










24年12月来自微软的论文“Phi-4 Technical Report”。
phi-4 是一个拥有 140 亿参数的语言模型,其训练方法主要关注数据质量。与大多数语言模型不同,phi-4 在整个训练过程中策略性地加入合成数据,而大多数语言模型的预训练主要基于 Web 内容或代码等有机数据源。虽然 Phi 系列中先前的模型在很大程度上蒸馏教师模型(特别是 GPT-4)的功能,但 phi-4 在聚焦 STEM 的 QA 功能方面大大超越教师模型,这证明数据生成和后训练技术在蒸馏以外。尽管对 phi-3 架构的改动很小,但由于数据、训练课程的改进以及后训练方案的创新,phi-4 相对于其规模实现了强劲的性能——尤其是在以推理为重点的基准上。
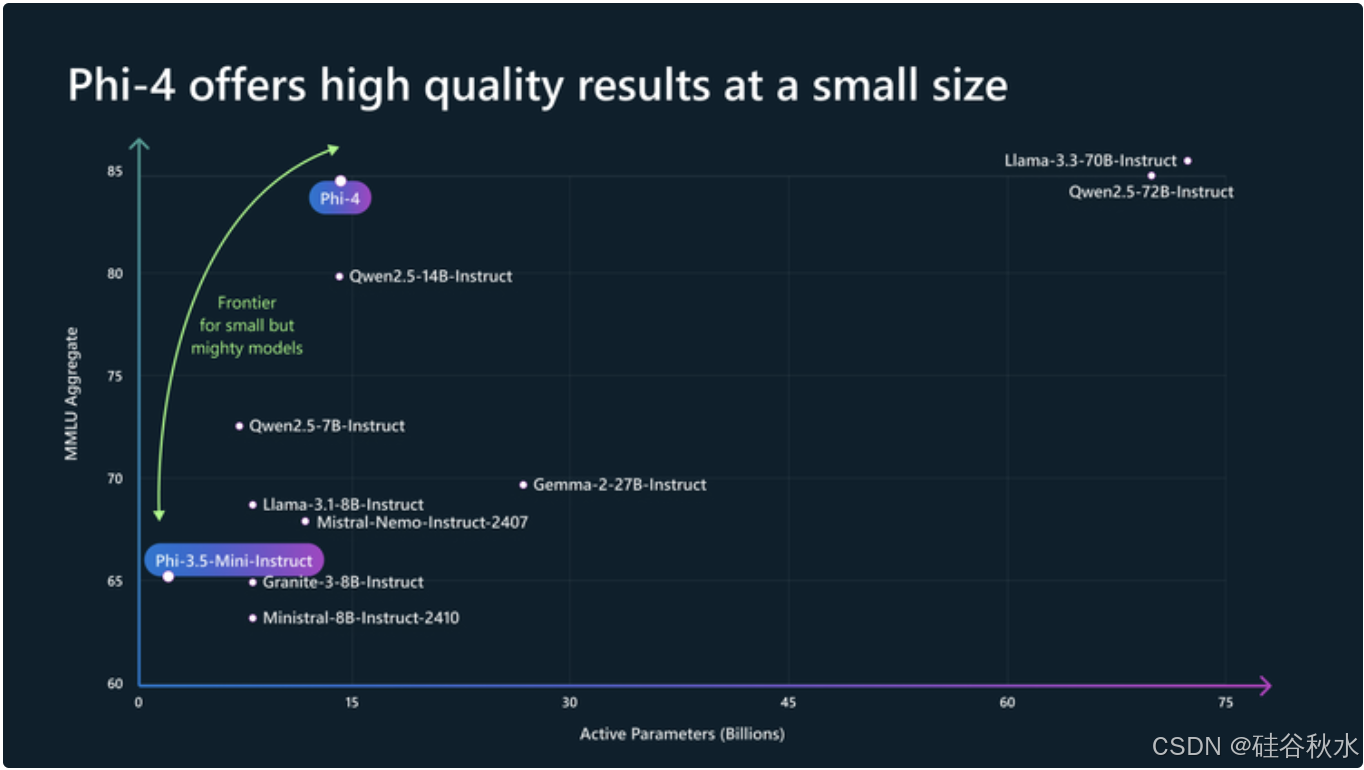
大语言模型 (LLM) 的最新进展表明,数据质量的显著提高可以与传统上通过扩展模型和数据集大小实现的性能提升相媲美,有时甚至超越。在 Phi 系列 [GZA+23、LBE+23、JBA+23、AAA+24] 成功的基础上,微软推出 phi-4,一个 140 亿参数的模型,通过为推理任务引入合成数据生成方法、优化训练课程和数据混合以及在训练后引入新技术,进一步提高小规模语言模型的性能。
合成数据构成 phi-4 训练数据的大部分,并使用多种技术生成,包括多智体提示、自我修订工作流和指令逆转。这些方法可以构建数据集,从而在模型中引入更强的推理和解决问题的能力,解决传统无监督数据集中的一些弱点。 phi-4 中的合成数据在后训练中也发挥着至关重要的作用,其中采用诸如拒绝采样和直接偏好优化 (DPO) 方法来改进模型的输出。
数据方法
合成数据的目的
合成数据作为预训练的重要组成部分正变得越来越普遍,Phi -系列模型也一直强调合成数据的重要性。合成数据并不是有机数据的廉价替代品,而是比有机数据有几个直接的优势。
语言模型生成的每个tokens都是由前面的 tokens预测的,这使得模型更容易遵循由此产生的推理模式。通过这种方式,合成数据可以充当一种“填鸭式”的形式,以易于消化和以进步为导向的方式提出挑战。
合成数据通常更接近期望模型生成的输出格式。对此类数据进行训练有助于将模型的预训练体验与推理过程中遇到的场景保持一致。这种一致性可确保生成过程中看到的上下文相对于模型预训练的数据保持分布一致。
预训练和中期训练的合成数据
用于生成 phi-4 合成数据集的新方法包括:
• 种子优选:合成数据集生成从来自多个域的高质量种子开始。这些精心策划的种子为合成数据生成提供了基础,这样创建针对模型训练目标量身定制的练习、讨论和推理任务成为可能。
- 基于 Web 和代码的种子:从网页、书籍和代码存储库中提取摘录和片段,重点关注具有高复杂性、推理深度和教育价值的内容。为了确保质量,采用两步过滤流程:首先,识别具有强大教育潜力的页面;其次,将选定的页面分成段落,并根据其事实和推理内容对每个段落进行评分。
- 问题数据集:从网站、论坛和问答平台收集大量问题。然后使用基于多元化的技术过滤这些问题以平衡难度。具体来说,为每个问题生成多个独立答案,并应用多数投票来评估答案的一致性。丢弃所有答案一致(表明问题太简单)或答案完全不一致(表明问题太难或含糊)的问题。此过滤过程会产生一个问题数据集,这些问题既挑战模型的推理和解决问题的能力,又可接近性。在基于拒绝抽样的生成中,使用多个答案代替基本事实。
- 从不同来源创建问答对:用于种子策划的另一种技术是利用语言模型从书籍、科学论文和代码等有机来源中提取问答对。这种方法不依赖于仅仅识别文本中的明确问答对。相反,它涉及一个旨在检测文本中的推理链或逻辑进展的流水线。语言模型识别推理或解决问题过程中的关键步骤,并将它们重新表述为问题和相应的答案。其实验表明,如果做得正确,对结果内容进行训练比对原始内容进行训练更有效(就学术和内部基准的改进而言)。
• 重写和增强:通过多步提示工作流将种子转换为合成数据。这包括将给定段落中的大部分有用内容重写为练习、讨论或结构化推理任务。
• 自我修订:然后通过反馈循环迭代细化初始响应,在该反馈循环中,模型会批评并随后改进其自身输出,并以专注于推理和事实准确性的规则为指导。
• 代码和其他任务的指令反转:为了增强模型从指令生成输出的能力,使用指令反转技术。例如,从代码数据语料库中获取现有的代码片段,并使用它来生成包含问题描述或任务提示的相应指令。生成的合成数据对的结构是指令出现在代码之前。只有原始代码和再生代码之间保真度高的数据才会被保留,从而确保指令和输出之间的一致性。此方法可以推广到其他目标用例。
• 代码和其他科学数据的验证:适当时,会结合测试来验证推理能力强的合成数据集。合成代码数据通过执行循环和测试进行验证。对于科学数据集,问题从科学资料中提取,采用旨在确保高相关性、扎实性和难度平衡的方法。
网络和QA数据的挑选和滤波
通过查看公共网站、依赖现有数据集和获取外部数据集收集数千万个高质量的有机问题和解决方案。从以前的模型中获得的经验表明,问答数据对各种能力(例如数学推理和学业成绩)贡献巨大。
几种方法对有机问题的数据集进行合成扩充,以获得更大的数据集。虽然这些重写的问题提高了模型的能力,但收益并不明显。收集到的问题中有相当一部分缺乏准确的解决方案。为了解决这个问题,用合成生成的答案替换原答案,并使用多数投票来提高准确性。所有收集到的问题和解决方案都经过了彻底的净化过程,以确保与测试集没有重叠。
为 phi-4 收集各种高质量的有机数据源,优先考虑推理密集且细致入微的材料(例如学术论文、教育论坛和编程教程)。除了直接对本文进行训练外,还使用各种网络源作为专门的合成数据生成流水线的种子。干净、正确的自然数据对于播种合成数据绝对至关重要:微小的错误可能会导致生成的合成文档质量严重下降。因此,投入大量资金来完美管理网络数据。
后训练数据
包括两部分:SFT数据和DPO。
预训练
预训练的数据组合
phi-3 模型系列采用两步策略进行训练。大多数训练tokens用于训练的第 1 步,主要由过滤后的 Web 数据组成。第 2 步使用数据混合进行训练,主要由合成tokens和极少量的超-过滤和推理-密集型 Web 数据组成。随着合成数据的大小和复杂性的增加,使用非合成 tokens 对 phi-3 系列模型大小的收益略有下降。
受合成数据这种规模化行为的启发,仅针对合成数据训练一个 13B 参数模型,用于消融目的 - 该模型对每个数据源进行 20 多次重复。为了进行消融,将合成数据划分为Web重写,相对于所有其他类型合成数据,包括更多过滤Web内容的直接重写。如表所示将之前的 phi-3-medium 模型与完全在合成数据上训练的新模型进行比较。

在整个训练过程中,尽管 epoch 有所增加,但所有基准测试都在持续改进,并且大多数基准测试都比 phi-3 有所改进。然而,与知识相关的基准测试,如 1-shot triviaqa (TQA),显示出合成模型低于标准的巨大差距。这些观察结果促使重新思考Web数据在数据混合中的作用。
数据混合
为了针对给定的训练tokens预算设计预训练数据混合,搜索来自各种来源的不同tokens分配,即 1) 合成、2) Web重写 5、3) 过滤后的Web(分为推理和知识密集型部分)、4) 有针对性的获取和有机数据(例如学术数据、书籍和论坛)和 5) 代码数据。
用 1T tokens 的较短token范围进行消融以得出数据混合。这些消融依赖于建立的短期训练与长期训练的高秩相关性结果,直至数据源的过拟合饱和阈值。此外, 7B 和 14B 模型在不同数据混合上的性能之间存在高秩相关性,前提是数据混合之间的距离足够大。这样能够在 7B 规模上进行实验,并将结果转移到 phi-4。冻结来自目标采集和代码类别的tokens比例,并更改合成、Web 和 Web 重写群的tokens比例。
下表总结了手工挑选的消融结果,并与用于最终训练运行的数据混合进行了比较。由于合成数据的质量较高,因此在三个类别之间均匀分配tokens并不是最优的,并且唯一显示 Web 数据明显有益的基准是 TQA。虽然表格第 2 行和第 3 行合成-重度的变化略优于所选的最终数据混合,但整合目标和知识-重度过滤的 Web 数据源,改进知识基准,平衡所有模型功能。随着模型经历后训练阶段,所选数据混合和合成-重度数据之间差距,在运行时很大程度上缩小了。预训练数据混合的端到端优化,也考虑到后训练的影响,是一个有趣的未来研究领域。

中期训练
phi-4 包括一个中期训练阶段,其中上下文长度从原来的 4K 增加到 16K。进行了几次消融,研究数据对长上下文性能的作用。具体来说,尝试本质上是长上下文的数据源,并将它们与人工创建的长上下文数据进行比较,其中样本被填充在一起进入序列。前者在较长的上下文任务中表现更好。
受此启发,进一步过滤高质量非合成数据集(即学术、书籍和代码数据),以分离 8K 上下文以上的样本。然后,增加长度为 16K 或更高的数据子集的权重。还创建满足 > 4K 序列要求的新合成数据集。最终的数据混合包括 30% 新策划的较长上下文数据和 70% 来自预训练阶段的回忆tokens。为了适应更长的上下文,按照 [AI23b] 将ROPE 位置编码的基频增加到 250K。与预训练阶段相比,将最大学习率降低 10 倍,并训练总共 2500 亿个 token。
后训练
SFT
在此阶段,以 10^−6 的学习率对预训练模型进行微调,微调所用数据来自不同领域的高质量数据,包括数学、编码、推理、对话、模型身份和安全。还添加 40 种语言的多语言数据。在此阶段使用大约 80 亿个 token 数据,所有数据均采用 chatml 格式。
DPO
用 DPO [RSM+23] 使模型与人类偏好保持一致,并通过期望-不期望输出对,使模型远离不良行为。DPO 数据涵盖聊天格式数据、推理和负责任的人工智能 (RAI) 数据,并在数学、编码、推理、稳健性和安全性方面改进模型。对 SFT 模型进行两轮 DPO。引入一种技术,即枢纽 token 搜索 (PTS),为第一轮 DPO 生成 DPO 对。下表提供了第一轮数据混合的详细信息。
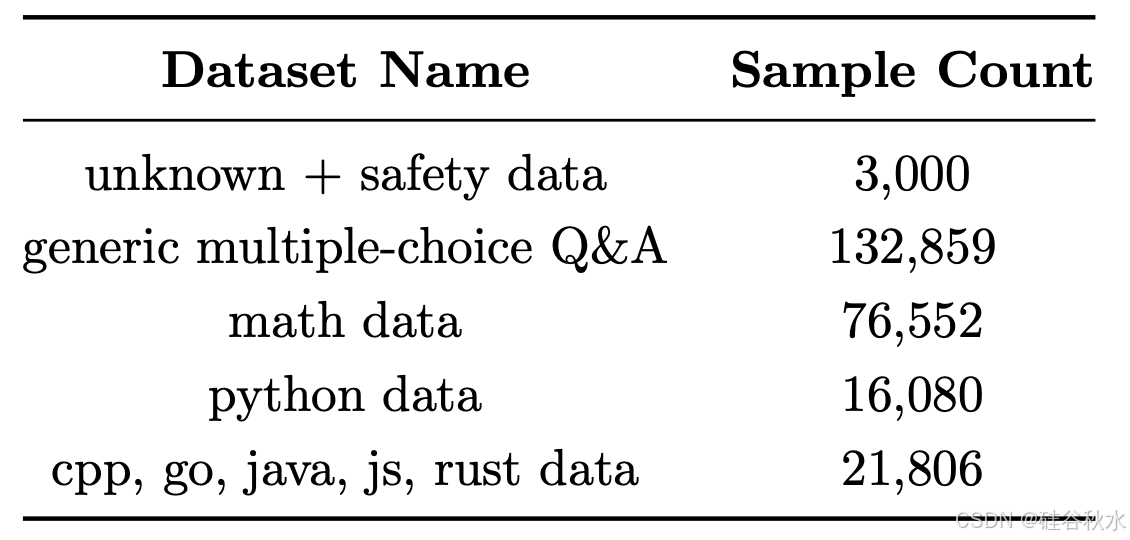
第二轮,称之为裁判-引导的 DPO,收集大约 850k 对期望和不期望的输出。提示来自各种公开可用的指令调整数据集,还包括与安全和负责任的人工智能 (RAI) 相关的提示。接下来,对于每个提示,从 GPT-4o、GPT-4t 和模型生成响应。根据这些回答,创建各种 DPO 对组合,并使用 GPT-4o 作为裁判,为给定的一对回答标注正或负。对于给定的一对回答,每个助手的回答都会根据准确性、风格和细节获得一个分数。将准确度或总体(准确度、风格和细节的平均值)得分较高的回答,标记为正的回答。
枢纽 token 搜索 (PTS)
考虑一个生成模型,它对给定的提示生成一个个token的响应。对于生成的每个token(对应于模型响应的前缀),可以考虑给定该前缀时模型答案正确的条件概率,以及该概率相对于该token的增量(换句话说,生成该token之前和之后正确的概率差异)。通常情况下,整体正确性高度依赖于成功生成少量枢纽token。这些枢纽token,对解决方案的进程具有巨大影响。
当两个文本彼此存在很大偏差时,比较它们各自的下一个token对数概率(如在 DPO 中所做的那样)并不是很有意义。相反,信号应该来自两个文本开始相互分歧之后的第一个token。
为了减轻这些影响,采用 PTS 的方法来生成偏好数据,该方法专门针对孤立的枢纽token,从而创建 DPO 对,其中偏好优化针对单个token生效。
PTS 确定一个补全 token 序列 T/full = t1, t2, . . . 的点,对于某个用户查询 Q,下一个token t/i 对成功概率 p(success ∣ t/1 , . . . , t/i ) 有显著影响。PTS 通过从 Q + t/1, . . . , t/i 开始对补全采样来估计这些概率,并使用 Q 的 oracle 检查它们的正确性。如图显示了该算法的基本实例。

其中过程 Subdivide 递归地将一个序列拆分为段 t/i, . . , t/j 直到每个段的概率变化 ∣p(success∣t1, …, ti−1) − p(success∣t1, …, tj)∣ 低于阈值p/gap 或者该段只是一个单个 token。成功概率发生急剧变化的 token 将保留为枢纽 token。将 Q+t/1,…,t/i−1 作为查询,将增加/减少 p(success∣t1, …, ti−1, t/acc/rej) 的单个 token, tacc 和 trej ,分别作为接受和拒绝的补全,将枢纽 token 转换为偏好数据。PTS 的二分搜索算法并不总能保证找到所有枢纽token,但它只找到枢纽 token,并且如果在解决方案的过程中成功概率接近单调,它会找到所有枢纽 token。
幻觉缓解
生成 SFT 数据和 DPO 对,来缓解幻觉。如果模型不知道答案,宁愿它拒绝回答,也不愿制造幻觉。
后训练消融
一般来说,枢纽 token DPO 在推理繁重的任务(GPQA、MATH)上最有用,而裁判指导的 DPO 对于本身涉及 GPT-4 裁判的基准特别有用:ArenaHard。这两种方法是互补的。
基准考虑
虽然学术基准被广泛用于衡量 LLM 进步的进展,但它们受到一些限制,可能无法揭示模型的真正能力和弱点。这些限制包括:
• 数据污染。
• 技能范围有限。
• 基于生成的基准测试中偏差。
• 多项选择题的局限性。
为了解决这些问题,维护一个名为 PhiBench 的内部基准测试,该基准测试旨在评估认为对 phi-4 开发至关重要的各种技能和推理能力。基准的目标包括:
- 原创性。
- 技能多样性。
- 生成任务的严格评分。
PhiBench 在优化 phi-4 中发挥了核心作用。用它来指导关于数据集混合和超参选择的决策,以实现更有效的后训练技术。PhiBench 还用于执行高信号研究,以识别模型中的弱点并为新传入数据源提供反馈。
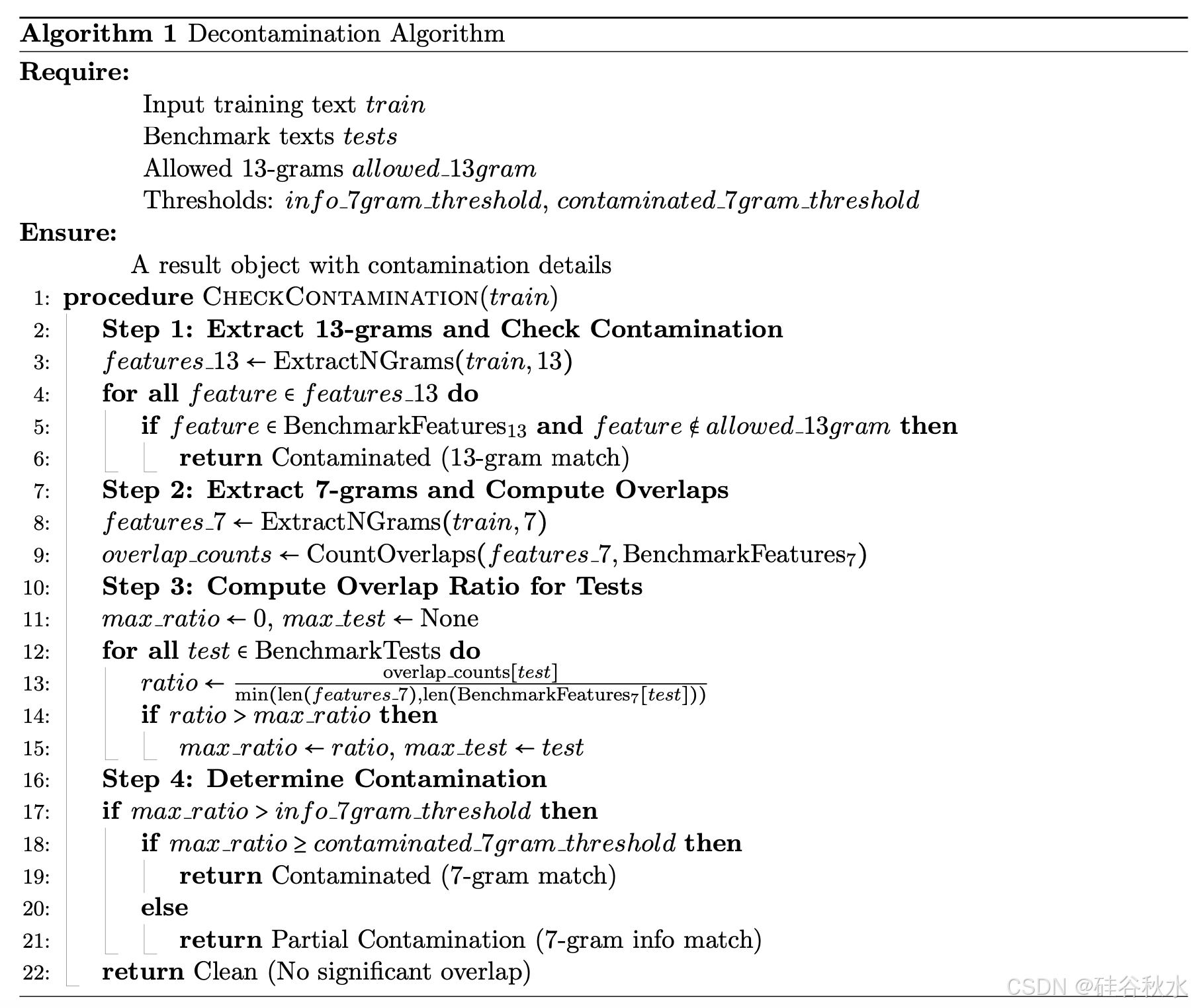
去污/净化算法如下:

















 714
714

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









