









20年1月OpenAI关于规模化定律的经典论文“Scaling Laws for Neural Language Models”。
该工作研究交叉熵损失下语言模型性能的经验规模化定律。损失以幂律的形式随模型大小、数据集大小和用于训练的计算量而规模化,有些趋势跨越了七个数量级以上。网络宽度或深度等其他架构细节在大范围内影响最小。简单的方程,控制过拟合对模型/数据集大小的依赖,以及训练速度对模型大小的依赖。这些关系,能够确定固定计算预算的最佳分配。较大的模型明显是样本高效的,因此计算高效的优化训练,包括了在相对少量的数据上训练非常大的模型,以及在收敛之前尽快停止。
模型性能强烈依赖于规模,弱依赖于模型形状:规模由三个因素组成:模型参数的数量N(不包括嵌入)、数据集的大小D和用于训练的计算量C。在合理的范围内,性能对其他架构超参数(如深度与宽度)的依赖性非常弱。
平滑幂律:性能与三个比例因子N、D、C中的每一个都有幂律关系,不受其他两个比例因子的制约,趋势跨越六个数量级以上。在高端市场没有观察到偏离这些趋势的迹象,尽管在达到零损失之前,性能必须最终趋于平稳。
过拟合的普遍性:只要同时放大N和D,性能就会得到可预测的改善,但如果N或D保持不变,而其中另一个增加,则会进入回跌的状态。性能惩罚可预测地取决于比率N^0.74/D,这意味着每次将模型大小增加8倍时,只需要将数据增加大约5倍就可以避免惩罚。
训练的普遍性:训练曲线遵循可预测的幂律,其参数大致与模型大小无关。通过推断训练曲线的早期部分,可以大致预测训练更长时间会造成的损失。
迁移随测试性能的提高而提高:当在与训练时分布不同的文本上评估模型时,其结果与验证集上的密切相关,损失的偏移量大致恒定——换句话说,迁移到不同的分布会导致持续的惩罚,但在其他方面会随训练集的性能而大致提高。
样本效率:大型模型比小型模型更具样本效率,通过更少的优化步骤和更少的数据点达到相同的性能水平。
收敛效率低下:在固定的计算预算C内工作时,但对模型大小N或可用数据D没有任何其他限制,训练非常大的模型并在收敛不足的情况下停止,可获得最佳性能。因此,最大计算效率的训练,将比基于训练小模型去收敛的预期更具样本效率,数据需求随训练计算增长非常缓慢,即D~C^0.27。
最佳批量大小:训练这些模型的理想批量大小大致仅为损失的一个幂,并且仍然可以通过测量梯度噪声尺度来确定[MKAT18];对可以训练的最大模型,收敛状态大约取100-200万个token。
总之,这些结果表明,当适当地扩大模型大小、数据和计算时,语言建模性能会得到平滑和可预测的提高。预计较大的语言模型将比当前模型表现更好,样本效率更高。
下面给出一些细节的说明。
当性能仅受非嵌入参数数量N、数据集大小D或最佳分配的计算预算Cmin所限制时,可以使用幂律来预测训练自回归模型语言的Transformer测试损失。存在单一方程,其控制对N和D的同时依赖性并支配过拟合的程度:
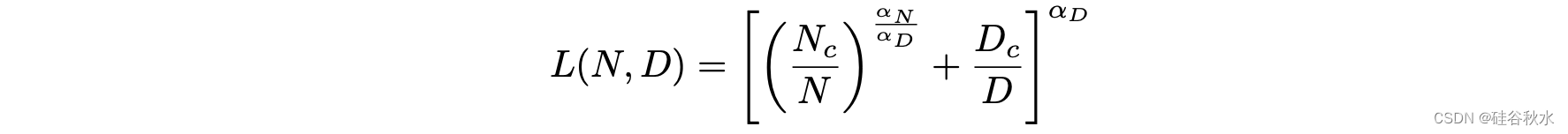
当训练一个给定模型对无限数据中的有限数量参数更新步骤S,学习曲线在初始过渡期之后可以拟合为
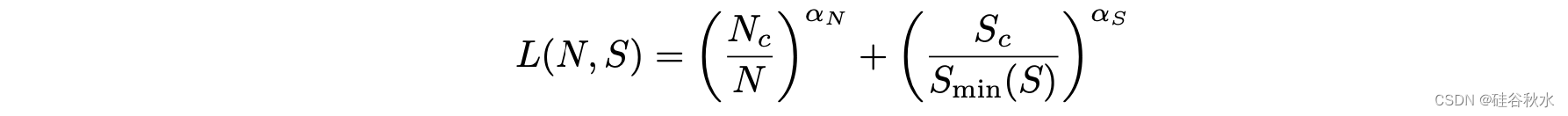
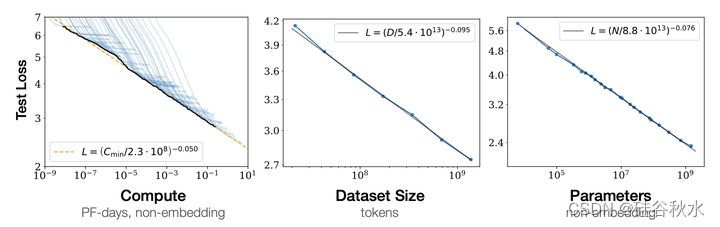
如图所示:随着模型大小、数据集大小和用于训练计算量的增加,语言建模性能会顺利提高。为了获得最佳性能,必须同时放大所有三个因素。当不受其他两个因素的制约时,经验的性能与每个单独的因素都存在幂律关系。
如图所示:随着越来越多的计算资源可用,可以选择分配多大的资源用于训练更大的模型、使用更大的批次和训练更多的步骤;该图用10亿倍的计算量增加来说明这一点。为了计算效率得到优化的训练,大部分计算的增加应该用于增加模型大小。相对较小的数据量增加是用来避免复用。在数据量的增加中,大多数都可以用于通过更大的批量来提高并行性,串行训练时间的增加是很小的。
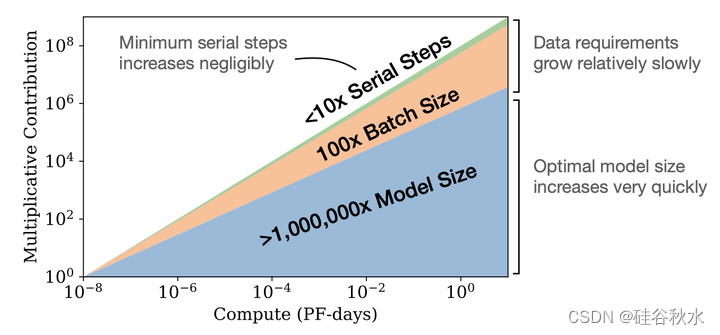
计算预算C的增加,应该主要用于更大的模型,而不会显著增加训练时间或数据集大小。这也意味着,随着模型越来越大,它们的样本效率也越来越高。在实践中,由于硬件限制,研究人员通常训练较小模型的时间比计算效率最高的时间要长。最佳性能取决于满足幂律的总计算量。
注明:超参数 如nlayer(层数)、dmodel(残差流的维度)、dff(中间前馈层的维度),dattn(注意模块输出的维度)和nhead(每层注意头的数量)参数化Transformer架构。在输入上下文中包括nctx token,一般设定nctx=1024。模型大小的计算如下

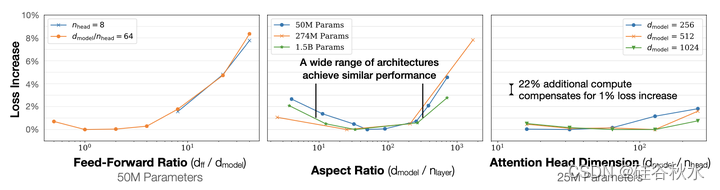
当固定总的非嵌入参数计数N时,Transformer性能对形状参数nlayer、nhead和dff的依赖性非常弱。为了建立这些结果,在改变单个超参数的同时,作者训练了具有固定大小的模型。这对于nhead来说是最简单的。当改变N层时,同时改变了dmodel,并保持N不变。类似地,为了在固定的模型大小下改变dff,还根据下表中的参数计数要求,同时改变了dmodel参数。

如果较深的Transformer表现为一组较浅模型有效的集成,那么nlayer的独立性将随之而来,正如ResNets所建议的那样。结果如图所示:当非嵌入参数的总数N保持固定时,其性能非常温和地依赖于模型形状;在各种形状的情况下,损失变化仅为百分之几;L(N)的拟合作为基线,可补偿参数计数中的小差异;横纵比尤其可以变化40倍,却仅轻微影响其性能;(nlayer,dmodel)=(64288)的损失,仅仅是在[RWC+19]中(481600)个模型的3%以内。
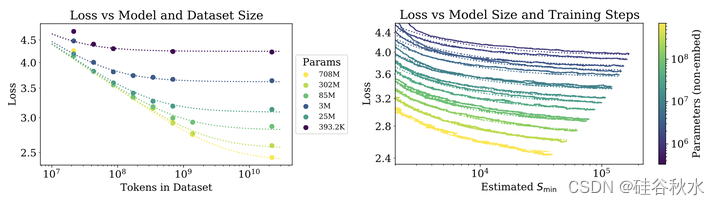
如图所示:左图显示早期停止的测试损失L(N,D)随数据大小D和模型大小N可预测地变化。右图显示在初始过渡期之后,所有模型大小N的学习曲线都可以拟合,其根据Smin(在大批量下训练时的最少优化步数)参数化。















 826
826











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









