










23年5月来自德国 Saarland University、英国剑桥大学、以色列Bar-Ilan University、美国西雅图的AI2和华盛顿大学的论文“Few-shot Fine-tuning vs. In-context Learning: A Fair Comparison and Evaluation“。
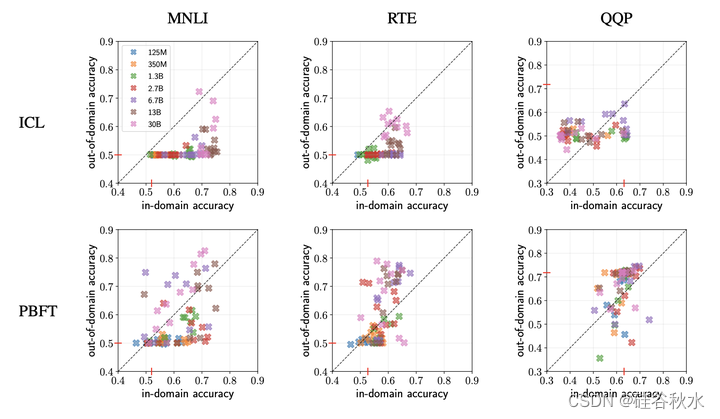
小样本(FS)微调(FT)和上下文学习(ICL)是预训练语言模型任务适应的两种替代策略。 最近,上下文学习由于其简单性和改进的域外泛化能力而显得比微调方法更受欢迎,而且大量证据表明微调模型会发现虚假相关性。 不幸的是,之前对这两种方法的比较是用不同大小的模型进行的。 这就提出了一个问题:所观察的微调模型域外泛化较弱,是微调的固有属性还是实验设置的限制? 本文比较了小样本微调和上下文学习对挑战数据集的泛化,同时控制了所使用的模型、示例数量和参数量(范围从 125M 到 30B)。 结果表明,经过微调的语言模型实际上可以很好地进行域外泛化。 这两种方法具有相似的泛化性; 它们出现很大波动,并且依赖于模型大小和示例数量等属性,这说明强大的任务适应仍然是一个挑战。
作者通过FT和ICL对任务适应进行了公平的比较,重点关注域内和OOD的泛化。其使用相同的模型在少样本设置中进行比较。
域内泛化。通过测量每个数据的验证集准确性来衡量域内泛化。这是分析工作中常见的做法,在以前的工作中也被使用(Utama 2021; Bandel2022)。
域外泛化。考虑协变漂移(covariate shift)下的OOD泛化(Hupkes 2022)。具体而言,专注于挑战数据集的泛化,旨在测试模型是否采用特定的启发式方法,或在推理过程中基于虚假相关性进行预测(McCoy2019;Elazar2021)。
模型。用7个不同的OPT模型(Zhang 2022)进行所有实验,参数范围从1.25亿到300亿,所有这些模型都是在相同的数据上训练的。这样能够研究模型大小对性能的影响,而不会混淆使用不同的训练数据。
任务和数据集。关注英语中的两个分类任务:自然语言推理(NLI)和释义(paraphrase)识别。对于NLI,用MNLI(Williams 2018)和RTE(Dagan 2006)作为域内数据集,并评估HANS((Heuristic Analysis for NLI Systems)词汇重叠子集上的OOD泛化(McCoy 2019)。删除中性例子对MNLI进行二值化,这样能够更好地将MNLI与RTE(只有两个标签)进行比较。为了进行释义识别,对QQP(Quora Question Pairs dataset)进行训练(Sharma 2019),并对PAWS(Paraphrase Adversaries from Word Scrambling)-QQP的OOD泛化进行了评估(Zhang 2017)。鉴于QQP验证集的规模很大(超过300k个例子),随机选择1000个验证例子。
少样本设置。对两种方法都遵循相同的程序。从给定数据集的域内训练集中随机抽取n∈{2,16,32,64128}个例子(除非另有说明)。由于这两种方法对所使用的模式以及ICL中演示的顺序都很敏感(Webson&Pavlick2022;Lu2022),为前面说的每个n抽取了10组不同的例子。还对3种不同的模式进行实验,得出每个n运行30次和自适应方法。
FT设置。用最小模式执行少样本PBFT(Logan IV2022),这只是在每个示例的末尾添加一个问号。对于NLI言语者,用Yes和No,将其分别映射到任务的标签“包含”和“不包含”。对于QQP,还使用“是”和“否”,并将它们映射为不重复和重复。遵循(Mosbach2021)建议,并用10e−5的学习率对40个epochs的所有模型进行微调,该学习率在前10%的训练步骤中线性增加(预热),之后保持不变。
ICL设置。给定OPT(“OPT: Open Pre-trained Transformer Language Models”)固定的上下文大小为2048个tokens,用于演示的示例数量方面会受到限制。主要实验集中在16个演示上,但也用2个和32个演示进行额外的实验。如果分配给真实标签的言语者token概率大于另一个言语者token概率,则认为预测是正确的。微调会选择相同的言语者token。
如图是ICL 和 FT 对不同大小的OPT模型实验结果:
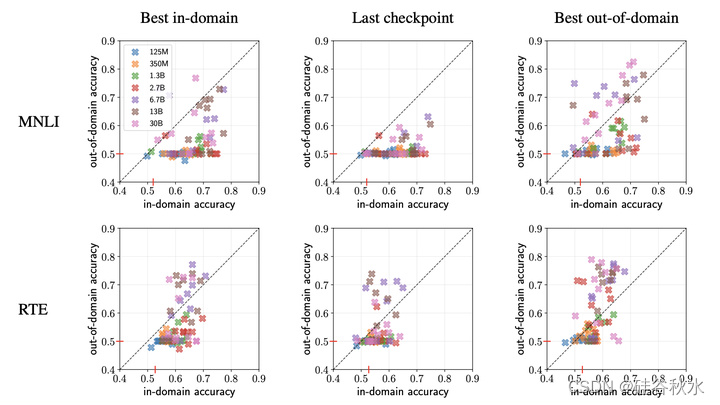
如图是FT中不同模型选择策略的结果:
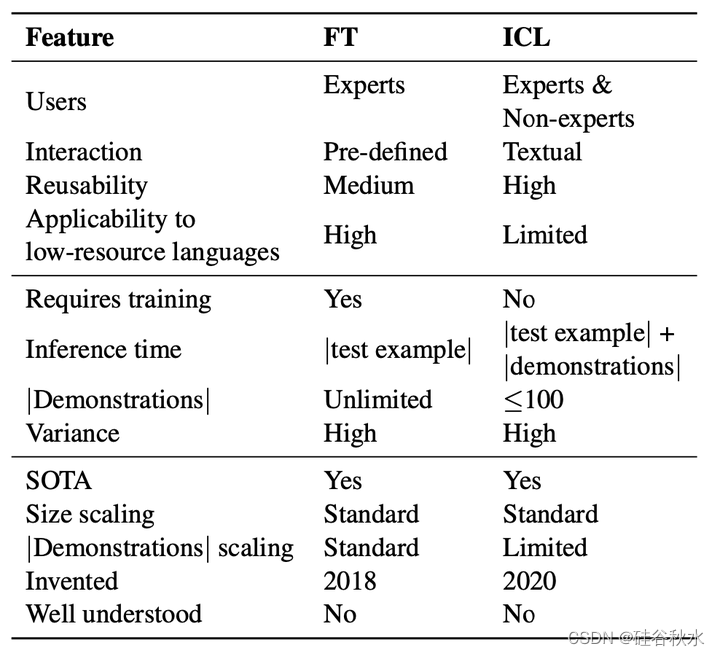
如下表是ICL和FT的高端特征比较:















 338
338

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









