










23年11月来自Waabi创业公司的论文"Learning Unsupervised World Models For Autonomous Driving Via Discrete Diffusion"。
学习世界模型可以教会智体理解世界是如何运作的。尽管它可以被视为序列建模的一种特殊情况,但在自动驾驶等机器人应用程序上,规模化世界模型的进展比生成式预训练Transformer(GPT)规模化语言模型的速度要慢一些。主要原因是两个瓶颈:处理复杂和非结构化的观测空间,以及具有可扩展的生成模型。因此,本文提出了一种世界建模方法,首先用VQVAE方法token化传感器观测结果,然后通过离散扩散预测未来。为了有效地并行解码和去噪tokens,通过一些简单的更改将掩码生成式图像Transformer重新转换为离散扩散框架,从而获得显著的改进。当应用于点云观测上学习的世界模型时,其在NuScenes、KITTI Odometry和Argoverse2数据集中,1秒预测将先前的最先进Chamfer距离减少了65%以上,对于3秒预测,将之前的最先进Chamfer距离减少了50%以上。
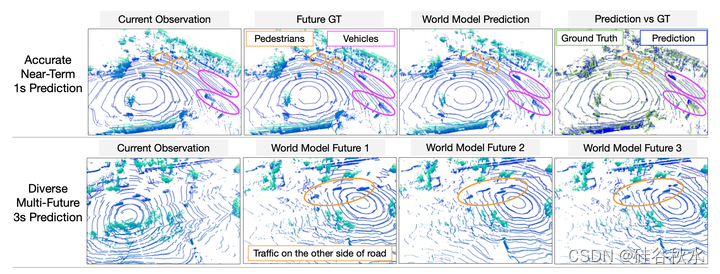
如图展示了世界模型,不仅能够在1s时间范围内做出准确的预测,而且还能够在3s时间范围内学习未来观测的多模态。结果验证了分析,即token化和离散扩散的结合可以释放在真实世界数据上规模化学习世界模型的可能性。
如图是方法概述:该方法首先用类似VQVAE的token化器去token化传感器观测,然后通过离散扩散预测未来。token化器将点云数据编码为BEV的离散延迟,并通过可微分深度渲染(differentiable depth rendering)进行重建。世界模型是对BEV数据tokens进行操作的离散扩散模型。
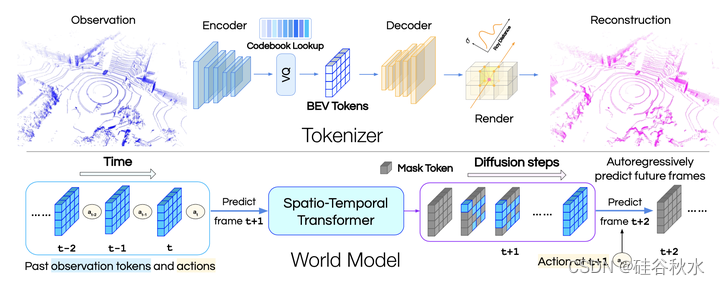
对于自主智体,环境可以被视为一个接收信息并输出下一个观察结果的黑匣子。世界模型是一种学习的生成模型,可以用来代替环境。世界模型是一个离散扩散模型(Austin 2021;Lezama 2023),能够在给定过去的观测和行动的情况下执行条件生成。将xk(t)表示为前向扩散步骤k的token化观测。k=0是原始数据分布,并且推理中步骤总数K可以是任意的。将推理过程概述如下:为了预测时间步t+1的观测,世界模型首先将过去的观测o(1)···o(t)token化为x(1)···x(t),对下一帧预测应用离散扩散,将最初完全掩码的xK(t+1)解码为完全解码的x0(t+1),然后将其传递到token化器的解码器中,渲染下一个观测o(t+1)。
作者提出了一种VQVAE(Van Den Oord 2017)类模型来token化由点云表示的3D世界(Xiong 2023)。该模型在BEV中学习潜代码,并通过可微分深度渲染进行训练以重建点云。
编码器使用基于点云的目标检测标准组件:首先,用PointNet聚合每个体素的逐点特征(Qi 2017);第二,将体素特征聚合为BEV pillar(Lang2019);最后,应用Swin Transformer主干网络(Liu 2021)获得从BEV的初始体素大小下采样1/8的特征图。编码器的输出,经过矢量量化层产生其预测。
掩码生成式图像Transformer,即MaskGIT(Chang2022),已被证明可用于各种应用。有趣的是,离散扩散模型,如D3PM(Austin 2021),尽管有一个更先进的原则性框架和工具箱,但尚未取得类似的成功。本文将MaskGIT改写为离散扩散模型,如下是算法伪代码:其中淡蓝色部分是原MaskGIT部分

然而,在自回归建模类似GPT的公式中,该模型总是能够在训练期间看到用于下一帧预测的所有过去的真值tokens。在机器人技术中,根据时间的离散化,世界可能只会在下一帧内逐渐变化;即使损失得到了很好的优化,学习只预测下一次观测也不一定会产生长期推理能力。因此,训练世界模型应该超越下一次观测的预测,而是在给定过去的情况下预测未来观测的整个片段。因此,将世界模型设计为类似于BERT的时-空版本,在时间维度上具有因果掩码。未来的预测是通过掩码、填充和进一步去噪来完成的。单独帧建模对于无分类器扩散引导模型是必要的;在训练期间,要优化的目标在每次迭代时随机采样。该模型采用混合的目标进行训练(如图所示):
50%的时间,以过去为条件,未来去噪。
40%的时间,共同过去和未来去噪。
10%的时间,单独每帧去噪,无论过去还是将来。
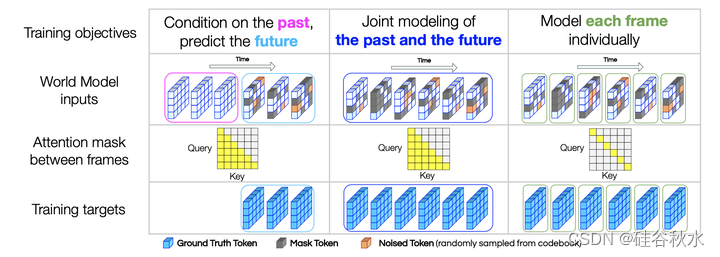
第一个目标是关于未来的预测;第二个目标也有一个未来预测组件,但联合建模未来和过去,带来更难的预训练任务;第三个目标是学习一个无条件的生成模型,这是在推理过程中应用无分类器扩散引导模型所必需的。
关于去噪,参考上面的算法1,其中部分输入首先被掩码和加噪,并且模型学习以交叉熵损失重建原始输入。在推理过程中,仍然在一次自回归中预测一帧。无分类器扩散引导的算法2对每个帧进行采样。在每个时间步t,扩散引导中的上下文是c(t−1),即智体过去观测和动作的历史。
世界模型的架构是一个时空Transformer,它只是将空间注意和时间注意交织在一起。为了获得空间注意,在每个单独帧上使用Swin Transformer(Liu 2021)。对于时间注意,用GPT-2块(Radford2019)来跨时间关注相同的特征位置。
用U-Net(Ronneberger 2015)结构,将三级特征与残差连接相结合,并以初始输入相同的分辨率进行预测。本文案例中,动作是自车的姿势,在被压平并经过两个中间带LayerNorm(Ba 2016)的线性层之后,添加到每个特征级的开头,对应于观察结果。
时间注意掩码,在训练和推理中都起着至关重要的作用。在训练期间,当优化前两种类型的目标时,因果掩码应用于所有时间Transformer块;当优化第三类目标学习无条件生成模型时,时间注意掩码变成了一个单位矩阵,使得每个帧只能关注本身。
在推理过程中,模型一次对一帧进行解码和去噪;将时间序列长度增加1,并将注意掩码设置为前一序列长度内的因果掩码和最后一帧的身份掩码,可以有效地实现无分类器扩散引导模型,从而使添加的帧成为无条件的生成结果。















 2047
2047

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









