










24年1月来自谷歌的论文“SpatialVLM: Endowing Vision-Language Models with Spatial Reasoning Capabilities”。
理解和推理空间关系是视觉问答 (VQA) 和机器人技术的基本能力。虽然视觉-语言模型 (VLM) 在某些 VQA 基准测试中表现出色,但它们仍然缺乏 3D 空间推理能力,例如识别物理目标的定量关系,如距离或大小差异。假设 VLM 有限的空间推理能力是由于训练数据中缺乏 3D 空间知识,并旨在用互联网规模的空间推理数据训练 VLM 来解决此问题。为此提出一个系统来促进这种方法。首先开发一个自动 3D 空间 VQA 数据生成框架,该框架可在 1000 万张真实世界图像上扩展到 20 亿个 VQA 示例。然后,研究训练配方中的各种因素,包括数据质量、训练流水线和 VLM 架构。该工作特色在于度量空间中互联网规模 3D 空间推理数据集。通过在这些数据上训练 VLM,显著增强其在定性和定量空间 VQA 方面的能力。由于其定量估计能力,该 VLM 解锁思维链空间推理和机器人技术中的下游应用。
之前的许多研究都侧重于对 VLM [61, 69] 进行基准测试,考虑诸如 VQA 之类的任务(例如 VQAv2 [29]、OK-VQA [49]、COCO [43] 或 Visual Genome [39])。其他研究则专注于细粒度场景理解,例如语义分割 [5, 37]、目标检测 [11] 或目标识别 [15, 60]。其他研究则专门将空间推理作为一项任务,回答有关真实 [44, 55] 或模拟 [35] 场景中目标空间关系(例如上、下、左、右)的问题。该领域的真实数据可能受人工标记者生成的数量限制,而合成数据的表达能力本质上是有界的。
这项工作考虑如何自动生成真实数据,并关注的不仅仅是空间关系问题,还有度量空间距离,这可以直接应用于许多下游任务。
如图数据合成流水线概述。(a)用 CLIP 过滤嘈杂的互联网图像并仅保留场景级照片。(b)在互联网规模的图像上应用预训练的专家模型,以便获得以目标为中心的分割、深度和字幕。(c)将 2D 图像提升为 3D 点云,可以通过形状分析规则进行解析提取有用的属性,如 3D 边框。(d)通过使用 CLIP 相似度得分对目标字幕进行聚类来避免提出模棱两可的问题(e)从目标字幕和提取的属性中合成数百万个空间问题和答案。
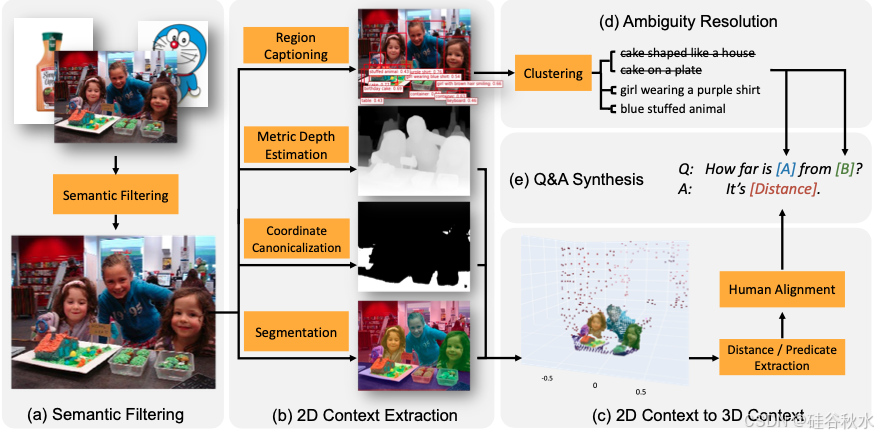
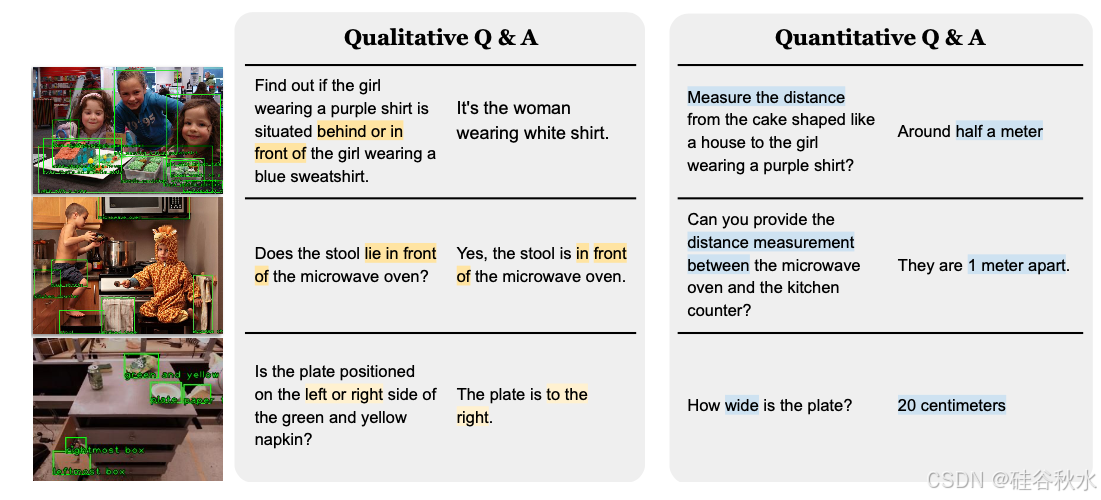
指定了 38 种不同类型的定性和定量空间推理问题,每种问题有大约 20 个问题模板和 10 个答案模板。还添加了偏差抽样以鼓励简洁的答案。最后,引入了一种与人类对齐的舍入机制,以类似人类的方式进行数字舍入。使用这种方法,能够为 webli 和 vqa 数据集中的单目相机图像生成充足的问答数据对。如图展示了获得的几个示例合成问答对。总的来说,创建了一个包含 1000 万张图像和 20 亿个直接空间推理 QA 对的海量数据集,其中 50% 是定性问题,50% 是定量问题。由于目标字幕和距离单位的多样性,合成数据集在目标描述、问题类型和措辞方面具有强多样性。
直接空间推理。其定义如下,视觉语言模型以空间任务的图像 I 和查询 Q 作为输入,并以文本字符串的格式输出答案 A,无需使用外部工具或与其他大型模型交互。采用与 PaLM-E [18] 相同的架构和训练程序,只是用较小的变型 PaLM 2-S [3] 替换 PaLM [14] 主干。然后,用原始 PaLM-E 数据集和新建数据集的混合来训练模型,其中 5% 的 token 专用于空间推理任务。与 PaLM-E 类似,该方法结合起来可以执行 VQA 以及基本的具身规划。关键的区别在于它可以回答关于二元谓词和定量估计的空间推理问题。
思维链空间推理。许多现实世界的任务需要多步空间推理。例如,要确定目标 A 是否可以放入目标 B,需要推理大小和约束。有时,人们需要基于扎实的空间概念(例如,图片中的柜台有 1 米高)和常识知识(幼儿无法触及)进行推理。SpatialVLM 提供了一个自然语言界面,可以使用扎实的概念进行查询,当与强大的 LLM 结合使用时,可以执行复杂的空间推理。
这种方法称为“思维链空间推理”。虽然合成数据只包含直接空间推理问题,但 VLM 很容易将它们组合在一起,以解决需要多步思维链推理的复杂问题。与Socratic模型 [71] 和 LLM as coordinator [10] 中的方法类似,使用 LLM (text-davinci-003) 与 SpatialVLM 进行协调和通信,解决具有思维链提示的复杂问题 [65],如图所示。LLM 可以将复杂问题分解为简单问题,查询 VLM,并将推理放在一起得出结果。

语义滤波。在数据过滤阶段,有两个重要目标:首先,将过滤掉人类几乎无法提出任何空间问题的图像,例如白色背景前的单个物体照片。其次,由于流程需要将 2D 图像提升到 3D 点云,因此希望视野接近针对单目深度估计模型进行优化的值。
为了实现第一个目标,使用预训练的 CLIP 模型来标记候选图像,并过滤掉那些代表产品或艺术品的图像。CLIP 正标签包括“一张室内场景的 iPhone 照片”和“一张室外场景的 iPhone 照片”,而负标签包括“单个目标的特写镜头”、“白色背景前展示的产品”、“一件艺术品”、“一幅画”、“图形用户界面的截图”、“一段文字”、“一幅草图”。
选择“一张 iPhone 照片”作为正例的前缀,以满足第二个目标。这个前缀有效地过滤掉了视野更宽的数据,以及某些具有不常见透视比的图像。这种数据过滤的设计选择确保剩下的图像在专家模型和 qa 生成的有效分布范围内。
2D 上下文提取。用各种现成的模型来提取相关信息以合成问答数据。在这里,为上下文提取提供额外的细节。数据过滤后,运行区域提议网络 (RPN),然后进行非最大抑制 (NMS) [30]。对于每个目标边框,运行一个与类别无关的分割模型 [41] 来分割出目标。对于每个边框,用 FlexCap [4] 来采样一个以目标为中心的字幕,其长度在 1-6 个字之间随机。特别是,故意选择避免使用传统的目标检测器,因为它们被固定在非常粗略的类别上,例如“蛋糕”,而该方法可以用细粒度的描述来注释目标,例如“形状像房子的蛋糕”和“塑料容器中的纸杯蛋糕”等。
2D 上下文到 3D 上下文提升。然后,在图像上运行最先进度量深度检测器 ZoeDepth [6]。ZoeDepth 输出度量深度(以现实世界的“米”为单位)。结合焦点估计,能够将 2D 图像提升为 3D 点云,以真实世界比例表示。
在此点云处理步骤中,将删除异常值或明显偏离主要组的点,以提高数据准确性。聚类算法 DBSCAN [22] 根据接近度对点进行分组,重点关注密分布的区域并消除稀疏、不太重要的点。这样可以得到更干净、更结构化的点云,非常适合后续的形状和几何分析,其中需要测量形状的尺寸。由于已经获得了点云的语义分割,因此可以使用此信息以自适应比例处理异常值。对于较小的目标,使用较小的阈值,与每个轴成比例。这种选择有效地去除了点云异常值,同时还保留了较小目标的重要点。
坐标规范化。现在有一个公制尺度下的 3D 点云。然而,点云仍然在相机框架内,这限制了可以提取的信息。例如,靠近图像上侧的目标不一定离地面更远,因为相机可能指向地面而不是正面。为了解决这个问题,通过检测水平表面来规范化点云的坐标系。用轻量级分割模型 [9] 分割出与“地板”、“桌面”等类别相对应的像素,然后使用 RANSAC 拟合这些 3D 点中最大的平面。
当检测到由足够多点定义的表面时,将相机原点投影到检测的平面来创建新原点,从而规范化点云的坐标。使用检测的平面法线轴作为 z 轴,并将相机的原始 z 轴投影到平面上作为新的 x 轴。通过这样做,当能够检测到像地面这样的水平表面时,有效地将点云转换为世界坐标而不是相机坐标。另一方面,当没有检测到足够多与水平表面相对应的点时,将规范化标记为失败,并避免合成依赖于规范化的问题,例如有关海拔的问题。
消除歧义。首先使用 CLIP 编码器 [52] 嵌入所有字幕。这能够计算每一字幕对之间的余弦距离。这形成了所有目标之间的相似度矩阵。如果对相似度得分进行阈值设置,就可以确定某个目标字幕是否与其他字幕太近。在许多情况下,有两个完全相同的字幕组,因此可以通过附加区分子句(例如“这更靠近图像顶部”)来轻松扩充每个字幕。其他情况涉及两个以上的相似字幕,选择将它们全部删除以避免歧义。还根据 CLIP 与“太阳”或“天空”等类别的相似性删除常见的背景目标。
与人对齐。人类很少说出带有许多小数位的距离测量值,例如 0.95 米。相反,他们将这种距离四舍五入为他们喜欢的数字,例如 1 米或半米。希望模型也能符合人类的这种偏好。事实上,由于深度估计和视场估计包含不可约误差,模型应该被允许像人类一样四舍五入来表达不确定的答案,除非被提示一定要准确。为此,对任何定量距离单位进行后处理以符合人类偏好。编写一个决策树来进行这种对齐。例如,当估计距离为 0.86 米时,有 75% 的概率将其四舍五入为 1 米,而回答 3 英尺 90 厘米的概率会更低。对于像 23 米这样的距离,也有很高的概率将其四舍五入为 20 米。还以 20% 的概率对英制单位而不是公制单位进行采样,采用类似人类的舍入规则。
虽然这可能使模型更好地与人类保持一致,但在采样时,人们可能希望获得更准确的距离估计。为此,人们只需对多个距离估计进行采样并取平均值。在机器人实验中使用这种方法来获得更细粒度的值。另一种方法是提示 VLM 本身保留一定量的数字。这可以添加到数据合成中。
VLM 训练 。训练多模态大语言模型,批量大小为 512,ADAM 优化器学习率为 2e-4。用 PaLM-E 中的原始 VQA 数据集和生成的空间 VQA 数据集混合来训练 PaLM 2-E-S 模型,采样率为 174:2.5。最初使用冻结视觉编码器对模型进行 110k 步训练,这不会穷尽使用所以的数据。因此,生成的数据绰绰有余。然后,用冻结或解冻的视觉编码器进行 70k 步微调,直到收敛。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









