










25年1月来自浙江大学的论文“VTAO-BiManip: Masked Visual-Tactile-Action Pre-training with Object Understanding for Bimanual Dexterous Manipulation”。
由于手的自由度高且需要协调,双手灵巧操作仍然是机器人技术中的重大挑战。现有的单手操作技术通常利用人类演示来指导 RL 方法,但无法泛化到涉及多个子技能的复杂双手任务。VTAO-BiManip,是一个新框架,它将视觉-触觉-动作预训练与目标理解相结合,以促进课程 RL 实现类人的双手操作。通过结合手部运动数据来改进先前的学习,为双手协调提供比二元触觉反馈更有效的指导。预训练模型使用掩码的多模态输入来预测未来的动作以及目标的姿势和大小,从而促进跨模态正则化。为了应对多技能学习挑战,引入一种两阶段课程 RL 方法来稳定训练。在瓶盖拧开任务上评估方法,证明它在模拟和现实环境中的有效性。该方法的成功率比现有的视觉-触觉预训练方法高出 20% 以上。
人类可以在日常生活中执行各种复杂的双手任务,而让机器人学习像人类一样的双手操作技能则是一项挑战,因为每只手的自由度 (DoF) 很高,而且双手之间需要协调。算法需要在高维空间中搜索符合物理定律并满足任务要求的双手配置。
解决类似问题时,现有的关于高自由度机器人单手操作的研究 [3]–[6] 利用人类演示的先验知识来应对挑战。在 M2VTP [6] 中,人类操作瓶盖的技能先验知识由视觉-触觉预训练网络学习,并融入强化学习 (RL) 方法中。然而,[6] 中的任务涉及在将瓶子固定在桌子上的情况下转动瓶盖。在本文任务中,需要用左手抓住瓶子并举在空中,而右手进行瓶盖转动,如图(中间)所示。考虑到任务的相似性,将视觉-触觉预训练和 RL 方法 [6] 应用于该任务,通过收集人类双手操作数据并根据两只手改变状态和动作。

然而,在 RL 训练阶段该方法失败。经过数千次迭代后,奖励和成功率曲线仍然接近于零。原因可以归因于两个因素。该任务包含三个子任务(抓取、握持和瓶盖转动)。需要学习这三种技能以及这些技能和两只手之间的协调。1)在 M2VTP [6] 中,额外的二元触觉模态通过预训练有助于单手手指在瓶盖转动中的协调,但它对这些技能和两只手之间的协调帮助不大,因为触摸状态在许多部分都没有变化。 2)将[6]中的 RL 方法应用到该任务,学习所有这些技能和协调性被视为一个黑盒子,很难将它们全部一起学习。
机器人的多模态预训练
利用无监督学习的预训练方法 [7]– [9] 在多模态表示泛化中显得尤为有效。由于存在包括视觉和语言模态 [10]–[12] 在内的大量操作数据集,一些研究 [13]–[16] 探索这些模态在机器人任务中的表示预训练,证明它们的有效性和泛化能力。 [17] 通过将动作模态与视觉和语言相结合来扩展这一点,使机器人能够预测和执行任务。 [18] 通过视觉关联预测任何点的未来运动,从而提高下游性能。然而,对动作模态的预训练主要集中在简单的末端执行器上,对灵巧操作的探索有限。对于触觉,[6]、[19]–[21] 等研究强调视觉-触觉融合在机器人操作中的有效性。然而,它在双手任务中的应用仍未得到充分探索。
机器人双手操作
基于学习的双手操作在机器人领域引起广泛关注。虽然一些研究已经成功利用演示数据 [22]–[24],但缺乏高质量的多指手演示往往限制它们对简单末端执行器的适用性。人们已经努力为多指手收集此类数据 [25]– [27],但重定位错误和延迟等挑战限制它们的实际应用。
另一方面,模拟-到-真实的方法也在机器人操作领域引起日益增长的兴趣[28]–[31],并在各种任务中取得许多成功,例如可变形体操作[32]、开门[33]和手中旋转[34]。然而,这些方法大多侧重于单灵巧手[35]–[38]或双夹持系统[39],[40]。双灵巧手操作方面已经取得一些进展[41]–[43]。[41]构建一个灵巧的双手操作平台,提供 20 个操作任务。[42]采用多智体强化学习来训练双手切换任务,并结合轨迹预测模型来弥合模拟-到-真实的差距。[43]提出一个使用 DRL 训练机械手弹钢琴的系统。然而,这些工作主要依赖于视觉和本体感受模式,这在一定程度上限制操作任务的性能。多模态数据已被证明在双夹持器 [20]、[44]、[45] 和单手灵巧手任务 [46]–[48] 中有效,其在双手灵巧操作中的应用仍未得到充分探索。
本文提出 VTAO-BiManip,一种用于双手操作的预训练和强化学习框架。它在人类操作过程中从更多模态中学习先验知识,并采用课程强化学习(RL)策略。
用于人体双手操作的 VTAO 捕获系统
开发一种新 VTAO 数据收集系统,用于在人体双手操作过程中捕获多模态数据,该系统基于作者之前开发的视觉-触觉采集系统 [6]。
- 系统概述:VTAO 捕获系统包括:1) 双手触觉和运动采集手套,2) Hololens2 用于视觉数据采集,3) ChingMu 运动捕捉 (mocap) 系统用于记录手部运动和 6-DoF 目标姿势,以及 4) 负责数据采集和对齐的个人计算机,如图 所示。每个采集手套由两层组成:内层有 20 个触觉传感器,如 [6],外层有用于运动捕捉的标记。mocap 系统包含 16 个摄像头,用于捕捉瓶子的 6-DoF 姿势信息和手部关节的精确运动。

2)数据对齐和统一表示:多模态数据是独立捕获的,视觉数据以 30 Hz 采样,触觉数据以 200 Hz 采样,动作捕捉数据以 1 kHz 采样。其他模态的数据使用本地时间戳与视觉模态同步,这些时间戳由个人计算机在采集期间记录。为了统一不同模态的坐标系,在 Hololens2 上放置标记,并标定相机与 Hololens2 刚体坐标之间的变换。利用这种变换,可以将瓶子的 6-DoF 姿势以及手部运动数据映射到视觉模态的 RGB 相机坐标系,从而促进模型理解。
3)重定位人类操作轨迹:为了统一预训练和下游任务中的双手动作表示,将数据集中的人类双手动作重定位到下游任务中使用的双灵巧手上。按照 DexRepNet [29] 的说法,将重定向视为非线性优化问题。目标是确保机器人和人类手部在所有阶段的指尖和手指段到手腕的距离相似,从而实现自然的机器人手势。这些是使用双 Shadow Hand M^R 和人手 M^H 的正向运动学以及在步骤 t 的关节角度 q_tR 和 q_tH 确定的。q_tR∗表示优化的在步骤 t 机械手关节角度。在数据集内改进人类双手操作轨迹的每一步,以生成重定位的机械手轨迹,随后将其用于机器人的预训练。
用于预训练的带掩码 VTAO Transformer
为了探索将多模态人类操作数据纳入双手机器人技能学习的好处,提出一种基于 MAE 的预训练框架 VTAO-BiManip [8]。该框架使用收集的 VTAO 数据进行预训练。它提取并集成潜环境表征以支持下游机器人操作任务的学习。VTAO-BiManip 包括一个 VTAO 编码器和一个 VTAO 解码器,如图(左)所示。
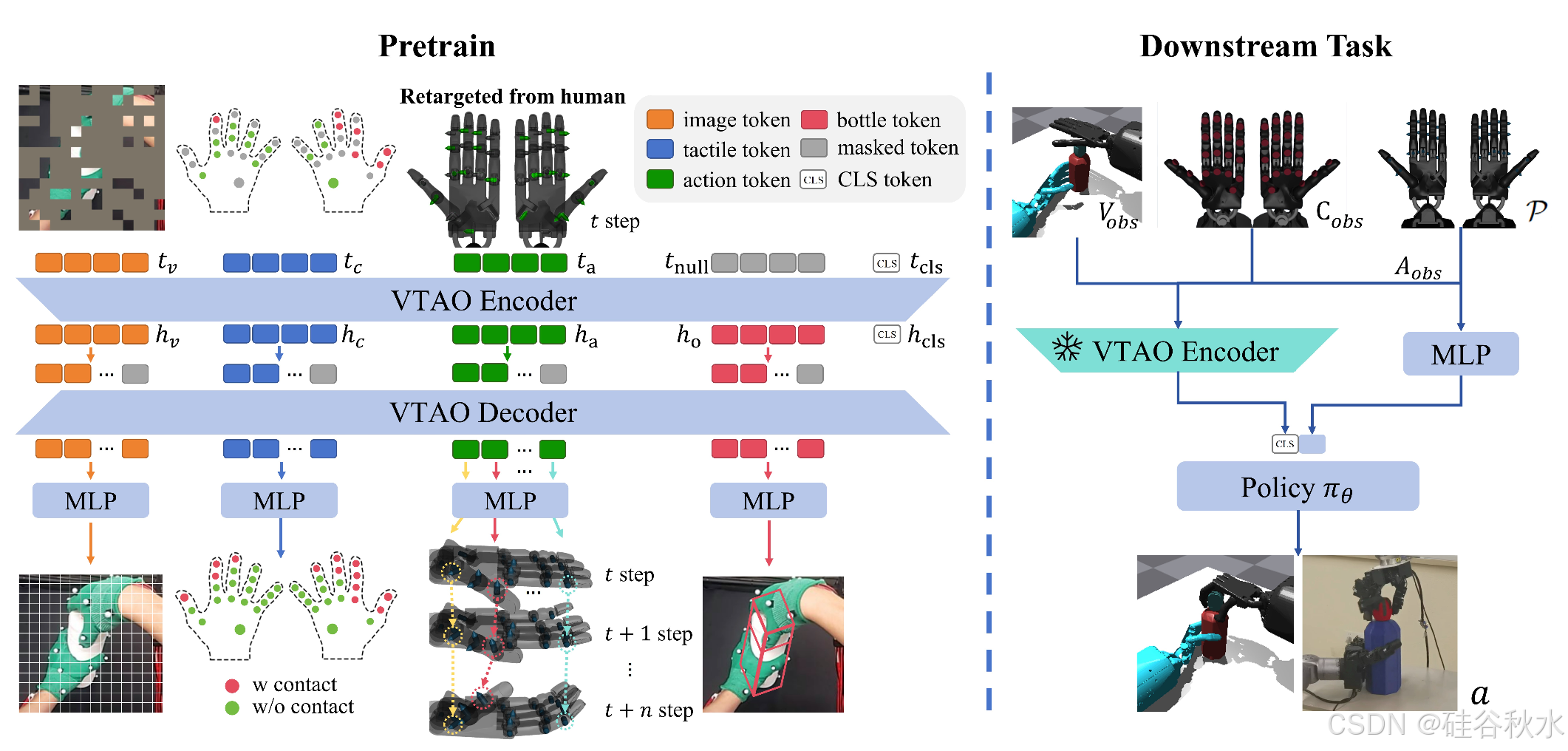
1)VTAO 编码器 E_θ(V, C, A) → (h_cls, h_v, h_c, h_a, h_o):VTA 编码器将视觉、触觉和动作对 (V, C, A) 作为输入。 RGB 图像 V、双手的二值化触觉信号 C( λ 阈值化)和重定位到双 shadow hand 的关节角度 A 通过 Conv2D 和两个 MLP 进行处理,以形成一个 patch 序列。此外,添加空 patch 以对齐特征维度。解码器使用这些patches 重建瓶子信息 ^O。添加位置编码后,一个 patch 序列变为一个 token 序列。按照 MAE [8],随机掩码视觉 token 的 r_v ∈ [0, 1),触觉 token 的 r_c ∈ [0, 1),动作 token 的 r_a ∈ [0,1),以及空 token 的 r_o ∈ [0,1),以形成输入 token 序列 (t_v, t_c, t_a, t_null)。CLS token t_cls 插入到此序列中作为下游任务的聚合表示。最终的 token 序列 (t_cls , t_v, t_c, t_a, tnull) 由 Transformer [24] 编码器处理,产生潜表示序列 (h_cls, h_v, h_c, h_a, h_o)。
- VTAO 解码器 D_θ(h_v, h_c, h_a, h_o, m) → (^V, ^C, [ ^A, ^A_+1, …, ^A_p], ^O): 为了增强 VTAO 编码器 E_θ 对下游任务的特征提取能力,为解码器定义四个重建目标:a) 重建图像 ^V;b) 重建触觉信号 ^C;c) 重建当前动作并预测未来动作 [ ^A, ^A_+1 , …, ^A_+p ]; d) 重建瓶子 ^O 的旋转和大小信息,如上图(左)所示。此处,m 表示用于特征对齐的掩码 tokens。
a) 重建图像 ^V 和触觉信号 ^C:基于作者之前的工作 [6],使用 Transformer 解码器和 MLP 层分别从相应的tokens h_v、h_c 重建图像 ^V 和触觉信号 ^C。作为一项辅助任务,这种方法已被证明对下游应用有益。
b) 重建当前动作并预测未来动作 [^A, ^A_+1, …, ^A_+p]:为了使编码器 E_θ 能够从单帧 VTAO 输入中获取与人类操作任务相关的先验知识,使用 Transformer 解码器和 MLP 层从相应的动作token h_a 重建当前步骤 ^A 的双手动作和接下来 p 步骤的动作序列 [ ^A_+1, …, ^A_+p]。
c) 重建瓶子信息 ^O:了解目标的姿势和大小有利于下游任务,例如扭转瓶盖。使网络能够从目标 token h_o 重建瓶子相对于相机坐标系的 6-DoF 姿势,以及瓶盖和瓶身的尺寸。这使编码器 Eθ 能够更好地关注被操作目标的相关信息。
用于双手操作的 VTAO RL
1)问题表述:将双手操作任务建模为由多元组 (S, A, T , R, γ) 定义的马尔可夫决策过程 (MDP)。这里,S 和 A 表示状态空间和动作空间。策略 π_θ : S → A 将状态映射到动作。转换动力学由 T : S × A → S 给出,奖励函数由 R : S×A → R 给出。折扣因子 γ ∈ (0, 1)。目标是最大化预期折扣奖励 J(π) 来训练策略网络 π_θ。采用 PPO 算法来促进操作技能的学习。RL 架构如上图(右)所示。
2)任务:为了评估 VTAO 预训练对下游任务的有效性,在 Isaac gym [49] 中实现双手拧开瓶盖的任务。该设置将瓶身放置在桌子中央,左手放在其左侧,做出预抓握的姿势,右手固定在其上方。瓶身和瓶盖通过围绕 z 轴旋转的关节连接。
3)状态空间 S:将状态空间定义为 S = {V_obs ,C_obs ,P},其中 V_obs 是以自我为中心的 RGB 图像,C_obs 是来自双手的二进制触觉信号,由 λ 阈值化,P 是双手的本体感受数据,包括关节角度和速度。为了保持预训练的特征表示并提高具有稀疏奖励的 RL 稳定性,在 RL 训练期间冻结预训练的 VTAO 模型参数。策略网络的最终特征向量输入为 {h_cls , φ§},其中 h_cls = E_θ_f (V_obs, C_obs, A_obs),E_θ_f 表示预训练的VTAO编码器,参数固定。A_obs 表示双手的关节角度。h_cls 是E_θ_f 输出的CLS token。φ(·) 是线性层。
4)动作空间A:在模拟中,用Shadow Hand [1]作为操作器。这个五指机械手有24个自由度。除拇指外,四根手指的远端关节由肌腱驱动,总共有20个自由度。实现双手操作,其中右手的基本链接是固定的,左手可以自由移动六个自由度。因此,动作a = π_θ(s)。
5)学习过程:从零开始训练双手精确地操作非固定目标是一项挑战。为了解决这个问题,使用两阶段学习过程来稳定学习过程。在第一阶段,将瓶体固定在桌子上,让左手学习抓住瓶子,右手学习拧开瓶盖。在第二阶段,释放瓶体,让双手协作拧开瓶盖。
6)奖励函数 R:为了在不同的训练阶段协调双手在复杂动作空间中的动作,奖励函数r_n( n ∈ {1, 2})分为两个阶段。在每个阶段,总奖励是左右手各自奖励的总和,r_n = r_left_n + r_right_n。第一阶段 r_1 的奖励函数如下:
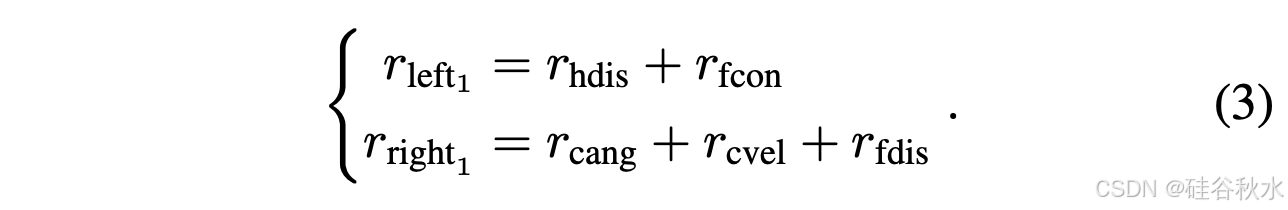
这里,r_hdis = α1 · d_h2b 是距离惩罚,其中 d_h2b 是左手和瓶子之间的距离。r_fcon = α2·N_con 激励左手和瓶子之间的多次接触,其中 N_con 表示接触次数。旋转角度奖励,r_cang = α3 · min(a_c , 7.0),取决于瓶盖的旋转角度 a_c。r_cvel = α4 · C_flag · v_c 奖励旋转速度,其中 v_c 是瓶盖的旋转速度,如果右手接触到瓶盖,则 C_flag 等于 1,否则为 0。项 r_fdis = α5 ·exp(−10·d_fz) 鼓励右手指尖接近瓶盖,其中 d_fz 是指尖和瓶盖高度之间的 z 轴距离。权重α1、α2、α3、α4和α5分别设置为-5、0.05、0.5、1.1和0.5。第二阶段 r_2 的奖励函数如下:
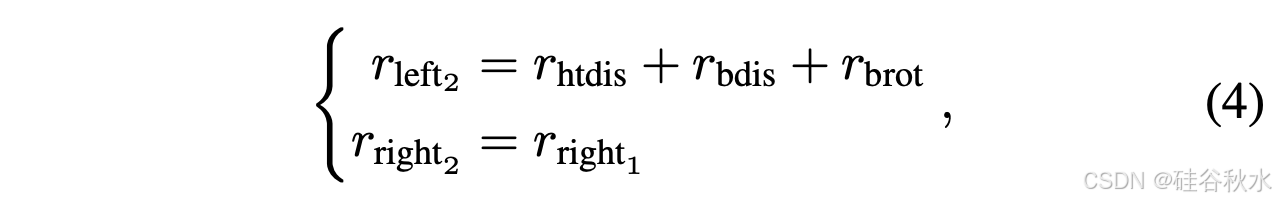
其中 r_htdis = β1 · exp(−5 · d_h2t) 是靠近奖励,d_h2t 表示左手与目标位置之间的距离。r_bdis = β2 ·exp(−10·d_o2i) 鼓励瓶子保持在其初始位置附近,d_o2i 表示瓶子当前位置与初始位置之间的距离。奖励 r_brot = β3 · (1/(|d_qua|+1)) 鼓励瓶子的轴保持垂直于桌子,其中 d_qua = 2·arcsin(min(||qdiff||_2, 1.0)),q_diff = q_bot·q_ini 表示瓶子当前四元数 q_bot 与其初始方向 q_ini 之间四元数差的矢量部分。权重β1、β2、β3均设置为1.0。
数据集:使用 VTAO 采集系统,收集涉及 26 种不同瓶子的 216 条人类双手操作轨迹。每条轨迹持续 6 到 17 秒,总共包含 61684 帧。每帧包含对齐的视觉、触觉和动作数据,以及瓶子姿势和尺寸标签。在训练 VTAO-BiManip 之前,对数据进行预处理,将图像裁剪为 224 × 224 像素,使用 λ = 0.4V 阈值对触觉数据进行二值化,将瓶子姿势与视觉数据的相机坐标系对齐,并将人类手部运动重定位到双灵巧手的关节角度。最终的数据表示包括图像 V、触觉数据 C 和动作数据 A。
实施细节:从 ShapeNet [50] 中选择 15 个瓶子,瓶子和瓶盖尺寸各不相同,使用 10 个进行训练(已见),5 个进行测试(未见)。VTAO-BiManip 在配备 Intel Xeon Gold 6326 和 NVIDIA 3090 的系统上运行。在预训练期间,使用 AdamW 优化器,学习率为 2e-5。掩码比率设置为 r_v = 0.75、r_c = 0.5 和 r_a = 0.5。使用 8 小批量大小进行训练大约需要 2 小时,进行 300 次迭代。对于 RL,运行 400 个并行环境并使用 PPO 算法进行大约 4500 次迭代训练,大约需要 62 小时来训练双手操作策略网络。

















 367
367

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









