










25年2月来自中科院软件所和中科院大学的论文“Sce2DriveX: A Generalized MLLM Framework for Scene-to-Drive Learning”。
端到端自动驾驶是具身智能的重要组成部分,它将原始传感器输入直接映射到低级车辆控制。尽管在应用多模态大语言模型 (MLLM) 进行高级交通场景语义理解方面取得成功,但将这些概念语义理解有效地转化为低级运动控制命令并在跨场景驾驶中实现泛化和共识仍然具有挑战性。Sce2DriveX,是一种类似人类驾驶思维链 (CoT) 推理 MLLM 框架。Sce2DriveX 利用从局部场景视频和全局 BEV 地图中进行的多模态联合学习来深入理解远范围时-空关系和道路拓扑,增强其在 3D 动态/静态场景中的综合感知和推理能力,并实现跨场景驾驶泛化。在此基础上,重构人类驾驶中固有的隐性认知链,涵盖场景理解、元-动作推理、行为解释分析、运动规划和控制,从而进一步弥合自动驾驶与人类思维过程之间的差距。为了提升模型性能,开发一个针对 3D 空间理解和长轴任务推理的视觉问答 (VQA) 驾驶指令数据集。
具身智能使自动驾驶 (AD) 模型等智体具备实时感知、推理和与现实世界交互的能力。然而,核心挑战在于自动驾驶模型框架的泛化和共识。一方面,自动驾驶学习框架可能难以概括复杂、动态的交通场景,如多变的天气条件、道路布局、交通语义和周围参与者的行为偏好。另一方面,自动驾驶系统的决策策略往往与人类驾驶员的认知过程不一致,使人类对系统行为的理解变得复杂。这些挑战源于高级场景语义理解和低级运动控制命令之间的差距。因此,开发一个能够全天候、全场景感知和推理的类人框架成为一个广泛讨论的话题。
目前的自动驾驶研究通常采用小模型学习框架 (Zeng et al., 2019; Hu et al., 2022; 2023)。由于小模型的推理能力有限,这些系统对预定义的问题做出严格的响应,因此在面对新的或意外的查询时很难提供令人满意的结果。
最近,MLLM(Li et al.,2023;Liu et al.,2024;Driess et al.,2023)的快速发展已在各种视觉-语言任务中显示出显着的优势。通过利用 MLLM 作为高级场景语义理解和低级运动控制命令之间的桥梁,可以解决AD模型中的泛化和共识挑战。得益于对大量跨模态和跨学科数据的预训练,MLLM提供强大的推理和泛化能力,使其能够管理不同的场景并增强自适应跨场景驾驶。此外,MLLM强大的文本查询和认知能力,使得它们能够将驾驶思维与人类共识结合起来,将复杂的推理转化为可理解的自然语言,为自动驾驶提供统一的解释层。但自动驾驶是一项复杂的任务,具有时空连续性、动态场景和全局协调性等特点。目前基于MLLM的自动驾驶研究,主要以单帧正面场景图像(Sima,2025)作为感知输入,对时空关系和道路特征缺乏深入理解,对交通场景理解不足。此外,目前研究在生成驾驶指令时,往往仅将场景因素映射到低级控制信号上(Xu,2024),忽略未来车辆行为背后的推理,未能利用MLLM的广义认知推理能力,与人类的驾驶思维相背离。
除了模型框架之外,匹配的数据集对于模型的高效训练和性能上限也至关重要。许多数据集都是以 VQA 的形式设计,尽管取得一些成功,但在现有 VQA 数据集上训练的模型,在解决 AD 的复杂性方面仍然存在局限性。这种限制主要源于交通场景和 VQA 数据集之间视觉信息的差异 [9, 10],要求模型有效利用多模态感知数据的互补信息来理解复杂场景并从多帧数据流中捕捉物体动态。此外,大多数 VQA 数据集都是针对单一驾驶任务定制的。它们通常只提供简单的逻辑布尔答案(即是或否)或在封闭式问题注释中有限的多项选择题答案(Qian et al., 2024),缺乏丰富性。
本文提出 Sce2DriveX 框架(如图左所示),使用模态编码器将多视角场景视频和 BEV 地图图像的视觉表示对齐到统一的视觉特征空间,然后通过共享投影映射到文本嵌入空间,并由 LLM 主干处理生成自然语言响应,包括场景理解、行为分析、运动规划和车辆控制。图中部分是VQA数据集,用于 3D 空间理解和长轴任务推理,重点关注多模态、多视图和多帧环境下的分层场景理解和可解释的端到端驾驶任务。图右是训练流水线,包括混合对齐预训练、场景理解微调、端到端驾驶微调三阶段。

See2DriveX 框架
本文旨在开发一个类似人类的 CoT 推理 MLLM 框架,实现从多视角长距离场景理解行为分析、运动规划和车辆控制驾驶过程的渐进式推理学习。如图所示,See2DriveX 由四个组件组成:1)模态编码器,包括视频编码器和图像编码器,由 OpenCLIP 初始化;2)共享投影,使用两个带有 GeLU 激活的全连接层;3)LLM 主干,采用 Vicuna-v1.5-7b;4)文本编码器和文本解码器,由 LLaMA 提供。
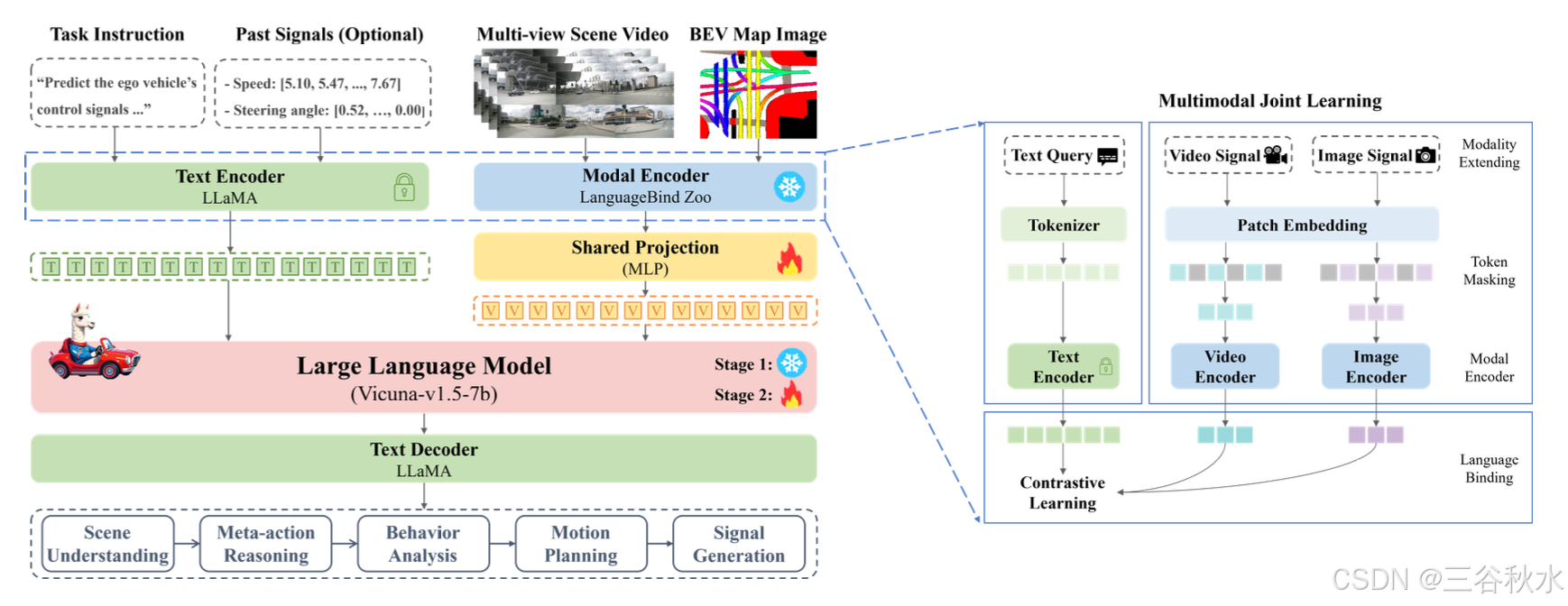
多模态联合训练
给定文本指令 X_T,首先使用字节-对编码 (BPE) token化器将单词分割成相对常见的子词,每个子词对应一个唯一的 logit。然后,使用文本编码器对这些 logit 进行编码。
给定多视角场景视频 X_V 和 BEV 图的图像 X_I,T 为视频帧数,(H, W) 为原始图像分辨率,C为通道数,采用块掩码方法。通过使用编码器掩码 M_e,选择并分割一小部分块,以缓解模态编码器中 token 数量过多的问题。具体而言,首先通过具有非重叠滤波器的块嵌入层将视频信号 X_V 和图像信号 X_I 转换为相应的块 P_V 和 P_I,其中 N = H×W/B^2 为 p 块的数量,B 为每个块的大小。然后,将位置嵌入应用于可见的 token,并使用编码器掩码对其进行划分。
最后,使用视频编码器 f_V_E 对视频序列 S_V 进行编码,使用图像编码器 f_I_E 对图像序列 S_I 进行编码。为了实现多模态语义对齐,采用 LanguageBind(Zhu et al.,2023a)的模态编码方法,该方法使用文本作为不同模态之间的桥梁。通过对比学习原理,将其他模态绑定到文本模态,并紧急对齐到统一的视觉特征空间。
LLM 主干支持的统一处理
目标是将多模态 tokens 映射到文本嵌入空间,为 LLM 提供统一的视觉表示,然后将其与 token 化的文本查询相结合,并输入到 LLM 主干中以生成响应。具体来说,首先使用共享投影 f_P 来映射视频 tokens H_V 和图像 tokens H_I。
接下来,统一的视觉 token H_L 与文本 token H_T 相结合,并输入到 LLM 主干 f_LLM 进行处理,生成相应的预测 token。这些预测 token 最终由文本解码器 f_T_D 解码回自然语言响应 Z。Z ∈ {Z_sce , Z_act , Z_int , Z_mot , Z_sig } 包括场景理解Z_sce、元动作推理Z_act、行为解释分析Z_int、运动规划Z_mot、控制信号生成Z_sig。
综上所述,Sce2DriveX 能够理解远距离时空关系和道路拓扑结构,增强 3D 场景感知和推理能力,实现跨场景驾驶泛化,并还原人类驾驶的认知链,加强自动驾驶与人类思维的一致性。
VQA驾驶数据集
为了训练 Sce2DriveX,本文构建一个 VQA 驾驶指导数据集,用于 3D 空间理解和长轴任务推理。它基于开源 nuScenes(Caesar et al.,2020),集成三种模态的结构化数据:多视角场景视频(局部)、BEV 图的图像(全局)和多轮 QA 注释。如图所示,数据集包括两个子集:1)分层场景理解数据集;2)可解释的端到端驾驶数据集。
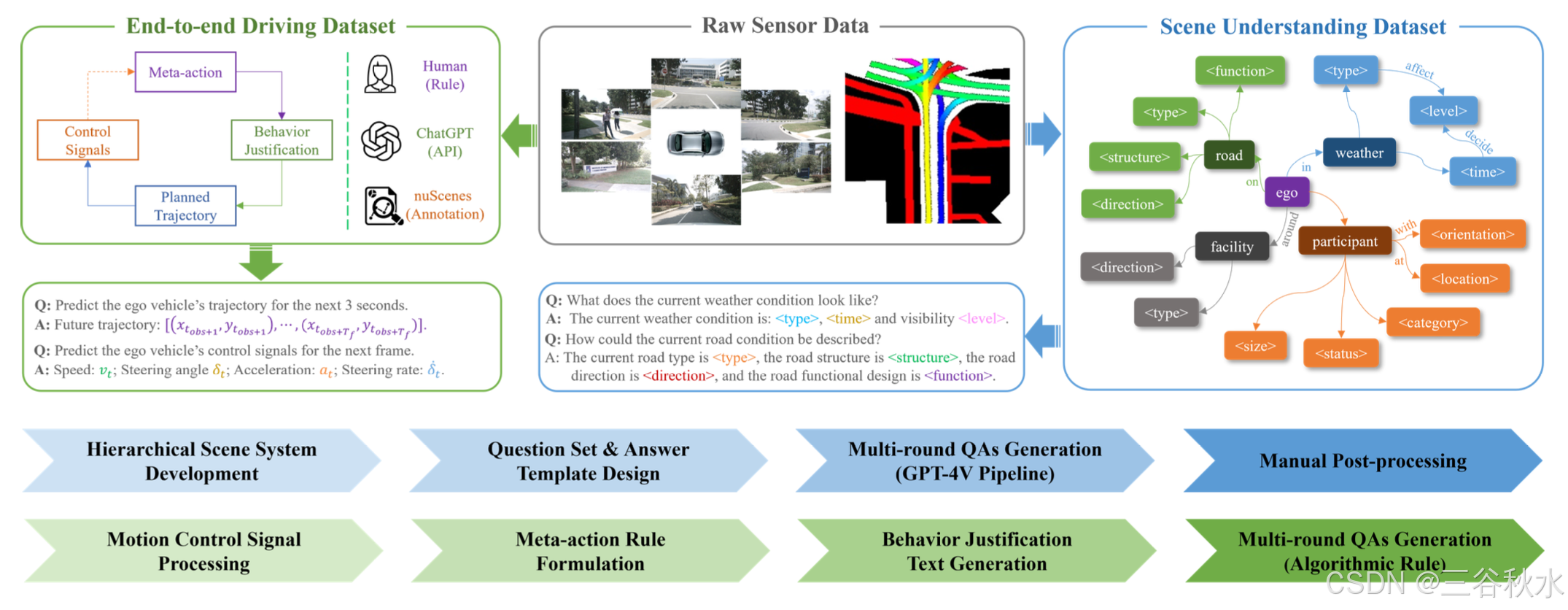
分层场景理解
分层场景理解数据集通过可扩展的自动化流程生成,提供交通场景的分层、结构化描述。它涵盖天气、道路、设施和交通参与者(3D),挑战模型的 3D 空间理解。上图显示其构建过程,包括分层场景开发、问题集和答案模板设计、多轮 QA 生成和手动后处理。
为了增强模型对长尾场景的识别,开发一个分层场景系统 E 来分层描述交通场景,涵盖四个元素:E = {E_weather,E_road,E_facility,E_participant}。每个元素都有多个属性。此外,其构建一个场景图来可视化分层场景系统。如上图(右)所示,该图通过结构化关系增强视觉场景:中心节点代表自车,中间节点代表四个场景元素,最外层节点表示它们的属性。节点通过表示动作(动词)或空间关系(介词)的边连接。
基于分层场景系统,围绕每个场景元素手动设计四个问题集:Q = {Q_weather,Q_road,Q_facility,Q_participant}。
使用场景图,手动设计四个与问题集相匹配的答案模板 A = {A_weather, A_road, A_facility, A_participant},并结合各种参数化属性。遍历场景图的节点和边,将它们转换为 [元素-关系-属性] 三元组,并为每个三元组编写固定文本。
用 ChatGPT 的自动流水线来生成多轮 QA 注释。一个关键挑战是幻觉,即文本与视觉效果不匹配。为了缓解这种情况,删除不合适的问答、纠正错误和填写缺失的选项,手动优化注释。
可理解的端到端驾驶
可解释的端到端驾驶数据集通过面向-意图-认知的算法规则自动集成,实现对驾驶过程的顺序和透明描述。它涵盖元动作、行为论证、规划轨迹和控制信号(多种类型),挑战模型的长轴任务推理能力。上图(左)说明其构建过程,包括运动控制信号处理、元动作规则制定和行为证明文本生成。
运动控制信号 S 包括规划轨迹和低级控制信号。原始 nuScenes 注释为每个场景提供伴随的运动控制信号。将这些信号解析为结构化的 JSON 条目并对其进行分类。具体来说,将历史轨迹和控制信号作为已知信息与任务背景文本一起集成到系统提示中以协助推理。此外,使用未来轨迹和当前/下一帧控制信号作为真值标签,将它们填充到预定义模板中以改进预测。
自车的元动作 A 表示为横向速度水平估计、纵向速度水平估计和转向级估计的组合。基于阈值空间,细化每个部件的判断规则。横向和纵向速度水平估计由当前帧加速度与预定义阈值之间的关系确定。转向级估计遵循分层判断原则,首先根据当前帧排除怠速和直行动作,然后遍历满足直行条件的未来时间步。左转/右转和轻微左转/右转基于横摆角速度增益、横向位移和阈值之间的关系确定。
采用组合方法生成 64 种元动作类型,模拟车辆在不同场景下的行为模式。每种元动作都表示为一种连续状态,与现实世界中的人类驾驶意图保持一致。
行为论证文本 T 提供自车短期驾驶策略的原因分析,增强整个决策过程的可解释性。利用 ChatGPT 的 API 接口进行生成:通过使用场景理解 QA 注释和元动作作为上下文信息,提示 ChatGPT 自动生成元动作的分析论证。与手动注释方法相比,这种方法可以生成更加多样化的行为论证文本,并且可以全面准确地反映潜在的交通因素(例如交通规则)和社会因素(例如社会背景)。
训练流水线
为了进一步增强 Sce2DriveX 的感知推理性能,本文引入面向任务的三阶段训练流程,包括:1)混合对齐预训练;2)场景理解微调;3)端到端驱动微调。
训练细节如下。
将每幅图像裁剪为 224×224 的大小。从每个视频中均匀采样 8 帧,并对每帧进行图像预处理。每批数据包括图像和视频的组合。在预训练阶段,模型训练 1 个 epoch,批大小为 128,分布在 6 个 A100 (80GB) GPU 上。在微调阶段,使用 AdamW 优化器和余弦学习率调度器,初始学习率设置为 2e-5,预热比为 0.03,梯度累积步长为 2。具体来说,场景理解微调阶段训练模型 1 个 epoch,而端到端驾驶微调阶段训练模型 3 个 epoch。整个过程在 8 个 L20 (48GB) GPU 上完成,每个 GPU 的批大小为 4。

















 3883
3883

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









