










23年7月来自上海交大的论文“RH20T: A Comprehensive Robotic Dataset for Learning Diverse Skills in One-Shot”。
开放领域机器人操作面临的一个关键挑战,是如何让机器人获得多样化和可泛化的技能。单样本模仿学习和机器人基础模型的最新进展,显示出将训练的策略迁移到基于演示新任务的前景。这一特性对于使机器人获得新技能并提高其操作能力很有吸引力。然而,由于训练数据集的限制,社区目前的重点主要放在简单的情况上,例如推或取-放任务,仅依靠视觉引导。事实上,有许多复杂的技能,其中一些甚至可能需要视觉和触觉感知才能解决。本文旨在释放智体通过多模态感知泛化到数百种现实世界技能的潜力。为了实现这一目标,收集一个数据集,其中包含超过 110,000 个接触丰富的机器人操作序列,涵盖各种技能、环境、机器人和摄像机视点,所有这些都是在现实世界中收集的。数据集中的每个序列都包含视觉、力、音频和动作信息。此外,还为每个机器人序列提供相应的人类演示视频和语言描述。
机器人操作需要机器人控制其执行器并按照任务规范改变环境。让机器人以最小的努力学习新技能,是机器人学习社区的最终目标之一。单样本模仿学习和新兴基础模型的最新研究,描绘了一幅令人兴奋的图景,即在给定演示的情况下将训练好的策略转移到新任务上。
虽然未来充满希望,但大多数机器人研究只证明了其算法在简单情况下的有效性,例如在现实世界中推动、拾取-和-放置物体。两个主要因素阻碍了在这方面探索更复杂的任务。首先,尽管社区长期以来一直渴望获得此类数据集,但该领域缺乏大型和多样化的机器人操作数据集[B]]。根本问题源于与数据获取相关的巨大障碍。这些挑战包括配置不同的机器人平台、创建不同的环境和收集操作轨迹的艰巨任务,这需要大量的精力和资源。其次,大多数方法仅侧重于视觉引导控制,然而生理学研究发现,数字感知能力受损的人仅靠视觉引导很难完成许多日常操作 [ZI]。这表明,为了在开放环境中学习各种操作,应该考虑更多的感官信息。
为了解决这些问题,重新审视机器人操作的数据收集过程。在大多数模仿学习文献中,专家机器人轨迹是使用简化的用户界面(如 3D 鼠标、键盘或 VR 遥控器)手动收集的。然而,这些控制方法效率低下,当机器人与环境进行丰富接触交互时会带来安全风险。主要原因是使用 3D 鼠标或键盘控制的不直观性,以及使用 VR 遥控器时运动漂移导致的不准确性。此外,没有力反馈的远程操作会降低人类的操作效率。
本文为机器人配备了力矩传感器,并使用了具有力绘制功能的触觉设备来精确高效地收集数据。为了使数据集具有代表性、通用性、多样性和贴近现实,收集了大约 150 种技能,这些技能除了简单的拾取和放置外,还具有复杂的动作。这些技能要么是从 RLBench [I9] 和 MetaWorld [AO] 中选择出来的,要么是自己提出的。许多技能需要机器人与环境进行接触丰富的交互,例如切割、插入、切片、倾倒、折叠、旋转等。使用了世界各地实验室中常见的多种不同机械臂来收集数据集。机器人配置的多样性也可以帮助算法泛化到其他机器人。
如图是 20TB 机器人-人类演示 (RH20T)数据集概述:多模态、多视角、多具身和多技能。

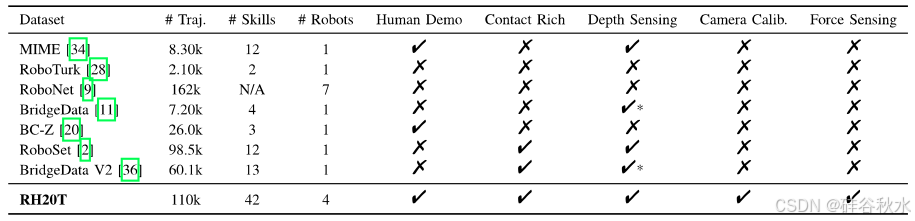
RH20T 的设计目标是实现一般的机器人操作,这意味着机器人可以根据任务描述(通常是人类演示视频)执行各种技能,同时尽量减少僵化任务的概念。为了实现这一目标,强调了以下属性,下表提供了数据集与之前具有代表性的公开数据集之间比较:
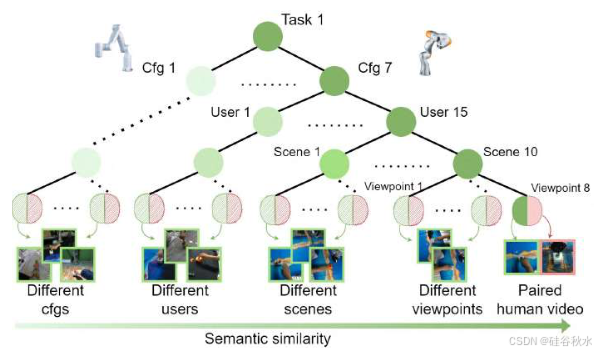
无论视点、背景、操作主体或目标如何,人类都可以根据视觉观察准确理解任务的语义。目标是提供一个提供密集<人类演示,机器人操作>对的数据集,使模型能够学习此属性。为此,根据任务内(intra-task)相似性将数据集组织成树状层次结构。如图说明了示例树结构和不同级的标准。具有最近共同祖先的叶节点关系更密切。对于每个任务,可以将叶节点与不同级别的共同祖先配对来构建数百万个<人类演示,机器人操作>对。
与之前使用 3D 鼠标、VR 遥控器或手机简化的远程操作界面方法不同,强调直观和准确的远程操作在收集接触丰富的机器人操作数据方面的重要性。如果没有适当的远程操作,机器人很容易与环境发生碰撞并产生巨大的力量,从而触发紧急停止。因此,以前的工作要么避免接触 [20],要么以较低的速度运行以减轻这些风险。
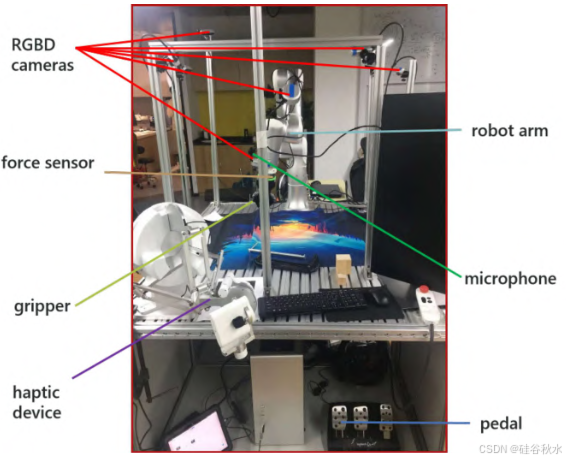
如图显示数据收集平台的一个示例。每个平台都包含一个带有力矩传感器的机械臂、夹持器和 1-2 个手持摄像头、8-10 个全局摄像头、2 个麦克风、一个触觉设备、一个踏板和一个数据收集工作站。在进行操作之前,所有摄像机都经过外部标定。人类演示视频由人类在同一平台上使用额外的自我中心摄像头收集。数十名志愿者根据任务列表和文字描述进行机器人操作。远程操作非常直观,平均训练时间少于 1 小时。志愿者还需要指定任务的结束时间,并在完成每个操作后给出从 0 到 9 的评分。0 表示机器人进入紧急状态(例如,硬碰撞),1 表示任务失败,2-9 表示对操作质量的评估。在数据集中,成功和失败的情况比例约为 10:1。
对数据集进行预处理以提供一致的数据接口。所有机器人和力矩传感器的坐标系都是对齐的。不同的力矩传感器经过仔细配重。末端执行器笛卡尔姿势和力矩数据被转换成每个摄像机的坐标系。对每个场景进行手动验证以确保摄像机标定质量。如图展示在统一坐标系中渲染数据的不同组成部分,并展示了数据集的高质量。

RH20T 数据集,旨在使机器人能够使用最少的数据在陌生的环境中获得新技能。虽然最终目标是训练一个能够以单样本学习方式执行此类任务的大型模型,但这项工作需要大量的计算资源,而这目前超出了本文研究人员的能力范围。因此,本文主要侧重于展示数据集在少样本学习框架内增强基线模型可迁移性的有效性。
为了评估数据集的有效性,采用带有 Transformers 的动作分块 (ACT) 模型作为基线网络。ACT [M3] 在处理复杂的机器人操作任务方面表现出了卓越的能力。它利用 Transformers 的力量从数百个演示中学习复杂的动作序列。

















 2650
2650

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









