










25年1月来自伯克利 BAIR 的论文“Beyond Sight: Finetuning Generalist Robot Policies with Heterogeneous Sensors via Language Grounding”。
与世界互动是一种多感官体验:实现有效的通用交互需要利用所有可用的模态——包括视觉、触觉和听觉——来填补部分观察的空白。例如,当视线受阻而无法伸手进包里时,机器人应该依靠触觉和听觉。然而,最先进的通才机器人策略通常是在大型数据集上进行训练的,这样仅根据视觉和本体感受观察来预测机器人的动作。这项工作提出 FuSe,它利用自然语言作为通用的跨模态落地,能够在难以获得大型数据集的异构传感器模态上对视觉运动通才策略进行微调。将多模态对比损失与基于感官的语言生成损失相结合,以编码高级语义。在机器人操作的背景下, FuSe 能够在零样本设置下执行需要在视觉、触觉和声音等模态上联合推理的具有挑战性的任务,例如多模态提示、组合跨模态提示和与其交互目标的描述。相同的方法适用于截然不同的通才策略,包括基于扩散的通才策略和大型视觉-语言-动作 (VLA) 模型。现实世界中的大量实验表明,与所有考虑的基线相比,FuSe 能够将成功率提高 20% 以上。
如图所示 FuSe 微调的描述:
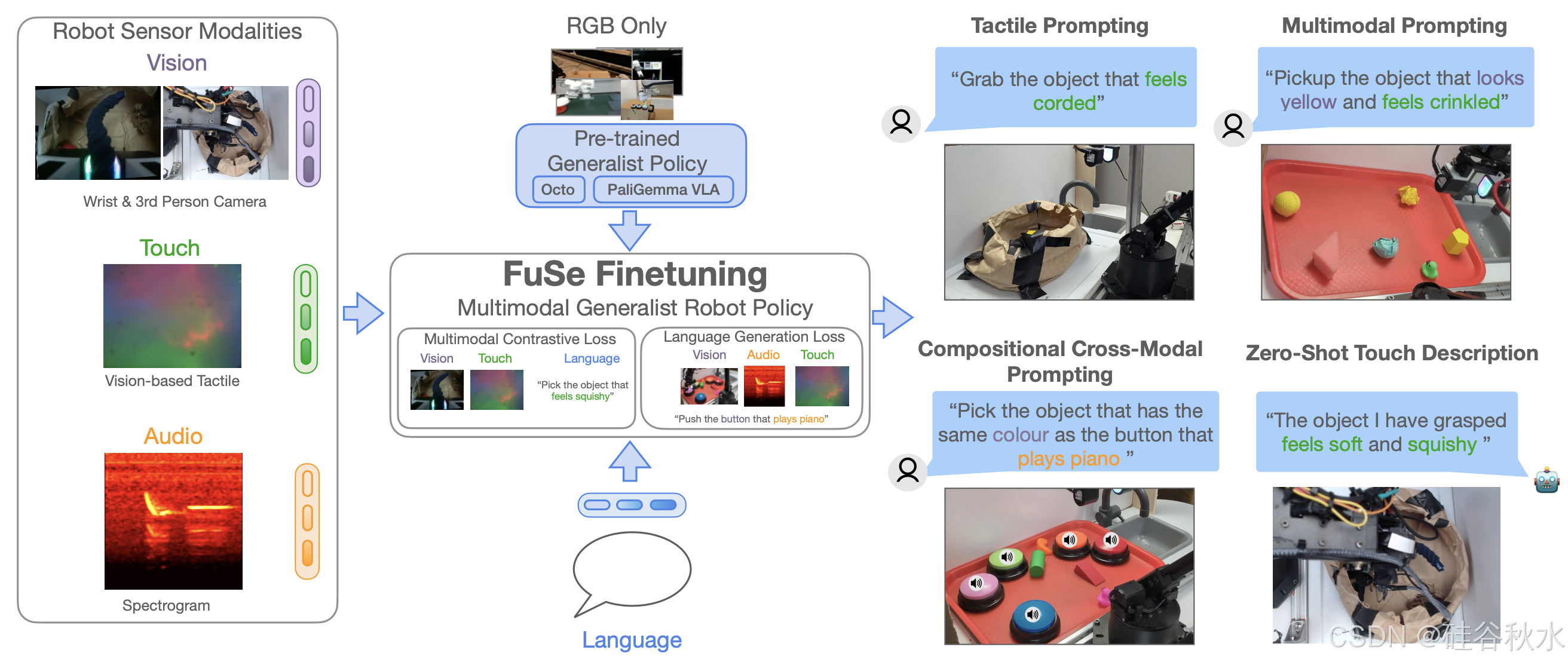
智能生物有能力无缝地结合各种感官反馈,从而使它们能够有效地与物理世界互动。除了视觉之外,人类还依赖触觉和听觉反馈来操纵目标[1],[2],因为它们提供关于目标属性的丰富补充信息,特别是当单靠视觉信息可能不足以完成任务时,比如定位在袋子里的钥匙 [3]。这与最先进的“通才”机器人策略 [4]–[8] 形成鲜明对比,这些策略从大量机器人数据集 [9]–[13] 中吸收知识,但通常仅依赖于视觉和本体感受观察执行各种各样的任务。
限制基于真正异构数据的通才机器人策略开发的主要因素是,虽然几乎所有的机器人数据集都包含视觉和本体感受信息,但只有一小部分数据集包含其他形式的感官数据 [14]–[16]。这就引出了一个问题:如何才能保留在大量数据上预训练的通才机器人策略泛化能力,同时将其语义知识与不易获得大型数据集的异构感官数据相连接?
先前的研究表明,自然语言可以为混合模态模型提供一个通用接口,即使它们是在重叠最少的数据域上进行训练的[17]–[23]。此外,将人类语言与多模态感知和动作自然地联系起来,可以使用混合多种不同模态概念的开放词汇查询来索引目标(“拿起柔软的红色物体”)。然而,由于数据稀缺,尤其是缺乏包括对多模态感知和低级机器人动作进行联合推理的数据,将触觉或听觉等多种感知模式融入机器人策略,迄今为止仍被证明具有挑战性[2],[3 ]、[14]–[16]、[24]–[27]。
通才机器人策略
通才机器人策略,已显示出利用多样化大规模数据实现机器人任务泛化的潜力 [4]–[8], [22], [29]。这些策略利用最近向社区开放的大型机器人数据集 [9]、[10]、[30],并且最常使用定义任务的语言指令进行查询。在某些情况下,机器人动作与视觉语言融合模型(VLM)主干[5],[7],[22],[31],通过对互联网规模数据进行预训练,提高泛化能力。
然而,虽然一些最近引入的模型 [4]、[8] 可以自然地处理灵活的观察,但是包含其他感官模式(如触觉或听觉)的数据集的稀缺性,限制它们的能力主要局限于视觉输入。
机器人中的多模态推理
多模态性旨在利用不同传感器之间的互补性来增强自主机器人策略的能力。它的优点已在文献中反复得到证明,从而带来在性能[2],[3],[3],[25],[32]-[41],泛化能力[33],[42],或鲁棒性的提高[39], [43]。
尽管有这样的证据,但只有少数方法除了视觉和本体感觉之外还采用传感器模态。这反映在向社区提供的机器人数据集中。例如,最大的机器人数据集 Open X-Embodiment [9] (OXE) 并不包含触觉或声音作为其默认感官模式的一部分。一些值得注意的例外,包括最近的研究[14],[24],[44],这些研究试图将视觉、语言和触觉结合起来完成感知任务。然而,通过这些研究提供的大多数可用数据集并不包括机器人动作,从而限制它们在策略训练和执行物理上落地多模态任务中的适用性。
最先进的通用机器人策略通常依靠视觉、语言和机器人动作作为训练方式,这限制了它们在部分可观察场景中的适用性,在这些场景中,任务无法仅通过视觉来完成。本文提出的方案,FuSe,将异构感官数据融合到通才机器人策略中。具体来说,对这些策略进行微调,以扩展它们的语义理解,包括触觉和声音等额外的感知方式,同时保留它们预训练的知识。
通过提出两个辅助损失,将异构观察与自然语言进行对比并从观察中生成语言,能够将各种感知模式与预训练的通才机器人策略的语义知识联系起来。使用 Octo [4](一种基于 Transformer 的预训练策略)作为本文主要实验的主干模型,但相同的微调方法适用于一个基于一 PaliGemma [28] VLM 主干的 3B VLA模型 。训练架构如图所示。
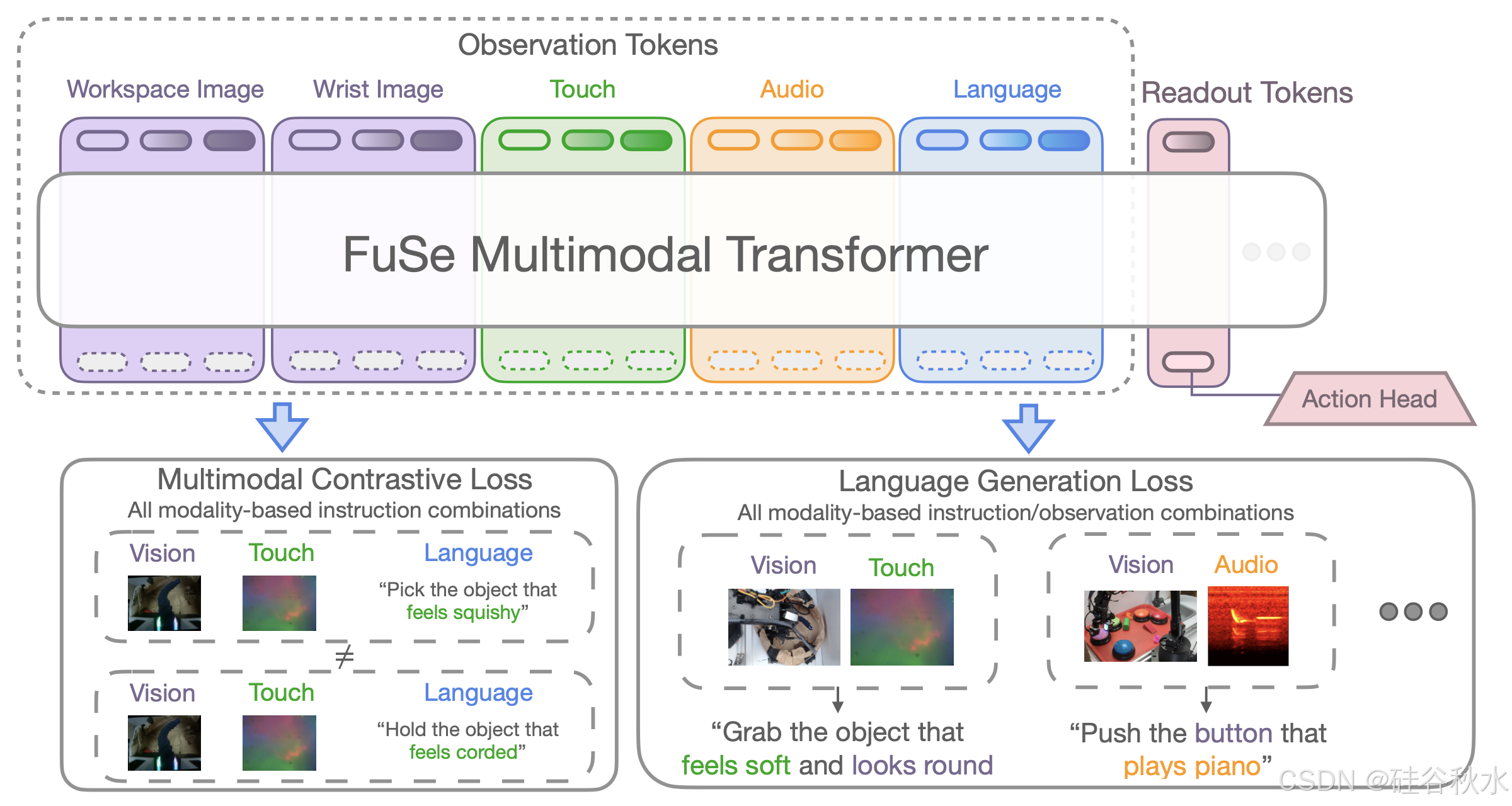
这种微调策略带来三个主要挑战,即:(i)新模态的特征提取器(编码器)权重通常需要从小数据集中有效地学习; (ii)微调模型在经验上倾向于主要依赖于预训练模式,而忽略新的传感器; (iii)新跨模态提示能力依赖于模态特定的注释,例如“目标感觉柔软而有弹性”。
触觉编码器。为了考虑较小的微调数据集大小,用预训练的触觉编码器并与主干 Octo 架构一起对其进行微调。具体来说,用 TVL 编码器 [14],该编码器通过跨视觉、语言和触觉模态对,采用对比学习进行预训练。通过同一个 TVL 编码器分别提供所有触觉图像(机器人设置中有两个)。
音频编码器。由于原始音频波形高维且噪声较大,对音频数据进行处理以构建频谱图,如先前的研究 [3]、[45]–[47] 中所述。然后将声谱图作为常规图像处理,并输入到 ResNet26 编码器 [48]。
辅助损失。如上所述,一种简单的方法只是使用基于额外传感器数据的均方误差 (MSE) 模仿损失 L_BC ,对预训练的通用策略进行微调,这会导致该策略过度依赖其预训练的模态,而忽略新模态。通过引入两个额外的损失来克服这一限制,充分利用多模态性并将预训练通才策略的语义知识与未见过的传感器模态联系起来:
1)多模态对比损失:引入一种损失,旨在通过 CLIP-风格的对比学习将各种语言指令与观察结果对齐 [49]。从高层次上讲,它旨在最大化同一场景不同模态和语义之间的相互信息。具体来说,通过将所有模态再次输入Transformer并通过多头注意层将它们组合起来,从而构建一个观察嵌入。然后,计算由组合不同可用模态而产生的每个可能指令 CLIP-风格损失。这些损失最终被平均,以形成组合的多模态对比损失 L_contrast。
2)多模态生成损失:设计一个生成网络,作为主干模型的附加头。实际上,对于每一种可能的模态组合,都会构建一个如上所述的观察嵌入,并将其输入生成头。然后,通过将头输出与适当的语言指令进行比较来计算辅助交叉-熵损失 L_gen。用单个Transformer作为所有可能模态组合的生成头,并使用模态tokens来区分输入模态。
最终的损失由 L = L_BC + β L_gen + λL_contrast 给出,其中对比损失和生成损失加在一起为在训练期间 MSE 的动作损失。
语言改述。如前所述,跨模态提示功能需要特定于模态的注释,例如“该目标感觉柔软并且看起来很圆”。用事后语言注释来标注通过异构传感器收集的机器人轨迹。用模板语言注释这些轨迹,能够根据多个传感器输入创建增强功能,“目标感觉柔软并且是红色的”或“目标感觉是金属的并且听起来叮当作响”。然而,在测试时,希望用户用自由-形式的语言来指导策略。为了增加可能的输入指令范围,通过查询大语言模型 ChatGPT [50] 来扩充数据集中的指令,以生成保留原始语义的原始模板改写。
实施细节。在 v5e-128 TPU pod 上对所有模型进行 50,000 步训练,批次大小为 1024。使用余弦学习率调度程序,其中有 2000 个预热步骤,峰值为 3×10−4。语言改写缓冲区包含针对每种可能模态组合的 20 个不同模板。在所有实验中设置 β = 1 和 λ = 1。
真实机器人设置和训练数据如下。
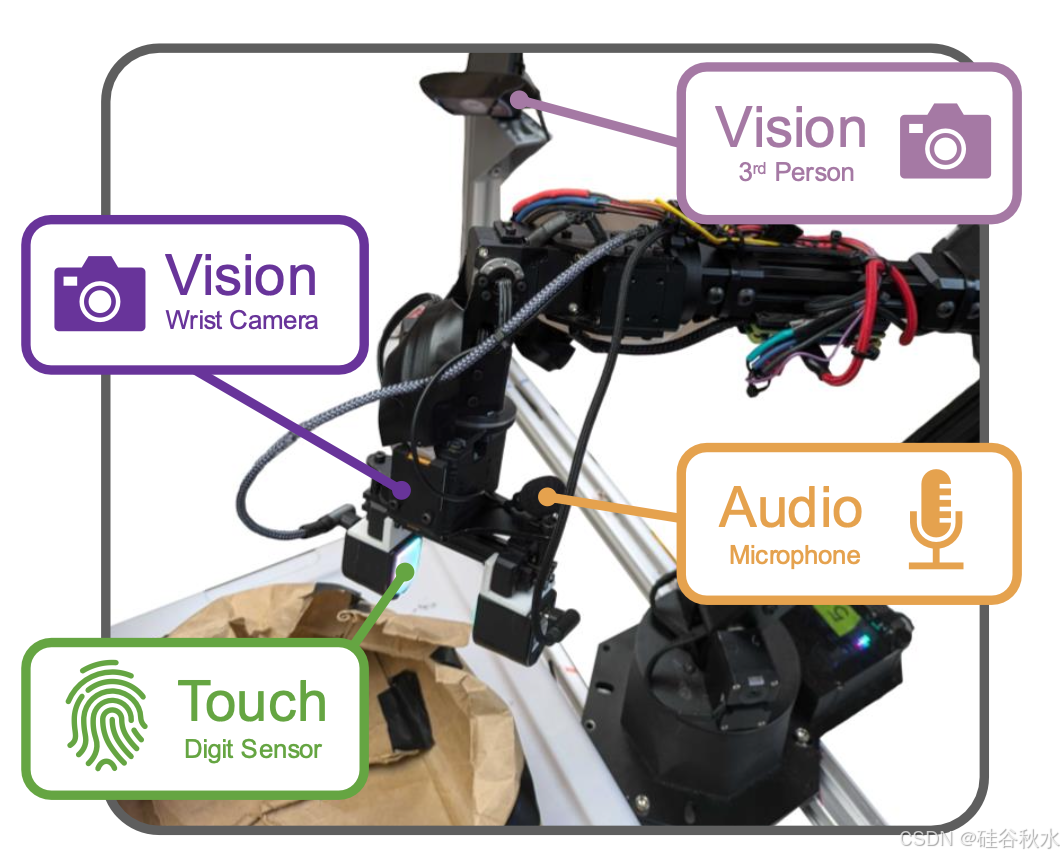
所有的实验都采用 WidowX 250 6-DoF 机械臂。机器人通过频率为 5 Hz 的增量末端执行器位置命令进行控制。该系统配备第三人称视角 RGB 摄像头、腕部 RGB 摄像头、夹持器手指处的两个 DIGIT 触觉传感器、标准麦克风以及9-DoF IMU。针对三个不同的任务进行实验,如下所述。对于抓取场景,对训练数据集中存在的 24 个目标以及 32 个未见过的测试目标进行评估;对于按钮按下任务,评估训练数据集中看到的 6 个按钮和 18 个干扰物/抓取目标中的 13 个,以及两个未见过的按钮和 12 个未见过的干扰物。如图可视化使用的训练和测试目标。

通过对 5 种不同的部署运行相同的场景,针对每个任务的几种不同场景(例如,不同的目标和干扰物)评估每个模型。
用 Meta Quest 2 VR 头戴式设备通过遥操作收集 26,866 条轨迹的数据集。每条轨迹都标有模板语言指令。两个抓握任务(桌面和购物袋)包含视觉、触觉和动作数据,而按钮按下任务还包括声音。视觉观察以 640x480 的分辨率记录,而 DIGIT 图像以 320x240 的分辨率记录。遵循先前的研究,从触觉观察中减去静态的“背景”图像,以强调与零变形状态的偏差,并减少 DIGIT 实例之间的系统差异 [2]。音频观测包括最近的 1 秒麦克风样本,以 44,100Hz 的频率记录。如图所示形象地展示机器人感官装置。

















 3713
3713

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









