










25年3月来自Nvidia的论文“GR00T N1: An Open Foundation Model for Generalist Humanoid Robots”。
通用机器人需要多功能的身体和聪明的头脑。人形机器人的最新进展显示出作为在人类世界中构建通才自主性硬件平台的巨大潜力。在大量多样化数据源上训练的机器人基础模型,对于使机器人能够推理新情况、稳健地处理现实世界的变化以及快速学习新任务至关重要。为此,Nvidia推出 GR00T N1,一种人形机器人的开放式基础模型。GR00T N1 是一种具有双系统架构的视觉-语言-动作 (VLA) 模型。视觉语言模块(系统 2)通过视觉和语言指令解释环境。后续的扩散 Transformer 模块(系统 1)实时生成流运动动作。这两个模块紧密耦合并进行端到端联合训练。用真实机器人轨迹、人类视频和合成生成数据集的异构混合来训练 GR00T N1。该通才机器人模型 GR00T N1 在多个机器人实例的标准模拟基准测试中超越最先进的模仿学习基线。此外,该模型部署在 Fourier GR-1 人形机器人上,用于语言调节的双手操作任务,实现强大的性能和高数据效率。
。。。。。。。继续。。。。。。。
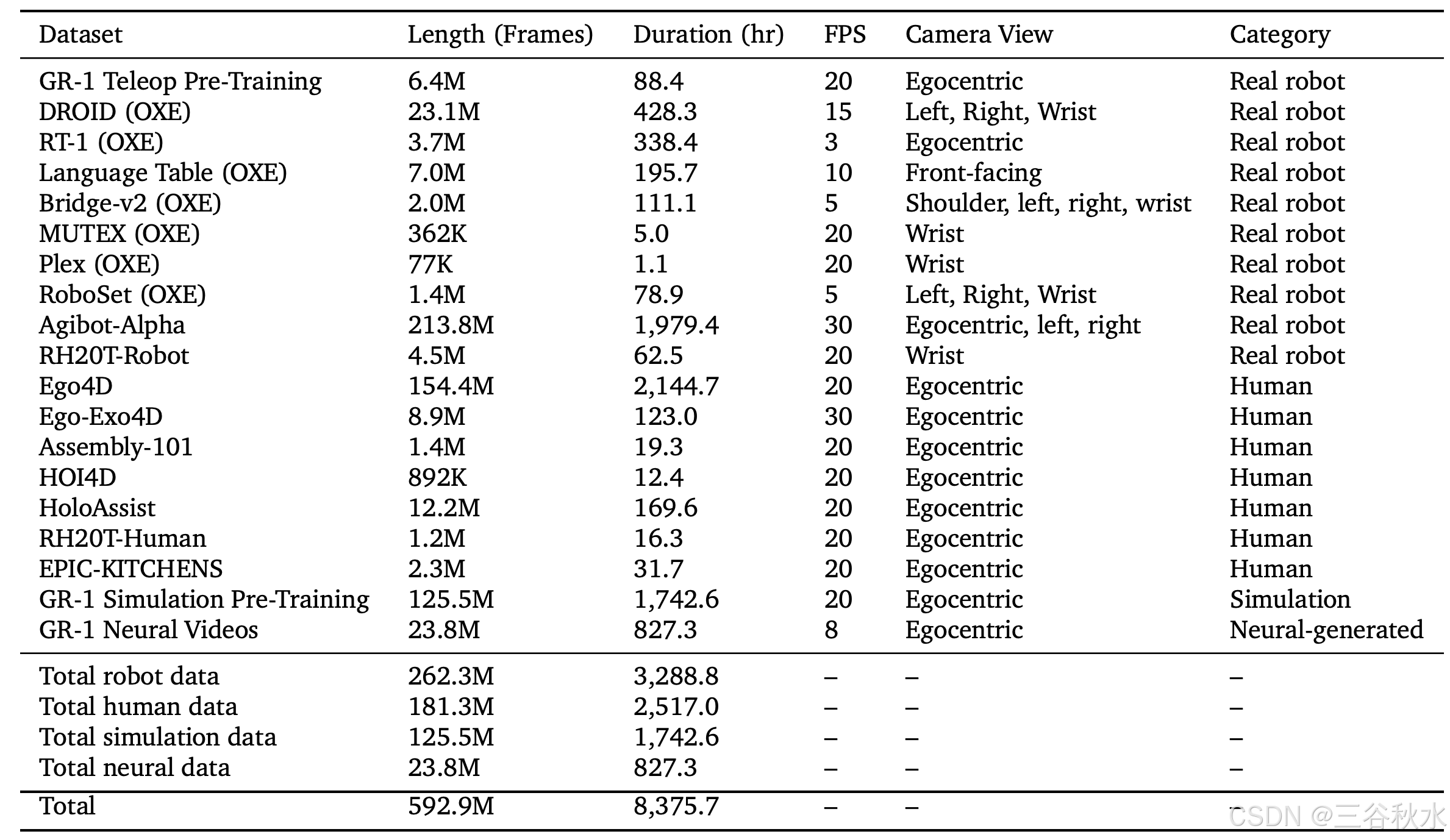
预训练语料库分为三个主要类别:真实机器人数据集、合成数据集和人类视频数据集。这些大致分别对应于数据金字塔的顶部、中间和底部。合成数据集由模拟轨迹和神经轨迹组成。下表总结了训练数据生成策略及其相应的适用数据源。

下表提供预训练数据集的完整统计数据(帧数、小时数和摄像机视图数):
真实世界数据集
用以下真实世界机器人数据集:
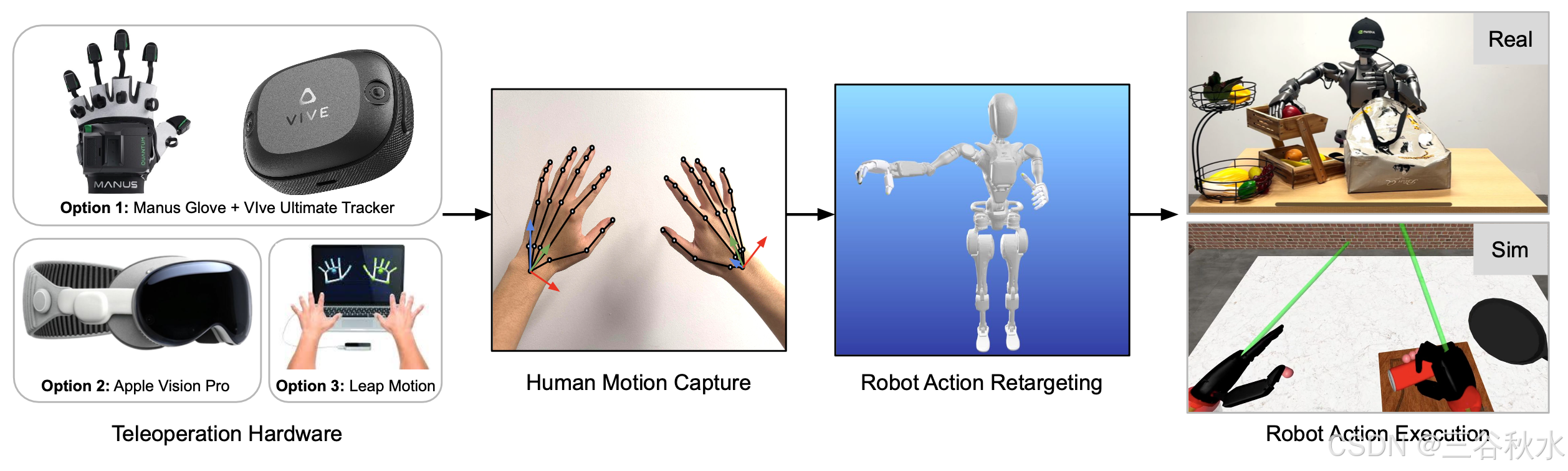
- GR00T N1 人形机器人预训练数据集。内部收集的数据集涵盖广泛的一般操作任务,重点关注通过遥操作的 Fourier GR1。利用 VIVE Ultimate Tracker 来捕捉遥操作员的手腕姿势,而 Xsens Metagloves 则跟踪手指运动。还探索其他遥操作硬件选项,包括 Apple Vision Pro 和 Leap Motion(如图所示)。然后通过逆运动学将记录的人类动作重定位为人形机器人动作。实时遥操作以 20Hz 的控制频率运行。除了机器人的动作外,还从头戴式摄像头捕捉每一步的图像,以及人类的低维本体感受和动作。该数据集包括细粒度注释,其中详细描述抓取、移动和放置等原子动作,以及粗粒度注释,其中将细粒度动作序列聚合为更高级的任务表示。这种分层结构支持学习精确的运动控制和高级任务推理。
- Open X-Embodiment。Open X-Embodiment Collaboration (2024) 是一个广泛使用的跨机器人操作数据集。包括 RT-1(Brohan,2022)、Bridge-v2(Walke,2023)、Language Table(Lynch,2022)、DROID(Khazatsky,2024)、MUTEX(Shah,2023)、RoboSet(Bharadhwaj,2024)和 Plex(Thomas,2023),提供涵盖各种操作任务、语言条件控制和机器人与环境交互的多样化数据集。
- AgiBot-Alpha。AgiBot-World-Contributors(2025)是一个来自 100 个机器人轨迹的大规模数据集。使用启动训练运行时可用的 140,000 条轨迹。数据集涵盖细粒度操作、工具使用和多机器人协作。
合成数据集
合成数据集包括 1) 物理模拟器中少量人类演示自动加倍为模拟轨迹和 2) 从现成神经生成模型生成的视频中得出神经轨迹。
模拟轨迹
除了现实世界的数据集外,还提供在模拟中生成的大规模合成数据集,模拟任务包括执行广泛桌面重新排列任务的人形机器人,并具有大量逼真的 3D 资产。在 RoboCasa 模拟框架 (Nasiriany,2024) 下构建这些任务。广义上讲,任务遵循“从 B 到 C 重新排列 A”的行为,其中 A 对应于一个目标,B 和 C 表示环境中的源位置和目标位置。源和目标位置是盘子、篮子、餐垫和架子等容器,机器人必须在源容器和目标容器的不同组合之间重新排列目标。总体而言,预训练模拟数据集具有 54 种独特的源和目标容器类别组合。将物体和容器放置在桌子上的随机位置,并在场景中额外加入干扰物体和容器。干扰物要求模型注意任务语言以执行所需的行为。
用 DexMimicGen 大规模生成多样化、高质量的训练数据集。数据集以 GR-1 人形机器人为特色,但可以将该系统用于各种机器人。首先使用 Leap Motion 设备通过遥操作收集几十个源演示。Leap Motion 设备跟踪 6-DoF 手腕姿势和手指姿势,重新定位这些值并将它们发送到基于 mink (Zakka,2024)的全身 IK 控制器。根据人类演示,DexMimicGen 将演示处理为以目标为中心的片段,然后转换和组合这些片段以生成新的演示。使用该系统,为预训练任务方案中的每个(源-目标)容器对生成 10,000 个新演示,总共产生 540k 个演示。
神经轨迹
为了生成神经轨迹,在现实世界的 GR00T N1 人形机器人预训练数据集上微调开源图像-到-视频模型。在一个数据集上对模型进行 100 个 epochs 的训练,该数据集包含 3,000 个带有语言注释的现实世界机器人数据样本,每个样本以 480P 分辨率记录并由 81 帧组成。如图所示,模型可以在给定新语言提示的情况下生成高质量的反事实轨迹。此外,该模型在互联网规模的视频数据上进行训练,在处理未见过的初始帧、新物体和新运动模式方面表现出强大的泛化能力。这些视频进一步标注潜动作和基于逆动力学模型(IDM)的伪动作,以进行模型训练。总共生成大约 827 小时的视频;在 L40 GPU 上生成一秒钟的视频需要 2 分钟,在 3,600 个 L40 GPU 上需要大约 105k L40 GPU 小时(约 1.5 天)。
人体视频数据集
包括一组多样化的人体视频数据集。这些数据集不包括显式动作标签,但包含大量人与物体交互序列,捕捉 affordance、任务语义和自然运动模式。这些数据集涵盖广泛的现实世界人类行为,包括抓握、工具使用、烹饪、组装和在自然环境中执行的其他面向任务活动,并提供手与物体交互的详细第一人称视角,如图所示:

视频数据集包括以下内容:
• Ego4D 是一个大规模以自我为中心的视频数据集,其中包括日常活动的各种记录(Grauman,2022);
• Ego-Exo4D 在第一人称录制的同时,添加互补的外向为中心(第三人称)视图(Grauman,2024);
• Assembly-101 专注于复杂的组装任务,提供逐步组装物体的详细视频(Sener,2022);
• EPIC-KITCHENS 包括烹饪活动的第一人称镜头(Damen,2018);
• HOI4D 捕捉人与物体的交互,并逐帧注释以进行分割、手和物体的姿势和动作(Liu,2022);
• HoloAssist 捕捉增强现实环境中的协作和辅助任务(Wang,2023);
• RH20T-Human 包括细粒度操作任务的记录,重点关注各种现实世界场景中的自然手部与物体交互(Fang,2023)。
在一系列不同的模拟和真实基准中评估 GR00T N1 模型。模拟实验是在三个不同的基准上进行的,旨在系统地评估模型在各种机器人具身和操作任务中的有效性。在真实世界实验中,用 GR-1 人形机器人研究该模型在一系列桌面操作任务中的能力。这些实验旨在展示 GR00T N1 从有限数量的人类演示中获得新技能的能力。
模拟基准
模拟实验包括两个来自先前工作的开源基准(Jiang,2024;Nasiriany,2024),以及一套新开发的桌面操作任务,旨在紧密反映真实世界任务设置。精心选择这些基准来评估在不同的机器人具身和不同操作任务中的模型。模型检查点以及公开可用的模拟环境和数据集,确保关键结果的可重复性。如图展示这三个基准中的一些示例任务。

RoboCasa 厨房(24 个任务,RoboCasa)
RoboCasa(Nasiriany,2024)提供一系列模拟厨房环境中的任务。专注于 24 个“原子”任务,这些任务涉及基础感觉运动技能,例如拾取和放置、开门和关门、按按钮、转动水龙头等。对于每个任务,使用公开可用的数据集,其中包含 3000 个 Franka Emika Panda 手臂演示,所有演示均由 MimicGen(Mandlekar,2023)生成。观察空间包括从位于左侧、右侧和手腕处摄像头捕获的三个 RGB 图像。状态表示包括末端执行器和机器人底座的位置和旋转,以及夹持器的状态。动作空间由末端执行器的相对位置和旋转以及夹持器状态定义。遵循 Nasiriany (2024) 概述的相同训练和评估协议。
DexMimicGen 跨具身套件(9 个任务,DexMG)
DexMimicGen(Jiang,2024)包括九个双手灵巧操作任务阵列,需要精确的双臂协调。这些任务一起涵盖三种双手机器人具身:(1)带平行钳口夹持器的双手 Panda 臂:任务包括穿线、零件组装和运输。状态/动作空间由双臂的末端执行器位置和旋转以及夹持器状态组成;(2)带灵巧手的双手 Panda 臂:任务包括盒子清理、抽屉清理和托盘提升。状态/动作空间由双臂和手的末端执行器位置和旋转组成; (3) 具有灵巧双手的 GR-1 人形机器人:任务包括倒水、准备咖啡和分类罐头。状态/动作空间包括双臂和双手的关节位置和旋转,以及腰部和颈部。使用 DexMimicGen 数据生成系统为每个任务生成 1000 个演示,并评估模型泛化到新目标配置的能力。
GR-1 桌面任务(24 个任务,GR-1)
此数据集作为现实世界人形机器人数据集的数字对应物,可进行系统评估,为真实机器人部署的性能提供参考。该基准测试侧重于使用配备 Fourier 灵巧手的 GR-1 人形机器人进行灵巧手控制。与 DexMG 相比,此基准测试具有更多种类的物体和不同的位置。总共模拟 18 个重新排列任务,这些任务的结构与预训练任务类似,即将目标从源重新排列到目标容器。每个任务都涉及容器的独特组合,这些组合在预训练数据中是未见过的。与预训练任务一样,大多数任务都涉及干扰目标和容器,需要模型注意任务语言。另外还有六项任务,涉及将物体放入铰接体(即橱柜、抽屉和微波炉)并关闭它们。观察空间包括一个从位于机器人头部自我中心相机捕获的 RGB 图像。状态/动作空间包括双臂和双手以及腰部和颈部的关节位置和旋转。可选择在数据集中包含用于控制手臂的基于末端执行器动作,因为用于控制全身 IK 控制器的原生动作空间是基于末端执行器的。用 DexMimicGen 系统为每个任务生成 1000 个演示。
真实世界基准
引入一组多样化且精心设计的桌面操作任务,旨在根据人类演示对模型进行评估和后训练。这些任务强调现实世界灵活性的关键方面,包括精确的物体操纵、空间推理、双手协调和多智体协作。将基准仔细分为四种不同的类型,以确保对模型性能进行严格的评估。如图展示来自现实世界基准的一些示例任务:

物体-到-容器拾取和放置(5 个任务,拾取和放置)
此类别评估模型抓取物体并将其放入指定容器的能力,这是机器人操纵的基本能力。任务包括在常见的家用容器(如托盘、盘子、砧板、篮子、餐垫、碗和平底锅)之间转移物体。这些场景测试精细运动技能、空间对齐和对不同物体几何形状的适应性。为了严格评估泛化能力,对见过和未见过物体的模型进行评估。
铰接体操纵(3 个任务,铰接式)
这些任务评估模型操纵铰接式存储隔间的能力。模型必须抓住一个物体,将其放入储物单元(例如木箱、深色橱柜或白色抽屉),然后关闭隔间。这些任务在受限运动控制和有限空间内的精确放置方面带来挑战。泛化通过见过和未见过物体进行测试。
工业物体操作(3 个任务,工业)
为工业场景设计此类别,涉及三个结构化工作流程和基于工具的交互:1) 机械包装:拿起各种机械零件和工具,并将它们放入指定的黄色垃圾箱中;2) 网格杯倾倒:抓住一个装有小型工业部件(例如螺钉和螺栓)的网格杯,并将其内容倒入塑料箱中;3) 圆柱体交接:拿起一个圆柱形物体,将其从一只手转移到另一只手,然后将其放入黄色垃圾箱中。这些任务与现实世界的工业应用非常相似,使它们成为评估结构化环境中灵活性的高度相关基准。
多智体协调(2 个任务,协调)
协作任务需要多个智体之间的同步,强调角色协调和自适应决策:1)协调第 1 部分:拿起一个圆柱体,将其放入网格杯中,然后交给另一个机器人;2)协调第 2 部分:接收机器人将圆柱体放入一个黄色垃圾箱,然后将网格杯中的剩余内容倒入另一个黄色垃圾箱。
这些精心设计的基准引入结构化、目标驱动的交互,以测试模型是否可以无缝适应现实世界的应用。为了构建高质量的后训练数据集,让人类操作员收集特定于任务的数据,持续时间从 15 分钟到 3 小时不等,具体取决于任务的复杂性。然后,过滤掉低质量的轨迹以保持数据完整性。通过整合多种任务要求(从精确的单智体操作到复杂的多智体协调),基准测试为评估类人操作任务中的泛化、适应性和微调控制提供严格的测试平台。
实验设置
评估实验包括在数据有限的环境中对 GR00T N1 和基线模型进行后训练,并评估模拟和真实基准测试中的策略成功率。默认情况下,用全局批量大小 1024 并进行 60k 步训练。对于 DexMimicGen Cross-Embodiment Suite,每个具身包含的任务相对较少,并且整体训练数据有限,对 GR00T-N1-2B 使用较小的批量大小 128。
基线
为了证明 GR00T N1 多样化预训练的有效性,与两个已建立的基线 BC-Transformer(Mandlekar,2021)和扩散策略(Chi,2024)进行比较。在下面描述这两种方法的细节:
• BC-Transformer 是 RoboMimic(Mandlekar,2021)中基于 Transformer 的行为克隆策略。它由用于处理观察序列的 Transformer 架构和用于建模动作分布的高斯混合模型 (GMM) 模块组成。该策略以 10 个观察帧作为输入并预测接下来的 10 个动作。
• 扩散策略(Chi,2024)通过基于扩散的生成过程对动作分布进行建模。它采用 U-Net 架构,逐步消除随机样本中的噪声,以生成以观察序列为条件的精确机器人动作。它以单帧观察结果作为输入,并在一次推理过程中产生 16 个行动步骤。
评估协议
对于模拟基准评估,报告 100 次试验的平均成功率,取最后 5 个检查点的最高分,其中每 500 个训练步骤写入一次检查点,遵循 RoboCasa 的协议(Nasiriany,2024)。
对于真实的机器人评估,采用部分评分系统来捕捉不同执行阶段的模型行为,确保对性能进行细粒度的评估。报告每项任务 10 次试验的平均成功率,但“包装机械”任务除外;对于这项任务,报告在 30 秒的时间限制内,5 个机械零件和工具中有多少个物体被放入箱子中的成功率。由于时间限制,只进行 5 次试验。此外,为了评估模型在低数据条件下的效率,对每个任务从整个数据集中抽取 10% 的子样本,并评估模型是否仍然可以学习有效的行为。

















 1156
1156

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









