







24年11月来自清华、微软、中科大和微电子所的论文“CogACT: A Foundational Vision-Language-Action Model for Synergizing Cognition and Action in Robotic Manipulation”。
大型视觉-语言-动作 (VLA) 模型的进步显著提高了机器人操作在语言引导任务执行和泛化到未见场景方面的能力。虽然现有的从预训练大型视觉-语言模型 (VLM) 适配的 VLA 已经表现出良好的泛化能力,但它们的任务表现仍然不尽人意,这从不同环境下的任务成功率低可以看出。本文提出一种源自 VLM 的高级 VLA 架构。与以前通过简单的动作量化直接将 VLM 重用于动作预测的研究不同,其提出一种组件化的 VLA 架构,该架构具有以 VLM 输出为条件的专用动作模块。本文系统地研究动作模块的设计,并展示使用扩散动作Transformer对动作序列建模的强大性能提升,以及它们良好的规模化行为。
近年来,人们对配备视觉功能机器人控制模型的兴趣激增 [7、8、15、30、34、45、48、58、60、62、67、69]。其中,大规模视觉-语言-动作 (VLA) 模型 [8、30、32] 的开发尤其有前景,它使机器人能够执行由自然语言指令引导的复杂任务,并可能管理偏离训练分布的目标或环境。此外,它们通过微调表现出对新任务和实施方案的快速适应性。
大型 VLA 的显著泛化能力,可以归因于它们相当大的模型大小和作为其基础的强大视觉-语言模型 (VLM) [13、28、35]。这些 VLM 通常在海量、互联网规模的图像-文本对上进行预训练,这在增强 VLA 对新目标和语义多样化指令的泛化方面发挥着至关重要的作用 [8]。
现有的大型 VLA 通常以简单的方式调整 VLM 以进行动作预测,这会导致一些阻碍任务执行的问题。例如,[8, 30] 等工作根据 VLM 的下一个token预测方案将机器人动作的连续频谱直接量化为离散的bins。然而,这种简单的量化与为图像 [65, 72] 和音频 [19, 73] 设计的复杂token化器不同,给动作学习带来了困难并限制了动作精度。[32] 引入了额外的动作头,例如 LSTM,将 VLM 输出转换为动作。然而,转向基于回归的学习方案忽略了动作的概率和多模态性。
大语言模型 (LLM) [2, 9, 63, 64] 和视觉语言模型 (VLM) [1, 14, 28, 37, 61] 的成功启发了视觉-语言-动作 (VLA) 模型的发展,该模型通过集成动作生成扩展了 VLM 的功能。例如,RoboFlamingo [32] 通过合并头部网络来预测动作并使用 MSE 损失进行优化,扩展了 OpenFlamingo [3]。RT-2 [8] 将 7D 动作token化为离散tokens,并使用 VLM PaLI-X [13] 像语言tokens一样自回归地预测它们。OpenVLA 采用类似的方法,对动作进行token化并在 Open-X-Embodiment 数据集 [48] 上训练 Prismatic VLM [28]。虽然这些模型受益于 VLM 的功能,并表现出良好的性能和令人印象深刻的泛化能力,但它们没有考虑到动作本质上是连续和时间性的,这是一种不同于语言的模态。一组方法 [5、11、68] 采用大规模视频生成预训练来增强视觉机器人操作学习,而无需利用预训练的 VLM,并且已经证明了有希望的结果。
DTP [24] 训练了一个具有 221M 个参数的扩散Transformer,[38] 进一步将动作模型大小缩放到 1B。这两项工作都应用了单独的视觉和语言编码器,这些编码器经过预训练和冻结以处理语言指令和图像,并且它们训练动作模型以整合这些输入并使用 VLA 数据预测动作。不过,这些工作无法利用在互联网规模的视觉语言对齐数据上预训练的强大 VLM 的泛化和指令跟踪能力。
最近的研究 [15, 50, 53] 引入了扩散模型作为对机器人动作进行建模的创新方法。这些扩散策略已证明能够强大地捕捉机器人动作分布的多模态性,并有效地模拟机器人完成给定任务时可以采取的各种可行轨迹 [15]。受扩散策略的启发,Octo [62] 使用 3M 参数的紧凑扩散头补充了基于 Transformer 的骨干架构,以适应不同机器人的动作输出。然而,小型扩散头无法捕捉精确的动作分布,而且整体方法并没有从在网络规模数据上预训练的强大视觉语言模型中受益。
为了有效处理复杂的视觉观察和语言指令,并协同将它们转化为精确的动作,其将模型π分为三个部分:视觉模块、语言模块和扩散动作模块,如图所示。
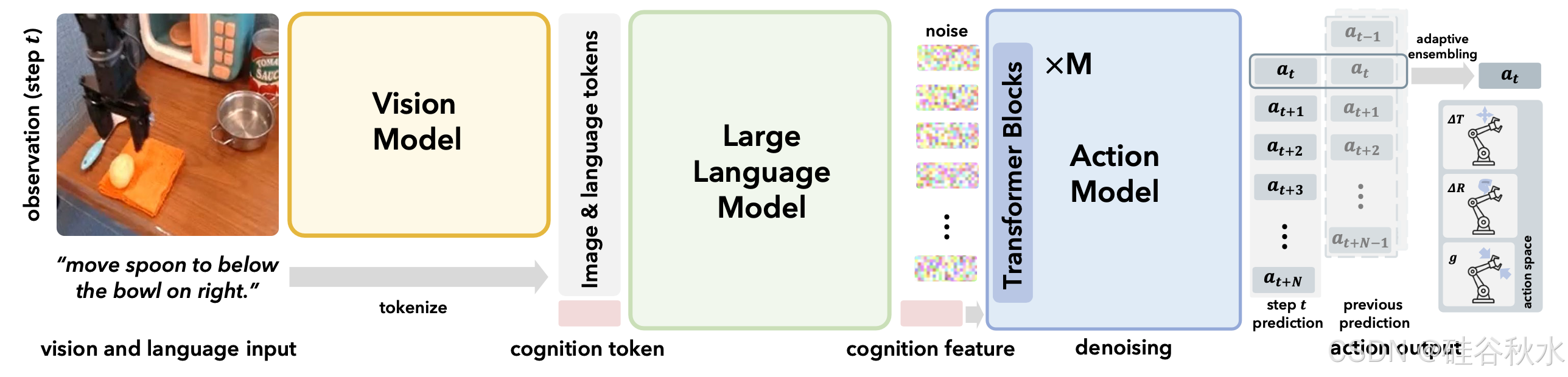
视觉和语言模块改编自 [28] 中现有的 VLM,它总共有大约 7B 个参数,与 [30] 类似。
视觉模块。视觉模块将原始图像输入到一组感知tokens中。它由强大的视觉Transformer DINOv2 [49] 和 SigLIP [74] 组成,这些Transformer在互联网规模的图像数据上进行了预训练,以捕捉丰富的视觉特征和对观察结果的全面语义理解。
语言模块。语言模块负责整合视觉信息和语言指令并进行认知推理。这里采用 LLAMA-2 模型 [64] 作为主干。使用 LLAMA-2 的 token化器将语言指令 l 转换为一组语言tokens。然后,这些 tokens 与视觉token V 和额外的可学习认知 token 连接起来,并由模型使用因果注意机制进行处理。与认知tokens相对应的结果输出特征,对确定当前任务要执行操作的综合信息进行编码。这是后续操作模块理解和得出所需操作的条件。
扩散动作模块。动作模块接收认知特征作为输入条件,以生成一系列动作。鉴于现实世界的物理动作是连续的且通常是多模态的,用扩散建模过程来预测它们 [47]。为了对复杂且时间相关的动作进行建模,应用扩散Transformer (DiT) [51] 作为动作解码过程的强大支柱。
训练过程中,通过最小化动作模块预测噪声与真值噪声之间的均方误差 (MSE),视觉模块、语言模块和动作模块进行了端到端的训练/微调。
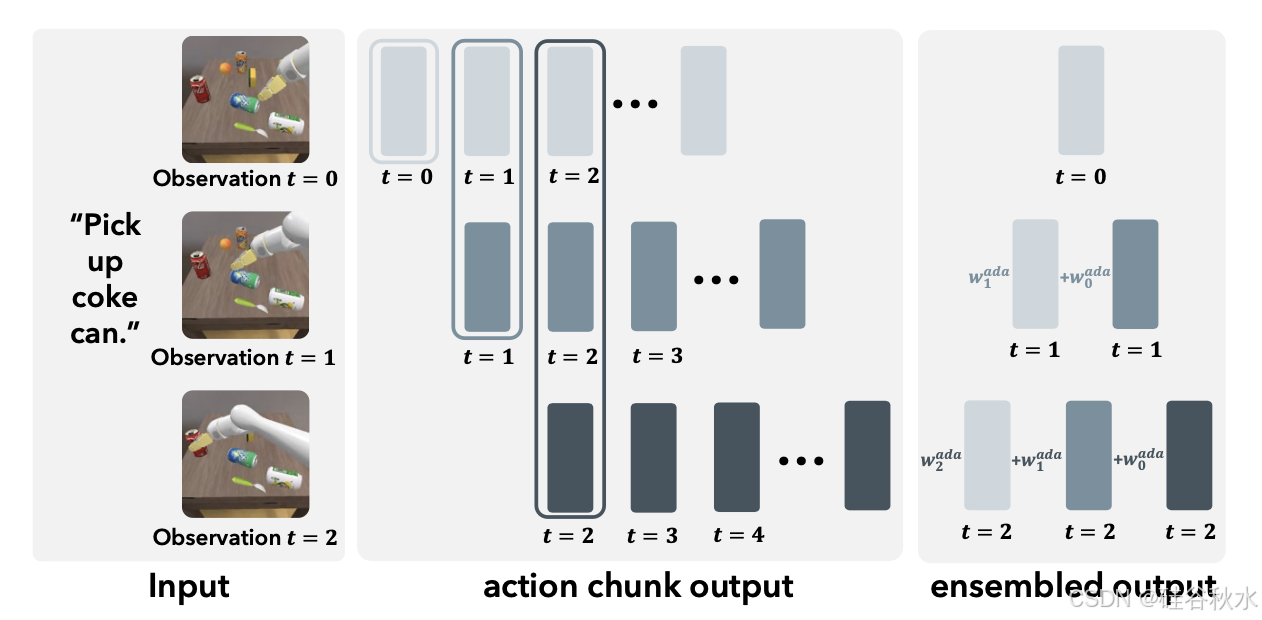
在推理过程中,模型会预测多个时间步骤的动作。一种简单的策略是根据当前观察连续执行这些动作(动作分块 [75])。但是,这并不能充分利用每个时间步骤可用的视觉信息,并且可能会导致运动不平稳,如 [75] 中所述。或者,只执行当前时间步骤的动作也会导致轨迹不太平滑,性能下降。
为了缓解这些问题,[75] 引入了一种时间集成策略,该策略使用预设的聚合权重结合当前和过去预测中对当前时间步骤预测的动作。但是,任务执行的可行操作可能属于不同的模式 [15],简单地聚合它们可能会导致与任何模式都不一致的操作,这是次优的。
本文提出了一种自适应集成策略,该策略考虑要聚合动作之间的相似性,如图所示。这种方法避免了不同模态动作不合理的聚合。
实验中用 Open X-Embodiment (OXE) [48] 数据集作为主要训练数据集。它包括从 60 个数据集收集的 100 多万条真实世界机器人轨迹,涵盖 22 种不同的机器人实现。用与 Octo [62] 和 OpenVLA [30] 类似的 OXE 子集进行训练,其中包含 2250 万帧。
VLA 模型建立在预训练的 VLM Prismatic [28] 之上。Prismatic 模型使用 DINOv2 [49] 和 SigLIP [74] 作为视觉模块,分别使用 12 亿张图像和 400 亿个图像-文本对进行训练。LLaMa-2 [64] 被用作 LLM 主干,使用 2 万亿个语言tokens进行训练。[28] 使用 120 万个多模态指令调优示例对视觉和 LLM 模块进行进一步微调。
在 Open X-Embodiment [48] 中的 25 个 VLA 数据集上对模型进行预训练。与 Octo [62] 和 OpenVLA [30] 一样,将训练限制在具有单臂末端执行器控制和至少一个第三人称摄像机视角的数据集上。数据混合策略主要遵循 [30, 62],但在整个训练过程中不使用 Language Table [41] 和 Droid [29] 数据集,因为它们与其他数据的分布存在显著差异。总共用包含 2250 万帧的 40 万条机器人轨迹作为训练数据。
如图显示 Realman 机器人实验的硬件设置。制造一个机器人,它的肩膀上有两个 Realman 手臂,每个手臂有 7 个自由度 (DoF)。将左臂与一个 1-DoF 夹持器连接起来,并在所有实验中仅使用此手臂。用英特尔 RealSense 摄像头捕捉 RGB 图像。每次移动摄像头时,都会执行手眼标定。将训练数据中的所有动作转换为摄像头坐标系,将模型生成的动作转换为机器人坐标系。为了评估模型在不同视点的泛化能力,在实验前随机移动摄像头。机器人配备了一个移动底座,每次实验前都会随机重新定位,以评估模型的泛化能力。

该模型的训练批次大小为 256,每个样本有 8 个扩散步骤,并使用 [30] 中预训练的视觉和语言模块权重进行初始化。视觉模块(即 DINOv2 和 SigLIP)、语言模块(即 LLAMA-2)和动作模块均以端到端的方式进行训练,以 2e − 5 的恒定学习率进行超过 135K 次迭代。训练在 16 个 NVIDIA A100 GPU 上进行,耗时约 5 天,使用 PyTorch 的完全分片数据并行 (FSDP) 框架。默认情况下,用 DiT-Base 作为动作模型。集成窗口 K 设置为与每帧的移动距离成反比,这可以从机器人的运动速度和观察频率推断出来。在实践中用训练集中动作的标准差来确定 K,即对于 Google Robot 的 RT-1 数据集为 2,对于 WidowX Robot 的 BridgeDataV2 为 7。
Franka 机器人的设置如图所示。在本具身中,一个具有 7 个自由度的机械臂被刚性地固定在桌子上。在右侧使用 Kinect DK 相机来捕获 RGB 图像。整个流程中的动作都在机器人坐标系中。

数据收集。用 Meta Quest 2 设备的触摸控制器来遥控机器人并收集两个机器人的演示数据。触摸控制器的平移和旋转映射到夹持器的 3D 运动,按钮控制夹持器的打开和关闭。以 30 Hz 的频率为 Realman 机器人录制视频帧,以 5∼6 Hz 的频率为 Franka 机器人录制视频帧。从录制的完整视频中手动修剪视频片段并附加描述任务的语言指令。
数据预处理。遵循 Open X-Embodiment 数据集 [48] 的格式来处理 Realman 机器人和 Franka 机器人的两个微调数据集。将图像裁剪并调整为 224×224,并将动作转换为相对平移偏移和旋转变化。计算旋转矩阵中的旋转变化,并将其转换为欧拉角进行训练。在训练期间,Realman 机器人数据被随机采样为 5 Hz,帧之间的时间间隔为 0.2 秒。Franka 机器人数据按原样使用。
由于不同研究中使用的硬件、环境和任务各不相同 [33],评估机器人操作任务具有挑战性。虽然标准化的真实世界设置可能很有用,但它们通常需要大量的时间和资源 [10, 16, 31, 76]。为了解决这些问题,同时保持真实世界性能评估的准确性,SIMPLER [33] 开发了一个系统,用于评估在模拟环境中对真实数据训练的操作策略。因此,在评估中使用了 SIMPLER,它提供了一个易于重现且完全公平的评估框架。
所有模拟仿真评估均在单个 NVIDIA A6000 GPU 或单个 NVIDIA A100 GPU 上进行。在推理过程中,采用 DDIM [59] 采样,采样步骤为 10 个,无分类器指导 (CFG) [23] 系数为 1.5。
在所有模型中应用统一的自适应动作集成策略,其中超参数 α 设置为 0.1。集成窗口大小 K 决定了要使用的历史观测数量及其预测动作。由于不同的数据集具有不同的控制频率和机器人速度,因此窗口大小 K 应该是自适应的。选择窗口大小 K,使 K 与每个时间步 6D 动作的平均标准差 (std) 乘积在不同数据集上保持不变。正式地,这种关系可以表示为 C = K × std,其中 C 是一个常数,表示机器人在过去 K 步中行进的距离和角度。根据经验,将所有实验的 C 设置为 0.2,并据此推导出它们的 K。
对于 Google 机器人上的实验,[33] 评估了以前方法的任务成功率,并将其纳入本文,但 OpenVLA [30] 除外,它未包含在 [33] 中。对于 OpenVLA,直接使用其官方存储库中的权重对其进行评估。在 WidowX 机器人上,RT-1-X [48] 的性能直接报告为 [33],OpenVLA 的评估如上所述。对于 Octo-Base 和 Octo-Small [62],加入了更多的随机种子并进行了五次重新测试,以减轻其概率抽样的波动性。对于模型的所有配置,用与 Octo 相同数量的测试来评估它们。请注意,RT-2-X 在 WidowX 上的性能尚未报告 [33],并且没有公开可供评估的模型权重。
微调过程在 16 个 NVIDIA A100 GPU 上进行,所有参与比较的模型都使用 PyTorch FSDP 进行完全微调,批处理大小为 256。对于本文的方法,简单地在 10K 微调步骤中测试了一个微调检查点,这需要 7.5 小时的微调时间。对于 Octo [62] 和 OpenVLA [30],在不同的步骤中测试多个微调检查点,并选择在实际任务中效果最好的检查点。具体来说,对于 Realman 机器人,Octo 使用 20K 检查点,而 OpenVLA 使用 30K 检查点;这两个模型在 Franka 机器人上都使用 30K 检查点。所有微调数据都遵循与预训练期间使用相同的数据增强。

















 3891
3891

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









