










24年6月来自UC Santa Cruz、UC Davis等机构的论文“Scalable MatMul-free Language Modeling”。
MatMul 操作可以完全从 LLM 中消除,同时在十亿参数规模下保持强劲性能。这个无 MatMul 模型实现了与最先进 Transformers 相当的性能,后者在推理期间需要更多的内存,规模至少达到 2.7B 参数。从缩放规律看,无 MatMul 模型和全精度 Transformers 之间的性能差距随模型尺寸的增加而缩小。此模型的 GPU 高效实现,与未优化的基线相比,在训练期间将内存使用量降低 61%。在推理过程中使用优化核,与未优化的模型相比,模型的内存消耗可以减少 10 倍以上。
为了正确量化该架构的效率,在 FPGA 上构建一个自定义硬件解决方案,利用 GPU 无法处理的轻量级操作。其以超出人类可读吞吐量 13W 的速度处理了十亿参数规模的模型,使 LLM 更接近类似大脑的效率。
代码实现下载在 https://github.com/ridgerchu/matmulfreellm
量化语言模型的努力,始于将三元 (ternary)BERT 缩减为二值模型 [14],随后经过微调,在 GLUE 基准上实现了 41% 的平均准确率。[15] 将全精度 BERT 的中间输出提炼为量化版本。最近,[16] 引入了一种增量量化方法,逐步将模型从 32 位量化到 4 位、2 位,最后量化为二值模型参数。继 BERT 量化之后,低精度语言生成模型的发展势头强劲。[17] 使用量化-觉察训练 (QAT) 成功训练了一个 2 位权重的模型。BitNet 将其推向 30 亿参数的二元和三元模型,同时保持与 Llama 类语言模型相等的性能 [10, 11]。
无 MatMul Transformers 的使用,主要集中在 SNN (spiking neural networks)领域。Spikformer 率先将 Transformer 架构与 SNN集成 [18, 19],后来又开发了替代的 Spike 驱动 Transformers [20, 21]。这些技术在视觉任务中取得了成功。在语言理解领域,Spiking-BERT [22] 和 SpikeBERT [23] 将 SNN 应用于 BERT,利用知识蒸馏技术进行情感分析。在语言生成方面,SpikeGPT 使用一个spike RWKV(”Rwkv: Reinventing rnns for the transformer era“)架构训练了一个 216M 参数的生成模型。然而,这些模型的大小仍然受到限制,其中 SpikeGPT 是最大的,这反映了使用二值化激活进行扩展的挑战。除了 SNN,BNN 也在这一领域取得了重大进展。BinaryViT [24] 和 BiViT [25] 成功地将Binary Vision Transformers 应用于视觉任务。除了这些方法之外,Kosson [26]用分段仿射近似代替乘法、除法和非线性,实现无乘法训练,同时保持性能。
BitNet 表明,稳定三元层需要在 BitLinear 输入之前添加一个额外的 RMSNorm。但是,BitNet 的原始实现效率不高。现代 GPU 具有内存分层结构,包括大型全局高带宽内存 (HBM) 和更小、更快的共享内存 (SRAM),并且 BitNet 的实现引入了许多 I/O 操作:将之前的激活读入 SRAM 进行 RMSNorm,将其写回进行量化,再次读取量化,存储它,然后再次读取它进行线性操作。为了解决这种低效率问题,该方法只读取一次激活,并将 RMSNorm 和量化作为融合操作应用于 SRAM。
如下算法图介绍融合量化 RMSNorm 和 BitLinear 操作来提高 BitLinear 层硬件效率的方法。优化利用 SRAM 来降低 HBM I/O 成本可以显著加快计算速度。此模型中的激活,因三元权重和逐元操作量而比权重占用更大的内存,因此优化工作重点是激活。

算法中的 forward_pass 函数概述了融合的 BitLinear 层前向传递。它首先调用 rms_norm_fwd 对输入激活 X 执行 RMNSNorm,从 HBM 加载归一化激活 Y、均值 μ、方差 σ^2 和尺度因子 r。然后量化归一化激活 Y 以获得 Y~,并用 weight_quant 量化权重 W,这两项操作均无需片外数据移动即可完成。最后,将量化激活 Y~ 与三元权重 W~ 相乘,加上偏差 b,然后将结果存储回 HBM,在片上计算输出 O。
这个backward_pass 函数首先从 HBM 加载 X、W、b、O、μ、σ^2、r 和输出梯度 dO。然后通过将输出梯度 dO 与转置权重矩阵 W^T 相乘,在片上计算梯度 dY。接下来,它在芯片上调用 rms_norm_bwd 通过 RMSNorm 进行反向传播,计算输入梯度 dX。通过将转置输出的梯度 dO^T 与量化激活 Y 相乘,在芯片上计算权重梯度 dW,并通过对 dO 求和获得偏差的梯度 db。然后将计算出的梯度 dX、dW 和 db 存储回 HBM。
下面采用 Metaformer [27] 的观点,该观点认为 Transformers 由一个 token 混合器(用于混合时间信息,即 Self Attention [28]、Mamba [29])和一个通道混合器(用于混合嵌入/空间信息,即前馈网络、GLU[30, 31])组成。如图显示了该架构的高级概览:
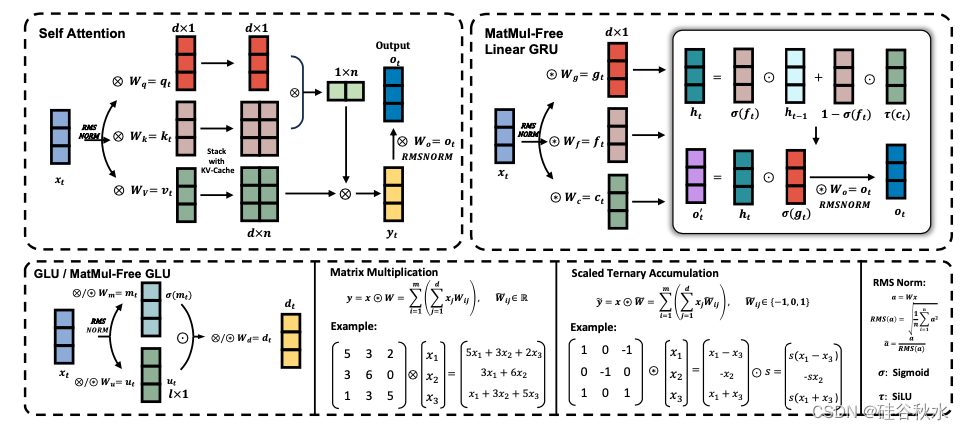
除了这个采用带逐元乘积隐态数据相关衰减的 MLGRU 之外,RWKV-4 类模型也可以满足无 MatMul token 混合器的要求,利用静态衰减和规范化操作。但是,RWKV-4 引入指数和除法运算,与 MLGRU 相比,这些运算的硬件效率较低。
注:RWKV-4 用作 token 混合器,利用递归来混合时间信息和一维隐态,该隐态使用逐元 Hadamard 乘积进行更新,从而避免 MatMul 操作。与传统的 Transformer 相比,这种方法具有多项优势,包括计算效率、跨时间步长有效传播信息、简化模型架构和减少内存使用。
通道混合器仅由密集层组成,这些密集层被三元累积运算所取代。通过在 BitLinear 模块中使用三元权重,可以消除对昂贵的 MatMuls 需求,从而使通道混合器的计算效率更高,同时保持其在跨通道混合信息的有效性。
实验中在中等规模语言建模任务上测试无 MatMul 语言模型。将无 MatMul 语言模型的两个变体,与重现的高级 Transformer 架构(Transformer++,基于 Llama-2)在三种模型大小上进行比较:3.7 亿、13 亿和 27 亿参数。为了公平比较,所有模型均在 SlimPajama 数据集 [47] 上进行预训练,3.7 亿模型在 150 亿个tokens上进行了训练,13 亿和 27 亿模型分别在 1000 亿个tokens上进行了训练。所有实验均使用 flash-linear-attention [48] 框架、Mistral [42] token化器(词汇大小:32k)和优化的 triton 核进行。模型训练使用 8 个 NVIDIA H100 GPU 进行。 370M模型的训练时长约为5小时,1.3B模型的训练时长约为84小时,2.7B模型的训练时长约为173小时。
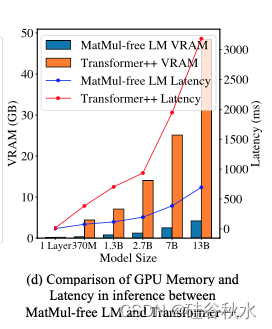
下图比较了不同模型大小 GPU 运行的 MatMul-free LM 和 Transformer++ 推理内存消耗和延迟:
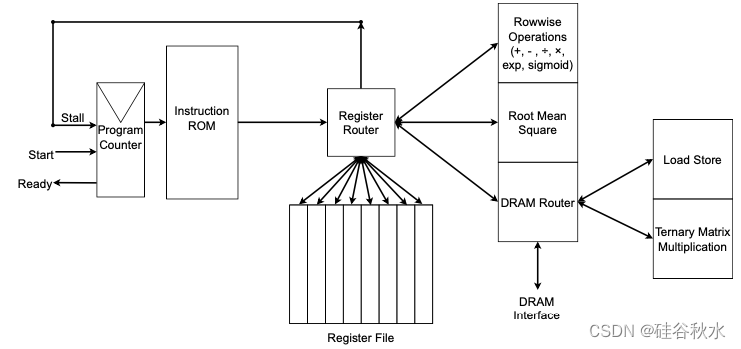
为了在能够更好地利用三元运算的定制硬件测试无 MatMul LM 的功耗和有效性,在 SystemVerilog 中创建了一个 FPGA 加速器。概览如图所示。此设计中有 4 个功能单元:“逐行运算”、“均方根”、“加载存储”和“三元矩阵乘法”,它们每个都允许简单的无序执行。















 61
61











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









