









23年9月来自上海AI实验室、华东师大和香港中文大学的论文“DiLu: A Knowledge-Driven Approach To Autonomous Driving With Large Language Models“。
自动驾驶的最新进展依赖于数据驱动的方法,但面临着包括数据集偏差、过拟合和不可解释性在内的挑战。从人类驾驶的知识驱动本质中汲取灵感,这里探索了如何向自动驾驶系统灌输类似能力的问题,并总结了一种集成了交互环境、驾驶员智体和记忆组件的范式来解决这个问题。利用具有涌现能力的大语言模型(LLM),提出DiLu框架,该框架结合了推理(Reasoning)模块和反思(Reflection)模块,使系统能够基于常识知识进行决策并不断发展。大量实验证明了DiLu积累经验的能力,与基于强化学习的方法相比,DiLu在泛化能力方面也具有显著优势。此外,DiLu能够直接从真实世界的数据集中获取经验,这突出了其在实际自动驾驶系统中部署的潜力。
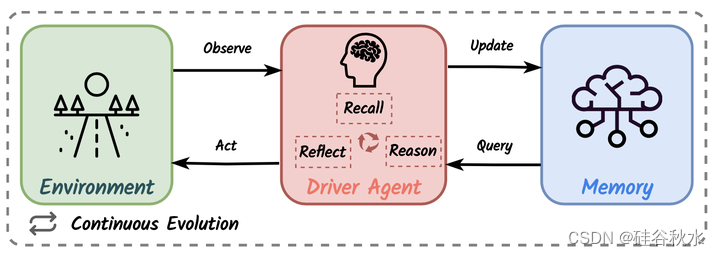
如图所示,自动驾驶系统的知识驱动范式,包括互动环境、具有回忆、推理和反思能力的驾驶员智体,以及独立的记忆模块。驾驶员智体不断进化,观察环境、查询、更新记忆模块中的体验,并做出控制自车的决策。
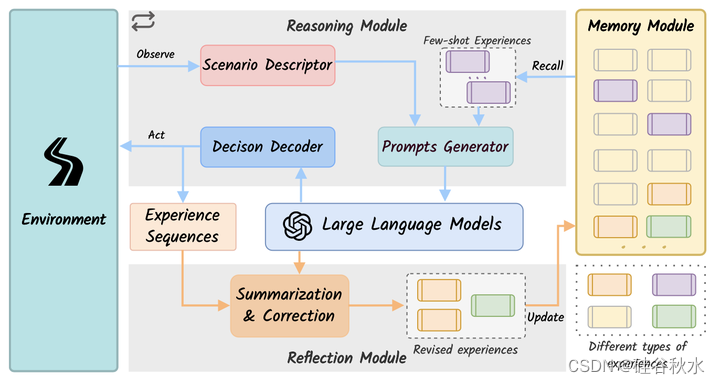
如图是DiLu框架。它由四个模块组成:环境、推理、反思和记忆。在DiLu中,推理模块可以观察环境,结合记忆模块中的场景描述和经验生成提示,并解码LLM的响应以完成决策。同时,反思模块评估这些决策,识别对体验的不安全决策,并最终将修改后的体验更新到记忆模块中。
如果没有少样本的经验,开箱即用的LLM在处理复杂的闭环驾驶任务时无法执行精确的推理。因此,用记忆模块来存储过去驾驶场景中的经验,包括决策提示、推理过程和其他有价值的信息。与人类驾驶员类似,智体应根据推理过程和之前遇到的类似驾驶情况做出决定。为了检索过去的场景,将文本场景描述转换为向量,作为衡量记忆模块中相似性的关键,该模块由向量数据库构建(Johnson 2019)。记忆模块使LLM具备记忆和回忆驾驶体验的能力。然而,与人类在开始驾驶之前需要驾校的基础驾驶知识类似,需要在初始化记忆模块时向LLM教授基本的决策过程。为了确保记忆模块中知识的一致性,采用了“少样本”的方法来教授LLM这一基本决策过程。这涉及到人类首先建立一个基于场景描述的综合决策过程。然后将这些进程作为“少样本”添加到记忆模块中,从而完成其初始化。
如图推理模块:利用LLM的常识知识,从记忆模块中查询经验,根据场景观察做出决策。
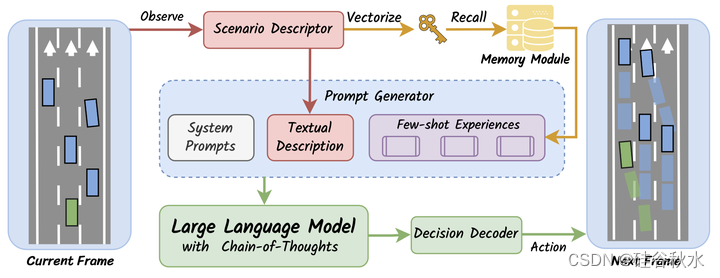
具体来说,推理过程包括以下过程:(1)通过描述符对场景进行编码;(2) 回忆记忆模块的一些经验;(3) 生成提示;(4) 将提示馈送到LLM中;(5) 从LLM的响应解码动作。
通过描述符对场景进行编码。为了便于DiLu理解当前的交通状况,场景描述符将当前的场景数据转录为描述性文本。如图(a)所示,场景描述符遵循标准的句子结构,并利用自然语言对正在进行的驾驶场景进行全面描述。该描述包含静态道路细节以及关于场景中自车和周围车辆的动态信息。然后,这些生成的描述用作提示生成器的输入,并被用作从记忆模块获取相关少样本体验的keys。注:图(b)是LLM推理的输出去解码动作。

回忆记忆模块的一些经验。在推理过程中,当前驾驶场景的描述也嵌入到向量中。然后,该向量用于在记忆模块内启动相似性查询,搜索前k个相似情况。由此产生的成对场景描述和推理过程集合为少样本体验,然后将其集成到提示生成器中。
生成提示。每帧提示由三个关键组件组成,即系统提示、场景描述符中的文本描述和少样本体验。在系统提示中,对闭环驾驶任务进行了简要概述,其中包括对任务输入和输出内容和格式的介绍,以及控制推理过程的约束。在每个决策框架中,都会根据当前的驾驶场景构建个性化提示。LLM随后使用这些提示进行推理并确定当前帧的适当操作。
将提示输入LLM。由于闭环驾驶任务需要复杂的推理过程来做出正确的决策,采用了(Wei2023)引入的思维链(CoT)提示技术。这些技术要求LLM生成一系列描述逐步推理逻辑的句子,最终做出最终决定。采用这种方法是因为驾驶场景固有的复杂性和可变性,如果语言模型直接产生决策结果,可能会导致幻觉。此外,生成的推理过程有助于后续反思模块对错误决策的进一步细化和修改。
从LLM的响应解码动作。将提示输入LLM后,在动作解码器中解码最终决策,如上图(b)所示。动作解码器将LLM的决策结果转换为自车的动作,并向环境提供反馈。
通过重复上述过程,建立了一个由LLM驱动的闭环决策系统。
在推理模块中,用LLM在记忆模块的支持下执行闭环驾驶任务。作为下一步,希望在驾驶课程结束后积累宝贵的经验并丰富记忆模块。为了实现这一目标,在DiLu中提出了反思模块,该模块不断学习过去的驾驶经验。DiLu可以通过反思模块逐步提高性能,类似于新手成为经验丰富的驾驶员。
反思模块如图所示。在闭环驾驶任务中,根据驾驶场景记录用作输入的提示,以及LLM为每个决策帧生成的相应决策。驾驶会话结束后,获得一个决策序列,例如图中从0到4的5个决策帧。当会话结束时没有任何冲突或危险事件,表明会话成功时,DiLu继续从序列中采样几个关键决策帧。然后,这些框架直接成为历史驾驶体验的一部分,并丰富了记忆模块。
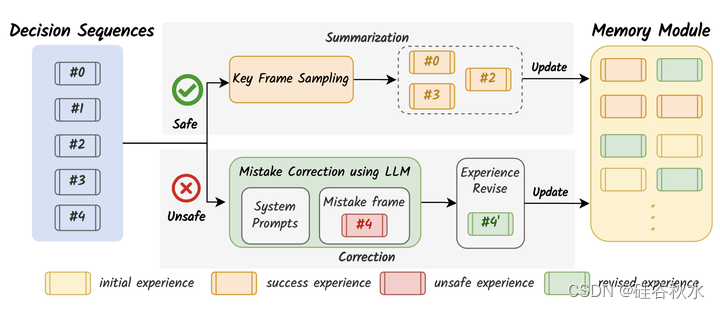
相反,如果当前会话因与其他车辆碰撞等危险情况而终止,则表明驾驶员智体做出了不准确的决定。对系统来说,纠正推理模块做出的不安全决策至关重要。得益于可解释的思维链,可以很容易地找到危险情况的原因。当然,可以请一位人类专家来完成这样的纠错过程。然而,系统目标是让自动驾驶系统从错误中吸取教训。LLM可以有效地起到纠错的作用。方法是用发生错误决策的驾驶场景,以及原始推理输出,作为LLM的提示。指示LLM找出错误决策背后的原因,并提供正确的决策。还要求LLM提出策略,以避免未来出现类似错误。最后,正确的推理过程和从错误中吸取的修正决策被保留在记忆模块中。
实验设置中,利用成熟的Highway-env作为模拟环境,这是自动驾驶和战术决策领域中广泛使用的平台(Leurent2018)。该环境提供了多种驾驶模式,并提供了一个逼真的多车辆交互环境。此外,环境中的车辆密度和车道数量可以自由调整。在DiLu框架中,采用的大型语言模型是OpenAI开发的GPT家族。GPT-3.5(OpenAI,2023a)用于框架工作的推理模块,负责为自车做出合理的决策。GPT-4被用于反思模块,因为与GPT-3.5相比,它已经证明了显著改进的自我修复和事实核查能力(Bubeck2023;Olausson2022)。为了作为DiLu框架中的记忆模块,采用了Chroma,一个开源的嵌入向量数据库。用OpenAI的text-embedding-ad-002模型将场景描述转换为向量。















 247
247

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









