域token。从RT-2(Brohan2023)中汲取灵感,文本和控制信号使用相同的文本token化模块,这意味着控制信号可以被解释为一种语言,并被LLM有效地理解和处理。所有生成的tokens都被连接起来并输入到LLM中。本文采用LLaMA 2(Touvron2023b)作为LLM。在生成预测的token后,去token化模块对其进行解码恢复人类语言。解码文本包含固定格式的预测信号。
对于每个视频帧Ii,用预训练的CLIP视觉编码器(Radford 2021)提取其特征Fi。Fi的第一个通道表示视频帧Ii的全局特征,而其他256个通道对应于Ii的图像补丁特征。为了简洁地表示,Ii的全局特征表示为Fi-G,而Ii的局部补丁特征表示为Fi-P。最终,一个投影器将视频的时间特征T和空间特征S都投影到文本域中。如图所示是视频token化模块的架构:
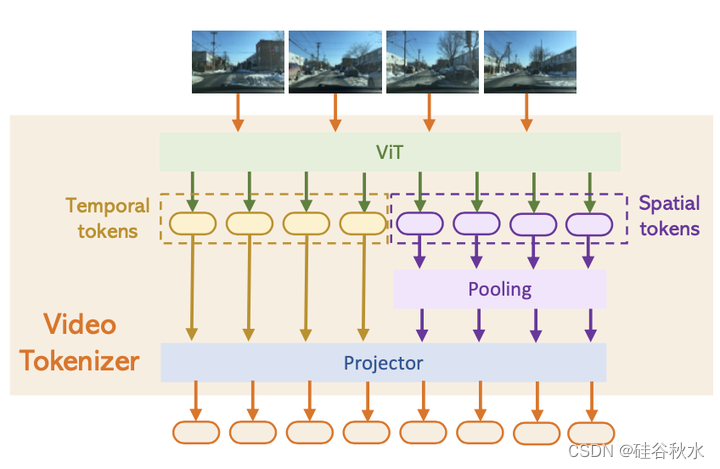
受RT-2(Brohan2023)的启发,控制信号的处理类似于文本,因为它们属于同一域空间。控制信号直接嵌入文本中进行提示,并使用默认的LLaMAtoken化模块。本研究中自车的速度v=[v1,v2,…,vN]和转向角∆=[∆1,∆2,…,∆N]被视为目标控制信号。转向角度表示当前帧和初始帧之间的相对角度。在获得预测的token后,LLaMAtoken化模块将token解码回文本。DriveGPT4预测后续步骤的控制信号,即(vN+1,∆N+1)。预测的控制信号使用一个固定格式嵌入输出文本中,通过简单的后处理可以轻松提取。如表给出了DriveGPT4的输入和输出示例。

与以往LLM相关研究一致,DriveGPT4的训练包括两个阶段:(1)预训练阶段,重点是视频文本对齐;以及(2)微调阶段,旨在训练LLM回答与端到端可解释自动驾驶相关的问题。
与LLaVA(Liu e2023)和Valley(Luo 2021)一致,该模型对来自CC3M数据集的593K个图像-文本对和来自WebVid-10M数据集的100K个视频-文本对进行了预训练(Bain2021)。预训练图像和视频包含各种主题,并不是专门为自动驾驶应用设计的。在此阶段,CLIP编码器和LLM权重保持固定。只有视频token化模块被训练将视频与文本对齐。
在微调阶段,DriveGPT4中的LLM与可解释的端到端自动驾驶的视觉token化模块一起进行训练。为了使DriveGPT4能够理解和处理域知识,用前面生成的28K视频文本指令进行训练。为了保持DriveGPT4回答日常问题的能力,还用了LLaVA生成的80K指令服从数据。因此,在微调阶段,DriveGPT4用28K视频文本指令服从数据以及80K图像文本指令服从数据进行训练。前者确保DriveGPT4可以应用于可解释的端到端自动驾驶,而后者增强了数据灵活性,有助于保持DriveGPT4的一般问答能力。

















 1766
1766

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









