










23年11月来自清华、上海AI实验室和上海姚期智研究院的论文“Look Before You Leap: Unveiling the Power of GPT-4V in Robotic Vision-Language Planning”。
本研究是让机器人具备物理上落地的任务规划能力。最近的进展表明,大语言模型 (LLM) 拥有丰富的知识,可用于机器人任务,尤其是在推理和规划方面。然而,LLM 受到一些限制,如缺乏世界落地和依赖外部affordance模型来感知环境信息,而这些信息无法与 LLM 联合推理。任务规划器应该是一个固有落地、统一的多模态系统。为此,引入机器人视觉-语言规划 (ViLa),这是一种长范围机器人规划方法,它利用视觉语言模型 (VLM) 来生成一系列可操作的步骤。ViLa 将感知数据直接集成到其推理和规划过程中,从而能够深刻理解视觉世界中的常识知识,包括空间布局和目标属性。它还支持灵活的多模态目标规范并自然地融入视觉反馈。在真实机器人和模拟环境中进行广泛评估,证明了 ViLa 优于现有基于 LLM 的规划器,凸显其在广泛的开放世界操纵任务中的有效性。
场景-觉察任务规划,是人类智能的关键方面 [83, 75]。当呈现简单的语言指令时,人类会根据上下文演示出一系列复杂的行为。以“拿一罐可乐”的指令为例。如果可乐罐是可见的,人们会立即拿起它。如果看不见,他们会搜索冰箱或储藏柜等位置。这种适应性反映了人类对场景的深刻理解和广泛的常识,使他们能够根据上下文解释指令。
近年来,大语言模型 (LLM) [9, 62, 13, 6] 展示了其在编码有关世界的广泛语义知识方面的卓越能力 [65, 42, 29]。这引发了人们对利用 LLM 为复杂的长期任务生成分步规划的兴趣日益浓厚 [2, 37, 38]。然而,LLM 的一个关键限制是它们缺乏世界基础 —— 它们无法感知和推理机器人及其环境的物理状态,包括物体形状、物理属性和现实世界约束。
为了克服这一挑战,一种流行的方法是采用外部affordance模型 [27],例如开放词汇检测器 [57] 和价值函数 [2],为 LLM 提供现实世界的落地 [2, 40]。然而,这些模块通常无法在复杂环境中传达真正必要的任务相关信息,因为它们充当向 LLM 传输感知信息的单向通道。在这种情况下,LLM 就像一个盲人,而affordance模型则充当一个有视力的向导。一方面,盲人完全依靠自己的想象力和导游有限的叙述来理解世界;另一方面,有视力的向导可能无法准确理解盲人的目的。
在缺乏精确的、与任务相关视觉信息的情况下,这种组合通常会导致不可行或不安全的行动规划。例如,一个负责从架子上取出漫威(Marvel)模型的机器人可能会忽略纸杯和可乐罐等障碍物,从而导致碰撞。考虑另一个准备美术课的例子,剪刀,可以被视为锋利和危险的物体,或被视为手工艺品的必备工具。由于缺乏特定的任务信息,这种区分对于视觉模块来说具有挑战性。
这些例子突出了基于 LLM 规划器在捕捉复杂的空间布局和细粒度目标属性方面的局限性,强调了视觉和语言之间主动联合推理的必要性。以 GPT-4V(ision) [61, 88] 为代表的视觉语言模型 (VLM) 的最新进展,大大拓宽了研究视野。VLM 将感知和语言处理协同成一个统一的系统,从而能够将感知信息直接纳入语言模型的推理中 [53, 14, 5, 97]。
设定机器人系统采用对环境的视觉观测 xt 和描述操作任务的高级语言指令 L(例如“将这些不同颜色的容器稳固地堆叠起来”)。假设视觉观测 xt 可以准确表示世界状态。语言指令 L 可以是任意长的范围或未指定的范围(即需要上下文理解)。工作研究的核心问题是生成一系列文本动作,表示为 l1 , l2 , · · · , lT 。每个文本动作 lt 都是一个短范围的语言指令(例如“拿起蓝色容器”),它指定一个子任务/原始技能 πlt。注:这里并不侧重于这些技能 Π 的获得;相反,假设所有必要的技能都已具备。这些技能可以采用预定义的脚本策略形式,也可以通过各种学习方法获得,包括强化学习 (RL) [76] 和行为克隆 (BC) [66]。
为了生成可行的规划,高级机器人规划必须落地物理世界。虽然 LLM 拥有丰富的结构化世界知识,但它们完全依赖于语言输入,因此需要外部组件(例如affordance模型)来完成基础过程。然而,这些外部affordance模型(例如,RL 策略的价值函数 [2, 44]、目标检测模型 [57] 和动作检测模型 [71])是手动设计的独立通道,独立于 LLM 运行,而不是集成到端到端系统中。此外,它们的作用仅仅是将高维视觉感知信息传输给 LLM,缺乏联合推理能力。视觉和语言模态的分离,导致视觉模块无法提供全面的、与任务相关的视觉信息,从而阻碍了 LLM 基于准确的与任务相关的视觉洞察进行规划。
视觉语言模型 (VLM) 的最新进展提供了一种解决方案。 VLM 展现出前所未有的图像和语言理解和推理能力 [53, 14, 5, 97]。至关重要的是,VLM 中蕴含的广泛世界知识本质上植根于它们处理的视觉数据。因此,直接使用 VLM,协同视觉和语言能力,将高级指令分解为一系列低级技能。
该方法称为机器人视觉语言规划 (ViLa)。具体而言,给定当前对环境的视觉观测 xt 和高级语言目标 L,ViLa 提示 VLM 生成分步规划 p1:N 来运行。选择第一步作为文本操作 lt = p1,实现闭环执行。一旦选择了文本动作 lt,机器人就会执行相应的策略 πlt,并修改 VLM 查询以包含 lt,然后再次运行该过程,直到达到终止token(例如“完成”)。其流程的概述如图所示,算法也描述如下。

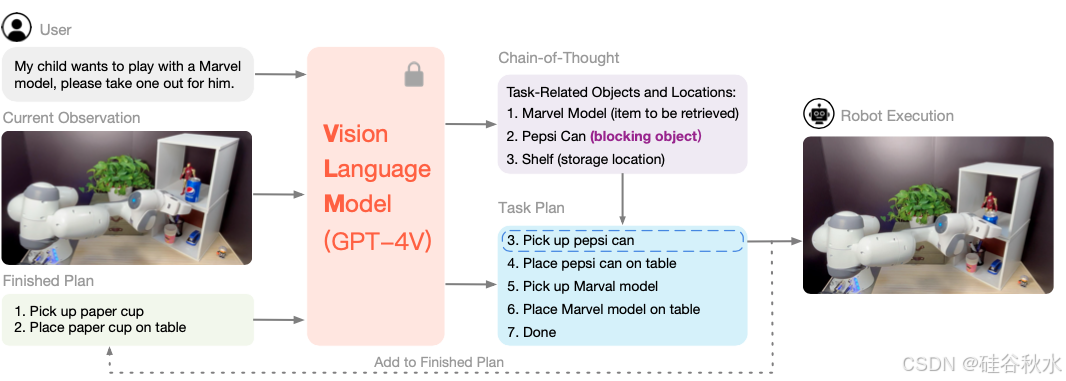
在研究中,用 GPT-4V(ision) [61, 88] 作为 VLM。GPT-4V 在大量互联网规模数据上进行训练,表现出卓越的多功能性和极强的泛化能力。这些属性使其特别擅长处理开放世界场景。此外,由 GPT-4V 提供支持的 ViLa 能够解决各种具有挑战性的规划问题,即使在零样本模式下运行(即不需要任何上下文示例)。这大大减少了以前方法所需的提示工程工作 [2, 37, 40]。
如图是ViLa做长范围机器人任务规划的例子:(a)-(l)给出12个任务。

实验设置如下。
硬件。设置了一个真实的桌面环境。用 Franka Emika Panda 机器人(7 自由度手臂)和 1 自由度平行钳口夹持器。对于感知,用安装在三脚架上的 Logitech Brio 彩色相机,以一定角度指向桌面。为了确保实验的一致性,在所有任务中都保持固定的相机视图,但为了视觉美观,在不同的视图下录制视频演示。
任务和评估。设计了 16 个长范围操作任务来评估 VILA 在三个领域的表现:对视觉世界中常识知识的理解(8 个任务)、目标指定的灵活性(4 个任务)和视觉反馈的利用(4 个任务)。上图只是展示了从前两个领域中抽取的 12 个任务。对于每个任务,会评估 10 种不同环境变化中的所有方法,包括场景配置和照明条件的变化等。
如图显示 ViLa 与 SayCan 比较的两个环境展示。在第一个 Bring Empty Plate 任务中,VILA 识别出在拿起蓝色盘子之前需要将苹果和香蕉从蓝色盘子中移开。相比之下,SayCan 识别出物品(苹果、香蕉、蓝色盘子),但缺乏对它们空间关系的认识,导致它试图直接拿起蓝色盘子。这凸显视觉上理解复杂几何配置和环境约束的重要性。在另一个场景中,为儿童美术课准备安全区域(准备美术课),ViLa 根据桌子上的剪纸这一上下文线索,判断只有螺丝刀和水果刀是危险的,而课堂上必备的剪刀则不危险。然而,SayCan 却错误地将剪刀归类为危险物品,这表明全面、全面的视觉理解对于准确评估物体属性至关重要。


















 487
487

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









