










23年10月来自上海AI实验室、香港大学、浙江大学和中科大的论文“PonderV2: Pave the Way for 3D Foundataion Model with A Universal Pre-training Paradigm“。
与众多的NLP和2D计算机视觉基础模型相比,学习一个稳健且高度通用的3D基础模型带来了更大的挑战。这主要是由于其固有的数据易变性和下游任务的多样性。本文介绍了一个全面的3D预训练框架,旨在促进高效的3D表示获取,从而建立一条通往3D基础模型的途径。基于信息丰富的3D特征,应该能够对丰富的几何形状和外观线索进行编码,用来渲染逼真的图像。受此鼓舞,本文提出一种通用范式,通过可微分的神经渲染学习点云表示,作为3D和2D世界之间的桥梁。
将渲染图像与真实图像进行比较,在设计的体神经渲染器中训练点云编码器。值得注意的是,该方法展示了如何将学习的3D编码器无缝集成到各种下游任务中。这些任务不仅包括3D检测和分割等高级别挑战,还包括3D重建和图像合成等低级目标,涵盖室内和室外场景。此外,所提出的通用方法可对2D主干进行预训练,大大超过了传统的预训练方法。
如图是统一3D预训练方法PonderV2(point cloud pre-training via neural rendering),也是以前PonderV1(论文“Ponder: Point cloud pre-training via neural rendering“)的扩展;直接用RGB-D渲染图像的监督进行训练,用于各种室内或室外3D下游应用,例如3D目标检测、3D语义分割、3D场景重建和图像合成等。
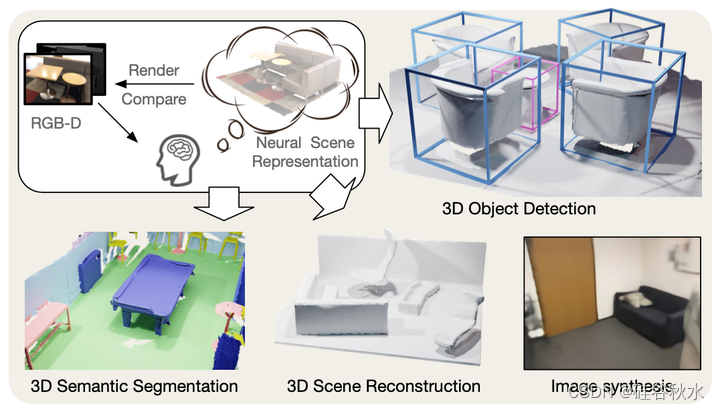
如图是PonderV2的整体流水线。以由多帧RGB-D图像、场景扫描和激光雷达等构建的原始点云为例,首先应用掩码和网格采样等增强来获得量化的稀疏张量。然后,用稀疏主干来提取稀疏特征,并作为未来要进行预训练和微调的编码器。然后,对稀疏特征进行致密化,并将其输入到浅的致密卷积网络中,该网络给出了致密的特征体。接下来,渲染解码器从特征体中查询,并应用浅MLP来输出每个点的SDF(signed distance function)和颜色值。最后,SDF和颜色输出被集成,渲染2D RGB-D图像,该图像将由真值监督。
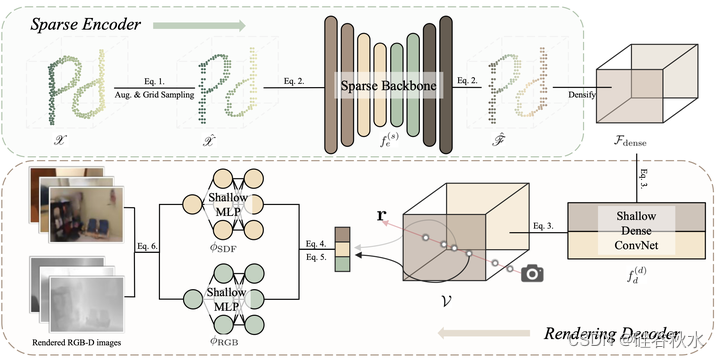
这里补充一下实验和训练细节。
首先对室内场景,实验分两种进行:一是输入多帧RGB-D,一是点云。
对于RGB-D输入版,用ScanNet[78]RGB-D图像作为预训练数据集。ScanNet是一个广泛使用的真实世界室内数据集,包含1500多个室内场景。每个场景都由RGB-D相机仔细扫描,总共产生约250万个RGB-D帧。用VoteNet[79]遵循相同的train/val分割。这部分还没有介绍语义渲染,其将在场景级别用作输入。
对于RGB-D输入的版本,采用RGB的3个输入通道,网格大小g=0.02^3。用96个通道将V致密化为64×64×64之后,采用输出通道数为128的致密UNet模型。在预训练期间,大小为8的小批量包括来自8个场景的点云。输入到稀疏主干的每个点云,都是从ScanNet原始视频的5个连续RGB-D帧按20帧间隔反向投影得到。这5个帧也被用作网络的监督。输入点云随机下采样到20000个点,并遵循Mask point[36]中使用的掩码策略。
用权重衰减为0.05的AdamW优化器[80]进行了100个epochs的训练。学习率初始化为1e−4,采用指数时间表。对于渲染过程,为每个图像随机选择128条射线,并为每条射线采样128个点。
对于点云输入版,希望预训练一个可以应用于各种下游任务的统一主干,上游和下游模型具有统一的输入和编码器阶段。 由于考虑效率,选择 SparseUNet [42] 作为 f(s),是 SpConv [103] 对 MinkUNet [42] 的优化实现,其输出特征有 96 个通道。 主要关注三个广泛认可的室内数据集:ScanNet [78]、S3DIS [104] 和 Structured3D [105] 来联合预训练权重。Point Prompt Training(PPT)[102] 建议为每个数据集提供自己的批量归一化层来解决这个问题。 考虑到其有效性和灵活性,将 PPT 与通用预训练范式结合起来,并将 PPT 作为基线。 值得注意的是,PPT 在下游任务中使用相同主干网(即 SparseUNet)实现了最先进的性能。
在预训练阶段之后,丢弃渲染解码器并加载编码器主干的权重用于下游任务,无论有或没有额外的特定任务头。 随后,网络对每个特定下游任务进行微调和评估。 主要评估语义分割的平均交集(mIoU)指标和实例分割/目标检测任务的平均精度(mAP)。
这时候实验基于Pointcept[106](一种用于点云感知研究的代码库)。所有PPT的超参数都是相同的,以便进行公平的比较。此设置的输入通道数为6,包含3个颜色通道和3个曲面法线通道。网格大小g=0.02^3。还应用了常见的变换,包括随机放弃(掩码比为0.8)、旋转、缩放、翻转等。
考虑到尽管轻量级解码器降低了渲染效果,但可能会提高下游性能,在加密后使用通道数为128微小的密集3D UNet。密集特征体V被配置为128个通道和128×128×32的大小。所有浅层MLP都有一个128大小的隐藏通道。对于语义监督,用“ViT-B/16”CLIP模型的文本编码器,其输出语义特征为512个通道。
在每个场景级输入点云中,首先对5个RGB-D帧进行采样进行监督,然后对每个帧采样128条射线。因此,在每次迭代中,每个点云总共监督128×5=640个像素值。值得注意的是,权重系数λC为1.0,λD设置为0.1。
用权重衰减为1e−4、动量为0.9的SGD优化器,做200epochs的训练。用1-周期调度器[107],学习率初始化为8e−4。对于渲染过程,为每个点云随机选择5帧,为每个图像随机选择128条射线,并为每个射线采样128个点。点云的批处理大小设置为64。模型在8个NVIDIA A100 GPU上进行训练。
再说对室外场景。
在NuScenes[111]数据集上进行了实验。700个用于训练的场景、150个用于验证的场景和150个用于测试的场景。每个场景都是通过六个不同的相机拍摄的,提供了具有周围视图的图像,并伴随着激光雷达的点云。该数据集具有多种标注,支持3D目标检测和3D语义分割等任务。对于检测评估,用nuScenes检测分数(NDS)和平均精度(mAP),对于分割评估,采用联合平均交集(mIoU)。
代码基于MMDetection3D[112]工具包,并在4个NVIDIA A100 GPU上训练所有模型。输入图像被配置为1600×900像素,而点云体素化的体素维度g为[0.075,0.075,0.2]。在预训练阶段,实现了几种数据增强策略,如随机缩放和旋转。此外,部分屏蔽输入,只关注可见区域进行特征提取。图像的掩码大小和比率分别配置为32和0.3,点的掩码尺寸和比率分别设置为8和0.8。对于分割任务,用SparseUNet作为稀疏主干,对于检测任务,用VoxelNet[113]作为主干,它类似于SparseUNet的编码器部分。对于多图像设置,用ConvNeXt-small[114]作为特征提取器fe。构造形状为180×180×5的均匀体素表示V。这里的f(d)是3核大小的卷积,用作将V特征维度减小到32的特征投影层。对于渲染解码器,对φSDF使用6层MLP,对φRGB使用4层MLP。在渲染阶段,每个图像视图随机选择512条光线,每个光线随机选择96个点。将λRGB和λ深度的损失比例因子保持为10。该模型使用AdamW优化器进行了12个epochs的训练,点和图像模态的初始学习率分别为2e−5和1e−4。在消融研究中,除非明确说明,否则在没有实施CBGS[115]策略的情况下,对50%的图像数据进行12个epochs的微调,对20%的点数据进行20个epochs的调优。















 1398
1398











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









