









欢迎关注[【AIGC论文精读】](https://blog.csdn.net/youcans/category_12321605.html)原创作品
【DeepSeek论文精读】1. 从 DeepSeek LLM 到 DeepSeek R1
【DeepSeek论文精读】7. DeepSeek 的发展历程与关键技术
【DeepSeek论文精读】8. 原生稀疏注意力(NSA)
【DeepSeek论文精读】8. 原生稀疏注意力(NSA)
0. 论文简介与摘要
0.1 论文简介
2025年 2月,DeepSeek 发布最新论文,提出一种新的注意力机制 ——NSA。这是一个用于超快长上下文训练和推断的本地可训练的稀疏注意力机制,并且还具有与硬件对齐的特点。本文通讯作者是北京大学张铭教授和 DeepSeek 创始人梁文锋。
- 论文标题:Native Sparse Attention: Hardware-Aligned and Natively Trainable Sparse Attention(原生稀疏注意力:硬件对齐且原生可训练的稀疏注意力)
- 发布时间:2025 年 2 月 [2502.11089]
- 论文作者:Jingyang Yuan,Huazuo Gao,Damai Dai,Junyu Luo,Liang Zhao,Zhengyan Zhang,Zhenda Xie,Y. X. Wei,Lean Wang,Zhiping Xiao,Yuqing Wang,Chong Ruan,Ming Zhang,Wenfeng Liang,Wangding Zeng
- 下载地址:https://arxiv.org/abs/2502.11089
0.2 主要贡献:
论文提出了原生可训练的稀疏注意力机制(Native Sparse Attention, NSA),将算法创新与硬件优化相结合,实现高效长文本建模,主要贡献体现在方法改进、性能提升、效率优化等方面。
-
创新稀疏注意力机制设计:
提出 NSA,融合动态分层稀疏策略,结合粗粒度token压缩和细粒度token选择,兼顾全局上下文感知与局部精度,改进了传统稀疏注意力设计。通过将键值对重映射,设计了token压缩、token选择和滑动窗口三种策略,构建了完整的算法框架。 -
实现硬件对齐与训练感知优化:
从硬件对齐系统和训练感知设计两方面优化。针对现代硬件优化块稀疏注意力,平衡算术强度,提高硬件利用率;基于triton设计了高效的注意力算子,实现稳定的端到端训练,减少预训练计算量且不牺牲模型性能。 -
提升模型性能表现:
在多个基准测试中,NSA 预训练模型性能与全注意力模型相当甚至超越。在通用基准测试、长上下文任务和基于指令的推理任务中表现出色,尤其在推理相关基准测试中有显著提升,验证了其作为通用架构的稳健性。 -
显著提高计算效率:
在处理 64k 长度序列时,NSA 在解码、前向传播和反向传播阶段均比完整多头注意力机制有大幅加速,且序列越长加速比越高。训练阶段 64k 上下文长度下,前向加速达 9.0 倍,反向加速达 6.0 倍;解码阶段在 64k 上下文长度下,速度提升最高可达 11.6 倍。
简单地说,DeepSeek 提出了一种新的注意力机制,可以更好更快的处理更长的上下文。

0.3 摘要
长上下文建模对于下一代语言模型至关重要,然而标准的注意力机制(Transformer)的计算成本很高,带来了巨大的计算挑战。稀疏注意力(Sparse attention)为在保持模型能力的同时提高效率提供了一个有前景的方向。
我们提出了原生可训练稀疏注意力机制(NSA),它将算法创新与硬件适配优化相结合,以实现高效的长上下文建模。NSA 采用动态分层稀疏策略,将粗粒度 token 压缩与细粒度 token 选择相结合,既保留了全局上下文感知,又保证了局部精度。
我们的方法通过两项关键创新推进了稀疏注意力设计:
(1)通过算术强度平衡的算法设计,并针对现代硬件进行实现优化,实现了显著的加速。
(2)实现了端到端训练,在不牺牲模型性能的情况下减少了预训练计算量。
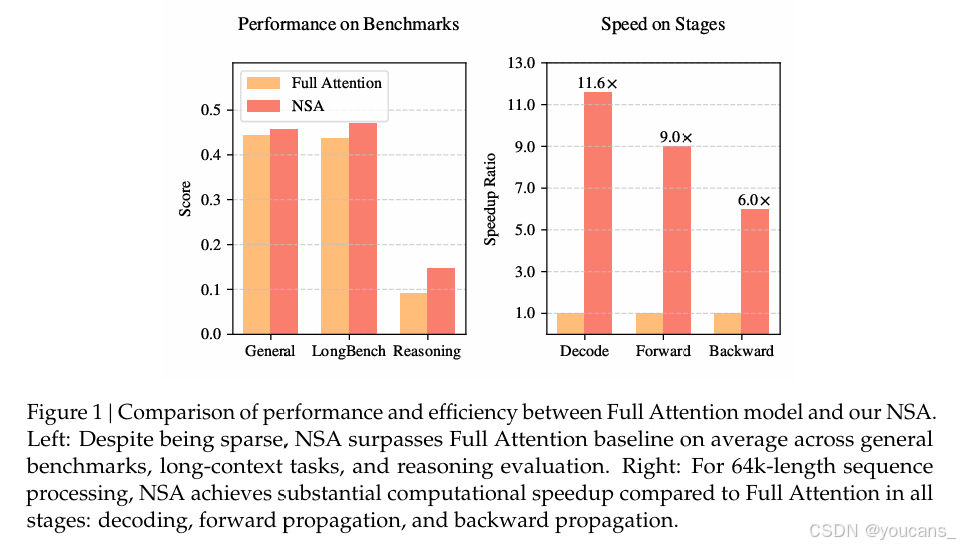
如图1 所示,实验表明,使用 NSA 预训练的模型在通用基准测试、长上下文任务和基于指令的推理中,性能与全注意力模型相当甚至超越。同时,在处理64k长度序列时,NSA在解码、前向传播和反向传播方面比全注意力机制实现了大幅加速,验证了其在模型整个生命周期中的高效性。
1. 引言
研究社区越来越认识到长上下文建模是下一代大型语言模型的关键能力,这一需求由多种实际应用驱动,包括深度推理(DeepSeek-AI, 2025; Zelikman et al., 2022)、仓库级代码生成(Zhang et al., 2023a; Zhang et al.)以及多轮自主代理系统(Park et al., 2023)。最近的突破,包括OpenAI的o系列模型、DeepSeek-R1(DeepSeek-AI, 2025)和Gemini 1.5 Pro(Google et al., 2024),使得模型能够处理整个代码库、长文档、在数千个令牌上保持连贯的多轮对话,并在长距离依赖关系中进行复杂推理。然而,随着序列长度的增加,传统注意力机制(Vaswani et al., 2017)的高复杂度(Zaheer et al., 2020)成为关键的延迟瓶颈。理论估计表明,在使用softmax架构的注意力计算中,解码64k长度的上下文时,注意力计算占总延迟的70-80%,这凸显了对更高效注意力机制的迫切需求。
解读:随着应用场景的复杂化(如深度推理、代码生成、多轮对话等),模型需要处理更长的上下文信息。
实现高效长上下文建模的一种自然方法是利用softmax注意力的固有稀疏性(Ge et al., 2023; Jiang et al., 2023),通过选择性计算关键查询-键对,可以显著减少计算开销,同时保持性能。最近的进展通过多种策略展示了这一潜力:KV缓存淘汰方法(Li et al., 2024; Zhang et al., 2023b; Zhou et al., 2024)、分块KV缓存选择方法(Gao et al., 2024; Tang et al., 2024; Xiao et al., 2024a)以及基于采样、聚类或哈希的选择方法(Chen et al., 2024b; Desai et al., 2024; Liu et al., 2024)。尽管这些策略很有前景,但现有的稀疏注意力方法在实际部署中往往表现不佳。许多方法未能实现与其理论增益相当的速度提升;此外,大多数方法缺乏有效的训练时支持,无法充分利用注意力的稀疏模式。
解读:尽管已有多种稀疏注意力策略(如KV缓存淘汰、分块选择、采样等),但它们在实际部署中往往无法实现理论上的速度提升,且缺乏对训练时稀疏模式的支持。
为了解决这些局限性,部署有效的稀疏注意力必须解决两个关键挑战:(1)硬件对齐的推理加速:将理论计算减少转化为实际速度提升,需要在预填充和解码阶段设计硬件友好的算法,以缓解内存访问和硬件调度瓶颈;(2)训练感知的算法设计:通过可训练的操作符实现端到端计算,以减少训练成本,同时保持模型性能。这些要求对于实际应用中实现快速长上下文推理或训练至关重要。在考虑这两方面时,现有方法仍存在明显差距。
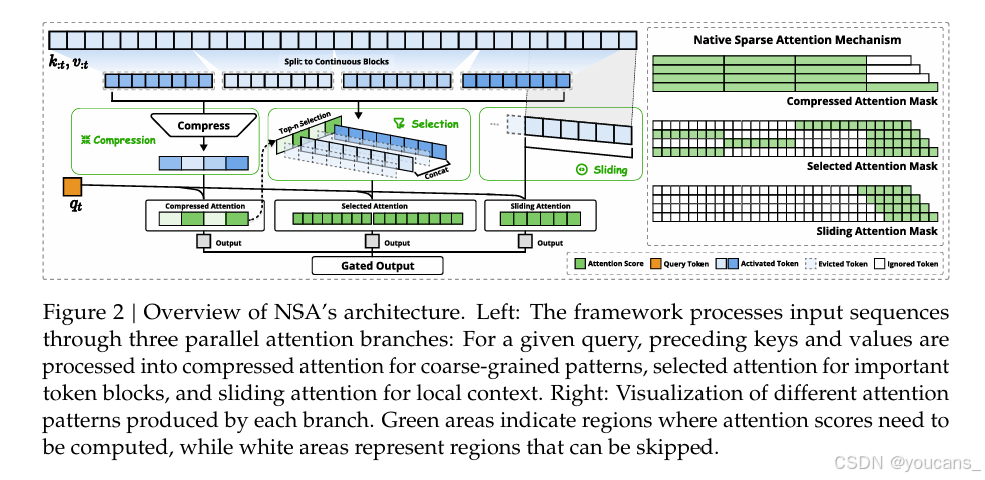
为了实现更有效和高效的稀疏注意力,我们提出了NSA(Natively Trainable Sparse Attention,原生可训练的稀疏注意力架构),它集成了分层令牌建模。如图2所示,**NSA通过将键和值组织成时间块并通过三种注意力路径处理它们来减少每个查询的计算量:压缩的粗粒度令牌、选择性保留的细粒度令牌以及用于局部上下文信息的滑动窗口。**然后,我们实现了专用内核以最大化其实际效率。NSA引入了与上述关键需求相对应的两项核心创新:(1)硬件对齐的系统:优化分块稀疏注意力以利用Tensor Core和内存访问,确保算术强度平衡。(2)训练感知的设计:通过高效算法和反向操作符实现稳定的端到端训练。这种优化使NSA能够支持高效部署和端到端训练。
解读:NSA通过将键和值组织成时间块,并采用三种注意力路径(压缩粗粒度令牌、选择性保留细粒度令牌、滑动窗口)来减少计算量。
我们通过对真实语言语料库的综合实验评估NSA。在一个27B参数的Transformer骨干网络上使用260B令牌进行预训练,我们评估了NSA在通用语言评估、长上下文评估和链式推理评估中的表现。我们进一步比较了A100 GPU上优化Triton(Tillet et al., 2019)实现的内核速度。实验结果表明,NSA在性能上与全注意力基线相当或更优,同时优于现有的稀疏注意力方法。此外,与全注意力相比,NSA在解码、前向和反向阶段实现了显著加速,且随着序列长度的增加,加速比进一步提高。这些结果验证了我们的分层稀疏注意力设计有效地平衡了模型能力和计算效率。
解读:NSA 在高效、可训练的同时保持了模型的性能。
2. 重新思考稀疏注意力方法
现代稀疏注意力方法在降低Transformer模型的理论计算复杂度方面取得了显著进展。然而,大多数方法主要在推理阶段应用稀疏性,同时保留了预训练的全注意力骨干网络,这可能会引入架构偏差,限制其充分利用稀疏注意力优势的能力。在介绍我们的原生稀疏架构之前,我们通过两个关键视角系统地分析这些局限性。
解读:现有稀疏注意力方法仅在推理阶段应用稀疏性,而训练阶段仍依赖全注意力。
2.1 高效推理的假象
尽管许多方法在注意力计算中实现了稀疏性,但它们未能相应地减少推理延迟,这主要归因于两个挑战:
-
阶段受限的稀疏性:
像H2O(Zhang et al., 2023b)这样的方法在自回归解码阶段应用稀疏性,但在预填充阶段需要计算密集的预处理(例如注意力图计算、索引构建)。相比之下,像MInference(Jiang et al., 2024)这样的方法仅关注预填充阶段的稀疏性。
这些方法未能实现所有推理阶段的加速,因为至少有一个阶段的计算成本与全注意力相当。这种阶段专门化降低了这些方法在预填充主导的工作负载(如书籍摘要和代码补全)或解码主导的工作负载(如长链式推理(Wei et al., 2022))中的加速能力。 -
与高级注意力架构的不兼容性:
一些稀疏注意力方法无法适应现代解码高效架构,如多头查询注意力(MQA)(Shazeer, 2019)和分组查询注意力(GQA)(Ainslie et al., 2023),这些架构通过在多个查询头之间共享KV显著减少了解码阶段的内存访问瓶颈。例如,在Quest(Tang et al., 2024)等方法中,每个注意力头独立选择其KV缓存子集。尽管它在多头注意力(MHA)模型中展示了计算稀疏性和内存访问稀疏性的一致性,但在基于GQA等架构的模型中,KV缓存的内存访问量对应于同一GQA组内所有查询头选择的并集。这种架构特性意味着,尽管这些方法可以减少计算操作,但所需的KV缓存内存访问量仍然相对较高。这一限制迫使做出关键选择:虽然一些稀疏注意力方法减少了计算,但其分散的内存访问模式与高级架构的高效内存访问设计相冲突。
这些局限性源于许多现有稀疏注意力方法专注于KV缓存减少或理论计算减少,但难以在高级框架或后端中实现显著的延迟减少。这促使我们开发结合高级架构和硬件高效实现的算法,以充分利用稀疏性来提高模型效率。
2.2 可训练稀疏性的误区
我们对原生可训练稀疏注意力的追求源于对仅推理方法的两个关键洞察:
- (1)性能下降:
事后应用稀疏性迫使模型偏离其预训练的优化轨迹。正如Chen等人(2024b)所展示的,前20%的注意力只能覆盖总注意力得分的70%,这使得预训练模型中的检索头等结构在推理期间容易受到剪枝的影响。 - (2)训练效率需求:
高效处理长序列训练对于现代大语言模型(LLM)开发至关重要。这包括在更长文档上进行预训练以增强模型能力,以及后续的适应阶段(如长上下文微调和强化学习)。然而,现有的稀疏注意力方法主要针对推理,训练中的计算挑战大多未得到解决。这一局限性阻碍了通过高效训练开发更强大的长上下文模型。
此外,尝试将现有稀疏注意力方法适应训练也暴露了以下挑战:
-
不可训练组件:
像ClusterKV(Liu等人,2024)(包括k-means聚类)和MagicPIG(Chen等人,2024b)(包括基于SimHash的选择)等方法中的离散操作在计算图中引入了不连续性。这些不可训练组件阻止了梯度通过令牌选择过程流动,限制了模型学习最优稀疏模式的能力。 -
低效的反向传播:
一些理论上可训练的稀疏注意力方法在实际训练中存在效率低下的问题。像HashAttention(Desai等人,2024)等方法中使用的令牌粒度选择策略导致在注意力计算期间需要从KV缓存中加载大量单个令牌。这种非连续的内存访问阻碍了快速注意力技术(如FlashAttention)的高效适应,这些技术依赖于连续内存访问和分块计算以实现高吞吐量。因此,实现被迫回退到低硬件利用率,显著降低了训练效率。
解读:这些问题表明,现有稀疏注意力方法在训练阶段存在显著不足,无法满足现代大语言模型开发的需求。为此,作者提出需要一种原生可训练的稀疏注意力架构,以支持高效的端到端训练,同时保持模型性能。
2.3 原生稀疏性的必要性
推理效率和训练可行性的这些局限性促使我们对稀疏注意力机制进行根本性重新设计。我们提出了NSA(原生稀疏注意力框架),它同时解决了计算效率和训练需求。在接下来的章节中,我们将详细阐述NSA的算法设计和操作符实现。
3. 方法
我们的技术方法涵盖了算法设计和内核优化。
接下来,我们首先介绍我们的方法的背景,然后介绍 NSA 的总体框架及其关键算法组件,最后,我们详细介绍硬件优化内核设计,以最大限度地提高实际效率。
3.1 背景
注意力机制在语言建模中被广泛使用,其中每个查询令牌 q t q_t qt 计算与所有先前键 k : t k_{:t} k:t 的相关性分数,以生成值的加权和 v : t v_{:t} v:t 。形式上,对于长度为 t t t 的输入序列,注意力操作定义如下:
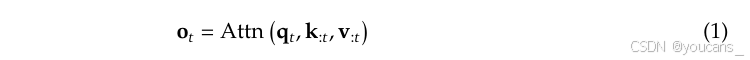
其中:
q
t
q_t
qt 是查询向量,
k
:
t
k_{:t}
k:t 是键矩阵,
v
:
t
v_{:t}
v:t 是值矩阵。
Attn 表示注意力函数:
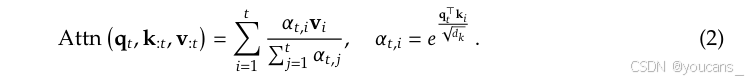
其中
α
t
,
i
\alpha_{t, i}
αt,i 是
q
t
q_t
qt 和
k
i
k_i
ki 之间的注意力权重,
d
k
d_k
dk 是键的特征维度。随着序列长度增加,注意力计算在整体计算成本中占比会越来越大,这给长上下文处理带来了巨大的挑战。
算术强度(Arithmetic Intensity) 是计算操作与内存访问的比率。它在本质上决定了算法在硬件上的优化方式。每个 GPU 都有一个由其峰值计算能力和内存带宽决定的临界算术强度,计算方式为这两个硬件限制的比率。对于计算任务,当算术强度高于此临界阈值时,任务受计算限制(受 GPU 的浮点运算能力限制);低于此阈值时,任务受内存限制(受内存带宽限制)。
具体到因果自注意力机制(causal self-attention mechanism),在训练和预填充阶段,批量矩阵乘法和注意力计算表现出高算术强度,使得这些阶段在现代加速器上受计算限制。相比之下,自回归解码阶段受内存带宽限制,因为它在每次前向传播中生成一个令牌,同时需要加载整个键值缓存,导致算术强度较低。这导致了不同的优化目标——在训练和预填充阶段减少计算成本,而在解码阶段减少内存访问。
解读:算术强度是衡量计算任务效率的关键指标,决定了任务受计算限制还是内存限制。在因果自注意力机制中,训练和预填充阶段由于高算术强度而受计算限制,优化目标是减少计算成本;而解码阶段由于低算术强度而受内存限制,优化目标是减少内存访问。
3.2 总体框架
为了利用注意力机制中自然稀疏模式的潜力,我们提出将公式(1)中的原始键值对
k
:
t
,
v
:
t
k_{:t},v_{:t}
k:t,v:t 替换为更紧凑且信息密集的表示键值对
K
^
t
,
V
^
t
\hat K_{t}, \hat V_{t}
K^t,V^t,这些键值对基于每个查询
q
t
q_t
qt 动态构建。
具体来说,我们正式定义优化后的注意力输出如下:
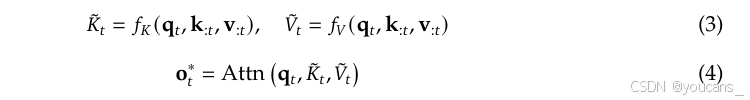
其中,键值对 K ^ t , V ^ t \hat K_{t}, \hat V_{t} K^t,V^t 是基于当前查询 q t q_t qt 和上下文记忆 k : t , v : t k_{:t},v_{:t} k:t,v:t 动态构建的。我们可以设计多种映射策略来获得不同类别的 K ^ t c , V ^ t c \hat K^c_t, \hat V^c_t K^tc,V^tc,并将它们组合如下:
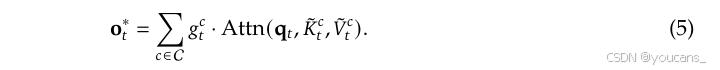
如图2所示,NSA 采用了三种映射策略 C = c m p , s l c , w i n C={cmp,slc,win} C=cmp,slc,win,分别表示键和值的压缩( compression)、选择(selection)和滑动窗口(sliding window)。 g c , t ∈ [ 0 , 1 ] g_{c,t} \in [0,1] gc,t∈[0,1] 是对应策略 c 的门控分数,通过输入特征经过 MLP 和 sigmoid 激活函数得到。设 N t N_t Nt 表示重新映射的键/值总数:

我们通过确保⻓
N
t
≪
t
N_t≪t
Nt≪t 来保持高稀疏率。
解读:NSA 的整体框架,通过动态构建更紧凑且信息密集的键值对 K ^ t c , V ^ t c \hat K^c_t, \hat V^c_t K^tc,V^tc,替代原始的全注意力机制中的键值对 K ^ t , V ^ t \hat K_{t}, \hat V_{t} K^t,V^t,结合压缩、选择和滑动窗口三种映射策略,实现了高效的长上下文建模。
3.3 算法设计
在本小节中,我们介绍了重映射策略 f K f_K fK 和 f V f_V fV 的设计:令牌压缩、令牌选择和滑动窗口。
3.3.1 令牌压缩(Token Compression)
通过将连续的键或值块聚合为块级表示,我们获得了压缩后的键和值,这些表示捕捉了整个块的信息。形式上,压缩后的键表示定义如下:
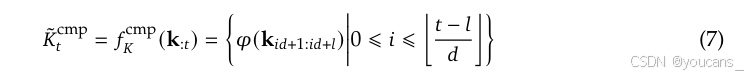
其中,
l
l
l 是块长度,
d
d
d 是相邻块之间的滑动步长,φ 是一个可学习的 MLP,带有块内位置编码,用于将块中的键映射为单个压缩键。
K ^ t c m p ∈ R d k ∗ t − l d \hat K^{cmp}_t \in R^{d_k*\frac{t-l}{d}} K^tcmp∈Rdk∗dt−l 是由压缩键组成的张量。通常,我们采用 d < l d<l d<l 以减少信息碎片化。类似的公式也适用于压缩值 V ^ t c m p \hat V^{cmp}_t V^tcmp 的表示 。压缩表示捕捉了更粗粒度的高层语义信息,并减少了注意力计算的计算负担。
解读:令牌压缩的核心思想,是将连续的键或值块聚合为块级表示,从而减少需要处理的键值对数量。这种压缩方式捕捉了块内的高层语义信息,同时显著降低了计算复杂度。适用于需要捕捉全局上下文信息的任务。
3.3.2 令牌选择
仅使用压缩的键和值可能会丢失重要的细粒度信息,这促使我们选择性地保留单个键和值。下面我们描述了一种高效的令牌选择机制,该机制以低计算开销识别并保留最相关的令牌。
分块选择:
我们的选择策略在空间连续的块中处理键和值序列,这一设计基于两个关键因素:硬件效率考虑和注意力分数的固有分布模式。
分块选择对于在现代 GPU 上实现高效计算至关重要。这是因为现代 GPU 架构对连续块访问的吞吐量显著高于基于随机索引的读取。此外,分块计算能够充分利用 Tensor Core 的优势。这一架构特性使得分块内存访问和计算成为高性能注意力实现的基本原则,FlashAttention 的基于块的设计就是一个典型例子。
分块选择遵循注意力分数的固有分布模式。先前的研究(Jiang et al., 2024)表明,注意力分数通常表现出空间连续性,这表明相邻的键往往具有相似的重要性水平。我们在第 6.2 节中的可视化也展示了这种空间连续模式。
为了实现分块选择,我们首先将键和值序列划分为选择块。为了识别对注意力计算最重要的块,我们需要为每个块分配重要性分数。下面我们介绍计算这些块级重要性分数的方法。
重要性分数的计算:
计算块重要性分数可能会引入显著的开销。幸运的是,压缩令牌的注意力计算会生成中间注意力分数,我们可以利用这些分数来推导选择块的重要性分数,公式如下:
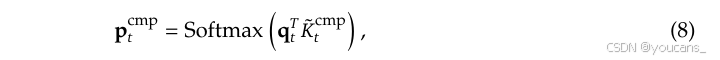
其中, P t c m p P^{cmp}_t Ptcmp 是查询 q t q_t qt 与压缩键 K t c m p K^{cmp}_t Ktcmp 之间的注意力分数。
设
l
′
l^′
l′ 表示选择块的大小。当压缩块和选择块共享相同的分块方案(即
l
′
=
l
=
d
l^′ = l = d
l′=l=d)时,我们可以直接通过
P
s
l
c
,
t
=
P
c
m
p
,
t
P_{slc,t} = P_{cmp,t}
Pslc,t=Pcmp,t 获得选择块的重要性分数。对于分块方案不同的情况,我们根据选择块与压缩块的空间关系推导重要性分数。
给定
l
<
l
′
l \lt l'
l<l′ ,我们有:
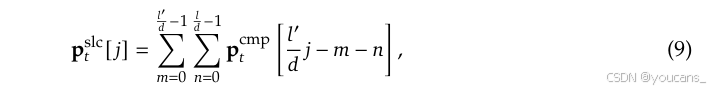
其中,[⋅] 表示用于访问向量元素的索引操作符。对于采用 GQA(Grouped-Query Attention)或 MQA(Multi-Query Attention)的模型,其中键值缓存(KV cache)在查询头之间共享,必须确保这些头之间的一致性块选择,以最小化解码期间的 KV 缓存加载。
组内头之间共享的重要性分数的定义如下:

其中上标中的 (h) 表示头部索引,
H
H
H 是每个组中的查询头部数量。这种聚合确保了同一组内不同头之间的块选择一致。
Top-𝑛块选择
在获得选择块的重要性得分后,我们保留按块重要性得分排名的前n个(top-n)稀疏块中的标记,公式为:
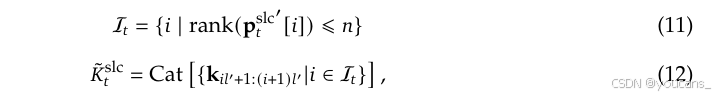
其中 r a n k ( ⋅ ) rank(·) rank(⋅) 表示按降序排列的排名位置, r a n k = 1 rank = 1 rank=1 对应最高得分, I t I_t It是所选块的索引集, C a t Cat Cat 表示连接操作。 K ^ t s l c \hat K^{slc}_t K^tslc 是由压缩键组成的张量。类似的公式也适用于细粒度的值 V ^ t s l c \hat V^{slc}_t V^tslc。然后,所选的键和值按照公式(5)中的定义与 q t q_t qt 一起参与注意力计算。
3.3.3 滑动窗口
在注意力机制中,局部模式通常适应得更快,并可能主导学习过程,从而可能阻止模型有效地从压缩和选择标记中学习。为了解决这个问题,我们引入了一个专门的滑动窗口分支来显式处理局部上下文,使其他分支(压缩和选择)能够专注于学习它们各自的特征,而不会被局部模式所短路。
具体来说,我们维护一个窗口 w w w 内的最近令牌 K ^ t w i n = k t − w : t , V ^ t w i n = v t − w : t \hat K^{win}_t = k_{t-w:t}, \hat V^{win}_t = v_{t-w:t} K^twin=kt−w:t,V^twin=vt−w:t ,并将不同信息源(压缩令牌、选择令牌、滑动窗口)的注意力计算隔离到独立的分支中。然后,这些分支的输出通过一个学习的门控机制进行聚合。为了进一步防止跨注意力分支的“短路学习”并仅引入边际计算开销,我们为三个分支提供独立的键和值。这种架构设计通过防止局部和长距离模式识别之间的梯度干扰,实现了稳定的学习,同时引入了最小的开销。
在获得所有三类键和值( K ^ c m p , t , V ^ c m p , t \hat K_{cmp,t}, \hat V_{cmp,t} K^cmp,t,V^cmp,t; K ^ s l c , t , V ^ s l c , t \hat K_{slc,t}, \hat V_{slc,t} K^slc,t,V^slc,t; K ^ w i n , t , V ^ w w i n , t \hat K_{win,t}, \hat V_{wwin,t} K^win,t,V^wwin,t )后,按照公式(5)计算最终的注意力输出。
结合上述压缩、选择和滑动窗口机制,这构成了 NSA 的完整算法框架。
3.4 内核设计
为了在训练和预填充过程中实现 FlashAttention 级别的加速,我们在 Triton 上实现了硬件对齐的稀疏注意力内核。
考虑到多头注意力(MHA)在解码时内存占用高且效率低下,我们遵循当前最先进的 LLM(大型语言模型)的设计,专注于具有共享 KV 缓存的架构,如GQA和MQA。虽然压缩和滑动窗口注意力计算与现有的 FlashAttention-2 内核很容易兼容,但我们为稀疏选择注意力引入了专门的内核设计。如果我们遵循FlashAttention的策略,将时间上连续的查询块加载到SRAM中,这将导致内存访问效率低下,因为一个块内的查询可能需要不连续的KV块。为了解决这个问题,我们的关键优化在于采用了不同的查询分组策略:对于查询序列中的每个位置,我们将GQA组内所有查询头(它们共享相同的稀疏KV块)加载到SRAM中。图3展示了我们的前向传播实现。
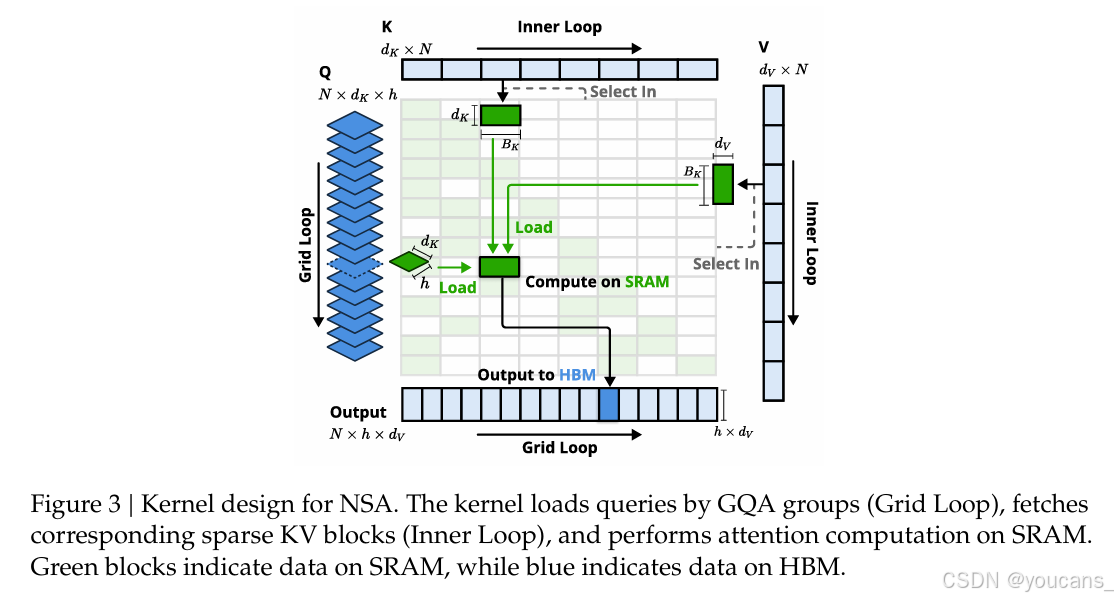
图3:NSA的内核设计。内核按GQA组加载查询(网格循环),获取相应的稀疏KV块(内环),并在SRAM上执行注意力计算。绿色块表示SRAM上的数据,蓝色表示HBM上的数据。
所提出的内核架构具有以下关键特征:
-
以组为中心的数据加载。
对于每个内部循环,加载位于位置 t t t 的组内所有头的查询 Q Q Q 及其共享的稀疏键/值块索引 I t I_t It。 -
共享KV获取。
在内部循环中,按顺序将 I t I_t It 索引的连续键/值块加载到 SRAM 中作为 K , V K, V K,V,以最小化内存加载,其中 B k B_k Bk 是满足 B k ∣ l ′ B_k|l' Bk∣l′ 的内核块大小。 -
网格上的外部循环。
由于不同查询块的内部循环长度(与选择的块数 n 成正比)几乎相同,我们将查询/输出循环放在 Triton 的网格调度器中,以简化和优化内核。
这种设计通过(1)通过组级共享消除冗余的KV传输,以及(2)在GPU流多处理器之间平衡计算工作量,实现了接近最优的算术强度。
4. 实验结果
我们通过三个角度来评估NSA:(1)一般基准性能,(2)长上下文基准性能,以及(3)思维链推理性能,与全注意力基线和最先进的稀疏注意力方法进行比较。我们将稀疏计算范式的效率分析推迟到第5节,在那里我们提供了关于训练和推理速度的详细讨论。
4.1 预训练设置
遵循当前最先进的大型语言模型(LLM)的通用做法,我们的实验采用了一个结合分组查询注意力(GQA)和混合专家(MoE)的骨干网络,该网络总共有270亿个参数,其中30亿个为活跃参数。模型由30层组成,隐藏层维度为2560。
对于GQA,我们将组数设置为4,总共有64个注意力头。对于每个头,查询、键和值的隐藏层维度分别配置为𝑑𝑞 = 𝑑𝑘 = 192和𝑑𝑣 = 128。对于MoE,我们使用了DeepSeekMoE(Dai等,2024;DeepSeek-AI,2024)结构,其中有72个路由专家和2个共享专家,并将top-k专家设置为6。为了确保训练稳定性,第一层的MoE被替换为SwiGLU形式的MLP。所提出的架构在计算成本和模型性能之间实现了有效的权衡。
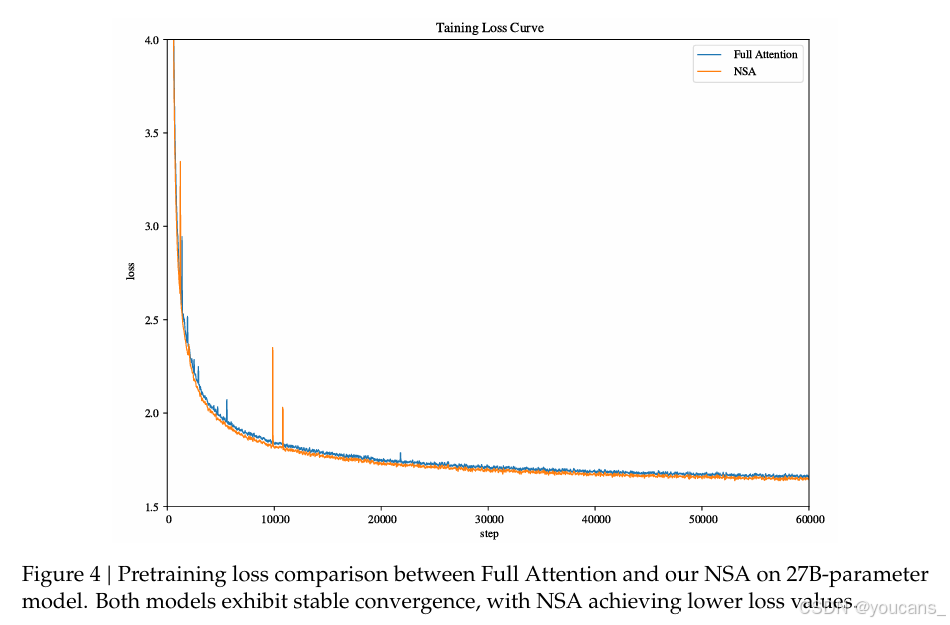
对于新提出的稀疏注意力机制(NSA),我们设置压缩块大小𝑙 = 32,滑动步长𝑑 = 16,选择块大小𝑙′ = 64,选择块数量𝑛 = 16(包括固定激活的1个初始块和2个局部块),以及滑动窗口大小𝑤 = 512。全注意力模型和稀疏注意力模型都在2700亿个8K长度文本的标记上进行预训练,然后继续在32K长度文本的YaRN(Peng等,2024)上进行持续训练和监督微调,以实现长上下文适应。两个模型都训练到完全收敛,以确保公平比较。
如图4 所示,我们的NSA和全注意力基线模型的预训练损失曲线都呈现出稳定且平滑的下降趋势,其中NSA始终优于全注意力模型。
4.2 基线方法
4.2. 基线方法
除了与全注意力(Full Attention)进行比较外,我们还评估了几种最先进的推理阶段稀疏注意力方法:H2O(Zhang等人,2023b)、infLLM(Xiao等人,2024a)、Quest(Tang等人,2024)以及Exact-Top。Exact-Top方法首先计算全注意力分数,并选择每个查询对应的前n个最高分数键,然后计算这些位置上的注意力。这些方法涵盖了多种稀疏注意力范式,包括键值缓存驱逐(KV-cache eviction)、查询感知选择(query-aware selection)以及精确的前n稀疏选择(exact top-𝑛 sparse selection)。
在大多数样本长度都在稀疏注意力基线方法的局部上下文窗口内的常规评估中,这些方法实际上与全注意力是等效的。因此,在这种设置下,我们只展示了非对称注意力(NSA)与全注意力基线之间的比较结果。
在长上下文评估中,我们对所有基线方法进行了比较,为确保公平比较,将所有稀疏注意力方法的稀疏度设置为相同。对于需要进行长文本监督微调的思维链推理评估,由于稀疏注意力基线方法不支持训练,因此我们的比较仅限于全注意力。
4.3 性能评估
常规评估。
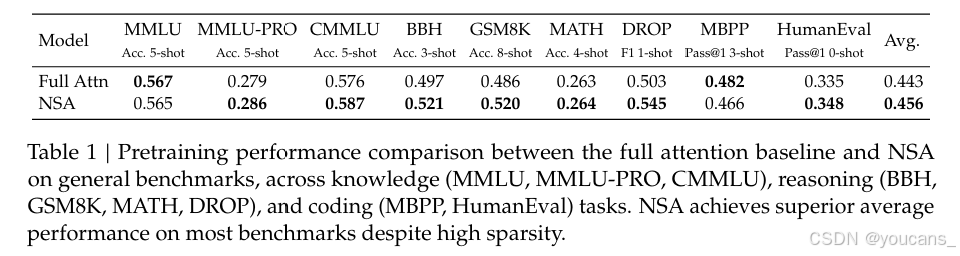
我们在涵盖知识、推理和编码能力的一系列综合基准测试上评估了预训练的NSA(非对称注意力)和全注意力基线,包括MMLU(Hendrycks等人,2020)、MMLU-PRO(Wang等人,2024)、CMMLU(Li等人,2023)、BBH(Suzgun等人,2022)、GSM8K(Cobbe等人,2021)、MATH(Hendrycks等人,2020)、DROP(Dua等人,2019)、MBPP(Austin等人,2021)和HumanEval(Chen等人,2021)。结果如表1所示。尽管NSA具有稀疏性,但其整体性能卓越,在9项指标中有7项超越了包括全注意力在内的所有基线。这表明,尽管NSA在较短序列上可能无法充分发挥其效率优势,但其表现依然强劲。值得注意的是,NSA在推理相关基准测试(DROP:+0.042,GSM8K:+0.034)中取得了显著进步,这表明我们的预训练有助于模型开发专门的注意力机制。这种稀疏注意力预训练机制迫使模型关注最重要的信息,可能通过过滤掉无关注意力路径中的噪声来提高性能。在多种评估中表现一致也验证了NSA作为通用架构的稳健性。
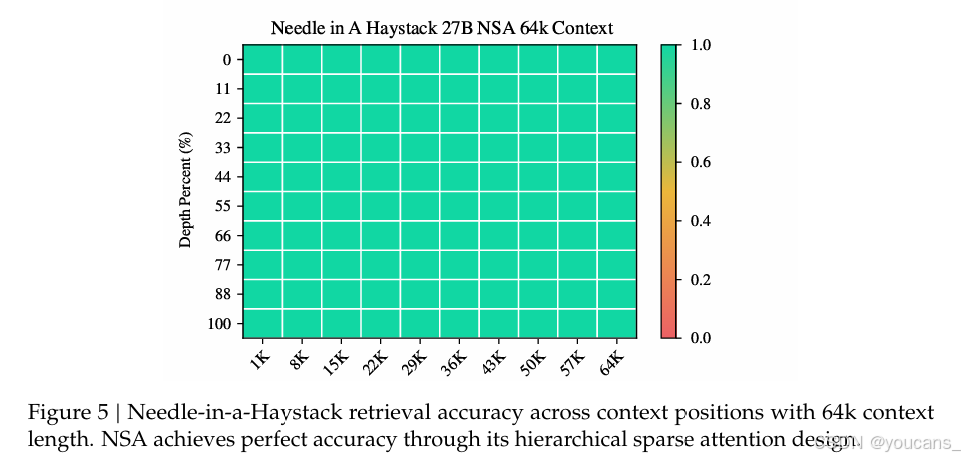
长上下文评估。
如图5所示,NSA 在 64k 上下文的“大海捞针”测试(Kamradt, 2023)中,在所有位置上都实现了完美的检索准确率。这一性能源于我们的分层稀疏注意力设计,该设计结合了用于高效全局上下文扫描的压缩令牌和用于精确局部信息检索的选择令牌。粗粒度的压缩以低计算成本识别相关上下文块,而对选定令牌的细粒度注意力确保了关键细节信息的保留。这种设计使 NSA 能够同时保持全局感知和局部精度。
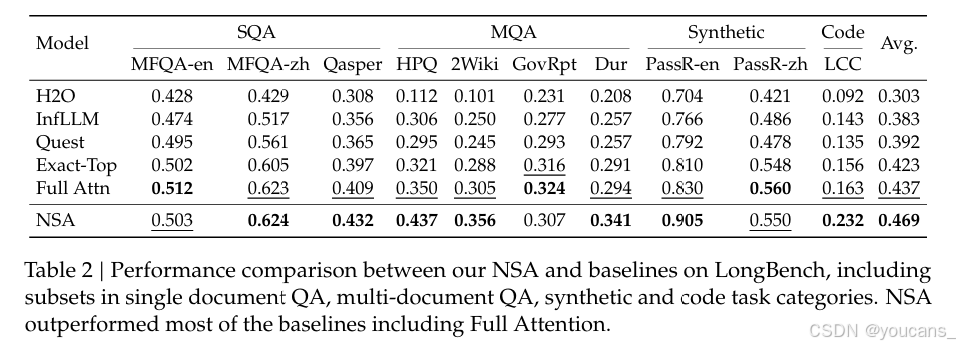
我们还在 LongBench(Bai et al., 2023)上对 NSA 进行了评估,并与最先进的稀疏注意力方法和全注意力基线进行了比较。为了确保稀疏性一致,我们在所有稀疏注意力基线中将每个查询激活的令牌数设置为 2560 个,这对应于 NSA 在处理 32k 序列长度时激活的平均令牌数。遵循 StreamLLM(Xiao et al., 2023)的设置,此令牌预算包括前导的 128 个令牌和 512 个局部令牌。由于某些子集在所有模型上的得分较低,可能无法提供有意义的比较,因此我们从 LongBench 中排除了这些子集。如表2所示,NSA 取得了最高的平均得分 0.469,优于所有基线(比全注意力高 +0.032,比 Exact-Top 高 +0.046)。这一改进源于两项关键创新:(1)我们的原生稀疏注意力设计,支持在预训练期间对稀疏模式进行端到端优化,促进了稀疏注意力模块与其他模型组件之间的同步适应;(2)分层稀疏注意力机制在局部和全局信息处理之间实现了平衡。
值得注意的是,NSA 在需要长上下文复杂推理的任务上表现出色,在多跳问答任务(HPQ 和 2Wiki)上比全注意力分别提高了 +0.087 和 +0.051,在代码理解任务(LCC:+0.069)上超越了基线性能,并在段落检索任务(PassR-en:+0.075)上优于其他方法。这些结果验证了 NSA 处理多样化长上下文挑战的能力,其原生预训练的稀疏注意力为学习任务最优模式提供了额外优势。
思维链推理评估。
为了评估NSA(非对称注意力)与先进下游训练范式的兼容性,我们研究了其通过训练后获取思维链数学推理能力的能力。考虑到强化学习在较小规模模型上的效果有限,我们从DeepSeek-R1进行知识蒸馏,使用包含32k长度数学推理轨迹的100亿个令牌进行监督微调(SFT)。这产生了两个可比模型:Full Attention-R(全注意力基线)和NSA-R(我们的稀疏变体)。我们在具有挑战性的美国邀请数学考试(AIME 24)基准测试上评估了这两个模型。我们使用采样温度为0.7和top-𝑝值为0.95来为每个问题生成16个响应,并计算平均分数。为了验证推理深度的影响,我们进行了两个生成上下文限制的实验:8k和16k令牌,以衡量扩展的推理链是否能提高准确性。模型预测的示例比较见附录A。如表3所示,在8k上下文设置下,NSA-R的准确性显著高于Full Attention-R(+0.075),并且在16k上下文下这一优势依然存在(+0.054)。
这些结果验证了原生稀疏注意力的两个关键优势:(1)预训练的稀疏注意力模式能够高效地捕捉复杂数学推导中至关重要的长距离逻辑依赖;(2)我们的架构与硬件对齐的设计保持了足够的上下文密度,以支持不断增加的推理深度,而不会导致灾难性遗忘。在不同上下文长度下的一致优越表现证实了稀疏注意力在原生集成到训练流水线中时,对于高级推理任务的可行性。

5. 效率分析
我们在一个 8块A100 GPU的系统上评估了NSA(非对称注意力)相对于全注意力的计算效率。在效率分析中,我们还配置了模型,设置GQA组数 g = 4 g=4 g=4,每组头数 h = 16 h=16 h=16,查询/键维度 d k = 192 d_k = 192 dk=192,以及值维度 d v = 128 d_v=128 dv=128。遵循第 4 节中的相同设置,我们将 NSA 的压缩块大小设为 l = 32 l=32 l=32,滑动步长设为 d = 16 d=16 d=16,选定块大小设为 l ′ = 64 l'=64 l′=64,选定块数量设为 n = 16 n=16 n=16,以及滑动窗口大小设为 w = 512 w=512 w=512。
5.1 训练速度
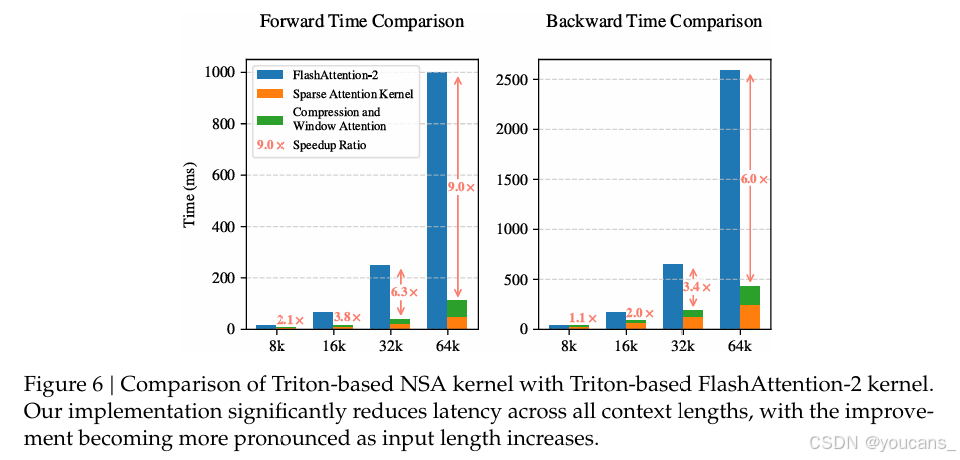
我们将基于Triton的NSA注意力和全注意力实现与基于Triton的FlashAttention-2进行了比较,以确保在同一后端上进行公平的速度对比。
如图6 所示,随着上下文长度的增加,我们的NSA实现了逐渐更大的加速比,在64k上下文长度时,前向加速比高达9.0倍,后向加速比高达6.0倍。值得注意的是,随着序列长度的增加,速度优势变得更加明显。这种加速得益于我们与硬件对齐的算法设计,最大限度地提高了稀疏注意力架构的效率:(1)块式内存访问模式通过合并加载最大限度地提高了Tensor Core的利用率;(2)内核中的精细循环调度消除了冗余的KV传输。
5.2 解码速度
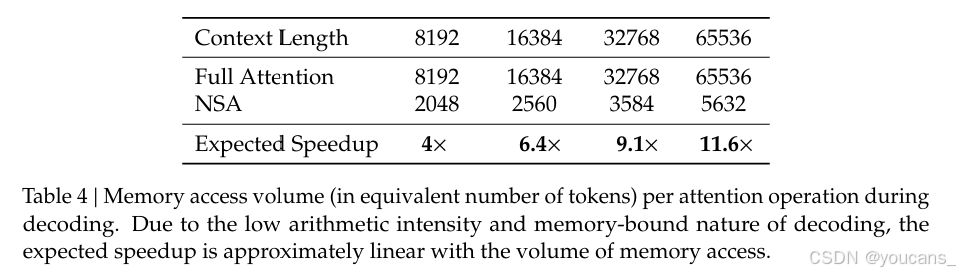
注意力的解码速度主要受内存访问瓶颈的限制,这与KV缓存加载的量紧密相关。
在每一步解码中,我们的NSA(非对称注意力)仅需加载最多 s − l d \frac{s-l}{d} ds−l 个压缩令牌、 n l ′ nl' nl′ 个选定令牌和 w w w 个相邻令牌,其中 s s s 是缓存的序列长度。
如表4所示,随着解码长度的增加,我们的方法在延迟方面表现出显著的减少,在64k上下文长度时实现了高达11.6倍的加速。这种内存访问效率的优势也会随着序列长度的增加而放大。
6. 讨论
在本节中,我们回顾了 NSA 的开发过程,并讨论了从探索不同稀疏注意力策略中获得的关键见解。尽管我们的方法展示了令人鼓舞的结果,但理解替代策略所遇到的挑战并分析注意力模式为未来的研究方向提供了宝贵的背景。我们首先探讨了促使我们设计选择的其他令牌选择策略的挑战,然后通过可视化展示注意力分布模式,以提供更深入的见解。
6.1 替代令牌选择策略的挑战
在设计 NSA 之前,我们尝试将现有的稀疏注意力方法适应到训练阶段。然而,这些尝试遇到了各种挑战,促使我们设计了一种不同的稀疏注意力架构:
-
基于键聚类的策略:
我们研究了基于聚类的策略,例如 ClusterKV(Liu et al., 2024)。这些方法将来自同一聚类的键和值存储在连续的内存区域中。尽管在理论上适用于训练和推理,但它们面临三个重大挑战:(1)动态聚类机制引入的非平凡计算开销;(2)由于聚类间不平衡导致的算子优化困难,尤其是在混合专家系统(MoE)中,倾斜的专家并行(EP)组执行时间会导致持续的负载不平衡;(3)由于需要强制性的定期重新聚类和分块顺序训练协议而引发的实现限制。这些因素共同构成了显著的瓶颈,极大地限制了它们在实际部署中的有效性。 -
其他分块选择策略。
我们还考虑了与NSA(非对称注意力)不同的分块键、值选择策略,如Quest(Tang et al., 2024)和InfLLM(Xiao et al., 2024a)。这些方法依赖于为每个KV块计算重要性分数,并根据它们与𝑞𝑡的相似性选择前𝑛个块。然而,现有方法面临两个关键问题:(1)由于选择操作是不可微的,基于神经网络的重要性分数计算依赖于辅助损失,这增加了算子开销,并且往往会降低模型性能;(2)启发式且无参数的重要性分数计算策略存在召回率低的问题,导致性能不佳。我们在一个具有相似架构的30亿参数模型上评估了这两种方法,并将它们的损失曲线与NSA和全注意力进行了比较。
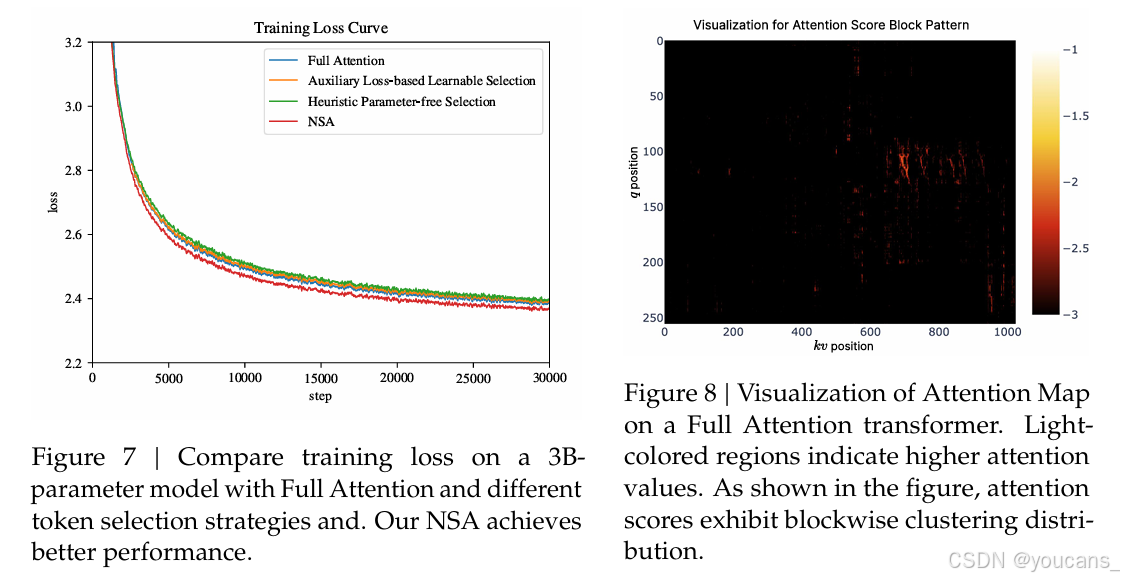
对于基于辅助损失的选择方法,我们为每个令牌引入了额外的查询,并为每个块引入了代表性键,以估计块的重要性分数。我们通过在每个键块内对注意力分数进行平均池化来计算块级监督信号,并使用KL散度来监督块重要性预测。我们保持了单个查询的粒度,而不是块平均查询,以适应高效解码。这种基于辅助损失的重要性估计与SeerAttention(Gao et al., 2024)在概念上具有相似性。对于启发式且无参数的选择方法,我们遵循Quest的策略,直接使用查询和键块坐标范围内的最小-最大值的乘积进行选择,而不引入额外参数。我们还探索了一种冷启动训练方法,即在过渡到启发式分块选择之前,先使用全注意力进行前1000步的训练。如图7所示,这两种方法的损失均表现不佳。
6.2 可视化
为了探索Transformer注意力分布中的潜在模式并为我们的设计寻找灵感,我们在图8中可视化了来自我们预训练的27B全注意力模型的注意力图。
可视化结果揭示了一些有趣的模式,其中注意力分数往往呈现出分块聚集的特征,相邻的键通常具有相似的注意力分数。这一观察结果启发了我们设计NSA(非对称注意力),表明基于空间连续性选择键块可能是一种有前景的方法。
分块聚集现象表明,序列中相邻的令牌可能与查询令牌具有某种语义关系,尽管这些关系的确切性质需要进一步研究。这一观察结果促使我们探索一种稀疏注意力机制,该机制作用于连续的令牌块而不是单个令牌,旨在提高计算效率并保留高注意力模式。
7. 相关工作
我们回顾了通过稀疏注意力提高注意力计算效率的现有方法。这些方法根据其核心策略可以大致分为三类:(1)固定稀疏模式,(2)动态令牌剪枝,以及(3)查询感知选择。我们从每一类别中介绍几种代表性工作。
7.1 固定稀疏模式
滑动窗口是一种常用的方法,它允许查询仅在固定窗口内计算注意力。
StreamingLLM(Xiao et al., 2023)将注意力汇聚点与局部窗口结合,以处理连续文本流。MoA(Fu et al., 2024a)和 DuoAttention(Xiao et al., 2024b)也采用类似的局部和汇聚点信息进行长序列建模。Longformer(Beltagy et al., 2020)通过交替使用局部窗口注意力和全局令牌来处理长序列。
与这些方法相比,NSA 的优点在于,不依赖于预定义的稀疏模式,而是自动学习模式,从而充分利用了完整上下文。
7.2 动态令牌剪枝
一些方法旨在通过动态 KV 缓存剪枝来减少推理期间的内存和计算成本。
H2O(Zhang et al., 2023b)、BUZZ(Zhao et al., 2024)和 SepLLM(Chen et al., 2024a)实现了自适应方法以减少解码期间的 KV 缓存内存使用。这些方法动态地剔除被认为对未来预测不太重要的令牌。FastGen(Ge et al., 2023)和 HeadKV(Fu et al., 2024b)通过为每个注意力头分配不同的策略来优化计算。SnapKV(Li et al., 2024)引入了一种令牌剪枝策略,通过选择性保留最关键的特征来减少 KV 缓存,从而实现高效的内存使用。
与这些专注于推理的方法不同,NSA 的优点在于,在训练阶段原生地引入了稀疏性。
7.3 查询感知选择
其他工作专注于依赖查询的令牌选择方法,以减少注意力计算同时保持注意力质量。
Quest(Tang et al., 2024)采用分块选择策略,通过查询与键块的逐坐标最小-最大值的乘积来估计每个块的重要性。InfLLM(Xiao et al., 2024a)通过维护注意力汇聚点、局部上下文和可检索块,将固定模式与检索结合。该方法从每个块中选择代表性键来估计块的重要性。HashAttention(Desai et al., 2024)通过使用学习函数将查询和键映射到汉明空间,将关键令牌识别问题表述为推荐问题。ClusterKV(Liu et al., 2024)通过首先对键进行聚类,然后根据查询-聚类相似性选择最相关的聚类进行注意力计算来实现稀疏性。MInference(Jiang et al., 2024)和 TokenSelect(Wu et al., 2024)基于令牌级重要性评分选择 KV 对进行计算。SeerAttention(Gao et al., 2024)将查询和键分离到空间块中,并执行分块选择以实现高效计算。
与这些方法相比,NSA 的优点在于,在整个模型生命周期(包括训练、预填充和解码)中实现了硬件对齐的稀疏注意力计算。
8. 结论
我们提出了NSA,一种面向高效长上下文建模的与硬件对齐的稀疏注意力架构。通过在可训练的架构内将分层令牌压缩与分块令牌选择相结合,NSA 架构在保持全注意力性能的同时,实现了训练和推理的加速。
NSA通过展示通用的基准性能与全注意力基线相匹配、在长上下文评估中超越建模能力、以及增强的推理能力,推动了技术的最前沿,所有这些都伴随着计算延迟的可测量减少,并实现了显著的加速。
9. 参考文献
J. Ainslie, J. Lee-Thorp, M. de Jong, Y. Zemlyanskiy, F. Lebrón, and S. Sanghai. Gqa: Training generalized multi-query transformer models from multi-head checkpoints. arXiv preprint arXiv:2305.13245, 2023.
J. Austin, A. Odena, M. Nye, M. Bosma, H. Michalewski, D. Dohan, E. Jiang, C. Cai, M. Terry, Q. Le, et al. Program synthesis with large language models. arXiv preprint arXiv:2108.07732, 2021.
Y. Bai, X. Lv, J. Zhang, H. Lyu, J. Tang, Z. Huang, Z. Du, X. Liu, A. Zeng, L. Hou, et al. Longbench: A bilingual, multitask benchmark for long context understanding. arXiv preprint arXiv:2308.14508, 2023.
I. Beltagy, M. E. Peters, and A. Cohan. Longformer: The long-document transformer. arXiv preprint arXiv:2004.05150, 2020.
G. Chen, H. Shi, J. Li, Y. Gao, X. Ren, Y. Chen, X. Jiang, Z. Li, W. Liu, and C. Huang. Sepllm: Accelerate large language models by compressing one segment into one separator. arXiv preprint arXiv:2412.12094, 2024a.
M. Chen, J. Tworek, H. Jun, Q. Yuan, H. P. D. O. Pinto, J. Kaplan, H. Edwards, Y. Burda, N. Joseph, G. Brockman, et al. Evaluating large language models trained on code. arXiv preprint arXiv:2107.03374, 2021.
Z. Chen, R. Sadhukhan, Z. Ye, Y. Zhou, J. Zhang, N. Nolte, Y. Tian, M. Douze, L. Bottou, Z. Jia, et al. Magicpig: Lsh sampling for efficient llm generation. arXiv preprint arXiv:2410.16179, 2024b.
K. Cobbe, V. Kosaraju, M. Bavarian, M. Chen, H. Jun, L. Kaiser, M. Plappert, J. Tworek, J. Hilton, R. Nakano, et al. Training verifiers to solve math word problems, 2021. URL https://arxiv. org/abs/2110.14168, 2021.
D. Dai, C.Deng, C.Zhao,R.Xu,H.Gao,D.Chen,J.Li,W.Zeng,X.Yu,Y.Wu,etal. Deepseekmoe: Towards ultimate expert specialization in mixture-of-experts language models. arXiv preprint arXiv:2401.06066, 2024.
DeepSeek-AI. Deepseek-v2: A strong, economical, and efficient mixture-of-experts language model. 2024. URL https://arxiv.org/abs/2405.04434.
DeepSeek-AI. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning, 2025. URL https://arxiv.org/abs/2501.12948.
A. Desai, S. Yang, A. Cuadron, A. Klimovic, M. Zaharia, J. E. Gonzalez, and I. Stoica. Hashattention: Semantic sparsity for faster inference. arXiv preprint arXiv:2412.14468, 2024.
D. Dua, Y. Wang, P. Dasigi, G. Stanovsky, S. Singh, and M. Gardner. Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. arXiv preprint arXiv:1903.00161, 2019.
T. Fu, H. Huang, X. Ning, G. Zhang, B. Chen, T. Wu, H. Wang, Z. Huang, S. Li, S. Yan, et al. Moa: Mixture of sparse attention for automatic large language model compression. arXiv preprint arXiv:2406.14909, 2024a.
Y. Fu, Z. Cai, A. Asi, W. Xiong, Y. Dong, and W. Xiao. Notall heads matter: A head-level kv cache compression method with integrated retrieval and reasoning. arXiv preprint arXiv:2410.19258, 2024b.
Y. Gao, Z. Zeng, D. Du, S. Cao, H. K.-H. So, T. Cao, F. Yang, and M. Yang. Seerattention: Learning intrinsic sparse attention in your llms. arXiv preprint arXiv:2410.13276, 2024.
S. Ge, Y. Zhang, L. Liu, M. Zhang, J. Han, and J. Gao. Model tells you what to discard: Adaptive kv cache compression for llms. arXiv preprint arXiv:2310.01801, 2023.
G. T. Google, P. Georgiev, V. I. Lei, R. Burnell, L. Bai, A. Gulati, G. Tanzer, D. Vincent, Z. Pan, S. Wang, et al. Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context. arXiv preprint arXiv:2403.05530, 2024.
D. Hendrycks, C. Burns, S. Basart, A. Zou, M. Mazeika, D. Song, and J. Steinhardt. Measuring massive multitask language understanding. arXiv preprint arXiv:2009.03300, 2020.
H. Jiang, Q. Wu, C.-Y. Lin, Y. Yang, and L. Qiu. Llmlingua: Compressing prompts for accelerated inference of large language models. arXiv preprint arXiv:2310.05736, 2023.
H. Jiang, Y. Li, C. Zhang, Q. Wu, X. Luo, S. Ahn, Z. Han, A. H. Abdi, D. Li, C.-Y. Lin, et al. Minference 1.0: Accelerating pre-filling for long-context llms via dynamic sparse attention. arXiv preprint arXiv:2407.02490, 2024.
G. Kamradt. LLMTest NeedleInAHaystack. GitHub repository, 2023. URL https://github.com/gkamradt/LLMTest_NeedleInAHaystack. Accessed: [Insert Access Date Here].
H. Li, Y. Zhang, F. Koto, Y. Yang, H. Zhao, Y. Gong, N.Duan, andT.Baldwin. Cmmlu: Measuring massive multitask language understanding in chinese. arXiv preprint arXiv:2306.09212, 2023.
Y. Li, Y. Huang, B. Yang, B. Venkitesh, A. Locatelli, H. Ye, T. Cai, P. Lewis, and D. Chen. Snapkv: Llmknowswhatyouarelooking for before generation. arXiv preprint arXiv:2404.14469, 2024.
G. Liu, C. Li, J. Zhao, C. Zhang, and M. Guo. Clusterkv: Manipulating llm kv cache in semantic space for recallable compression. arXiv preprint arXiv:2412.03213, 2024.
J. S. Park, J. C. O’Brien, C. J. Cai, M. R. Morris, P. Liang, and M. S. Bernstein. Generative agents: Interactive simulacra of human behavior. In S. Follmer, J. Han, J. Steimle, and N. H. Riche, editors, Proceedings of the 36th Annual ACM Symposium on User Interface Software and Technology, UIST 2023, San Francisco, CA, USA, 29 October 2023–1 November 2023, pages
2:1–2:22. ACM, 2023
B. Peng, J. Quesnelle, H. Fan, and E. Shippole. Yarn: Efficient context window extension of large language models. In ICLR. OpenReview.net, 2024.
N. Shazeer. Fast transformer decoding: One write-head is all you need. CoRR, abs/1911.02150, 2019.
M. Suzgun, N. Scales, N. Schärli, S. Gehrmann, Y. Tay, H. W. Chung, A. Chowdhery, Q. V. Le, E. H. Chi, D. Zhou, et al. Challenging big-bench tasks and whether chain-of-thought can solve them. arXiv preprint arXiv:2210.09261, 2022.
J. Tang, Y. Zhao, K. Zhu, G. Xiao, B. Kasikci, and S. Han. Quest: Query-aware sparsity for efficient long-context llm inference. arXiv preprint arXiv:2406.10774, 2024.
P. Tillet, H.-T. Kung, and D. Cox. Triton: an intermediate language and compiler for tiled neural network computations. In Proceedings of the 3rd ACM SIGPLAN International Workshop on Machine Learning and Programming Languages, pages 10–19, 2019.
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, L. u. Kaiser, and I. Polosukhin. Attention is all you need. Advances in Neural Information Processing Systems, 2017.
Y. Wang, X. Ma, G. Zhang, Y. Ni, A. Chandra, S. Guo, W. Ren, A. Arulraj, X. He, Z. Jiang, et al. Mmlu-pro: A more robust and challenging multi-task language understanding benchmark. arXiv preprint arXiv:2406.01574, 2024.
J. Wei, X. Wang, D. Schuurmans, M. Bosma, F. Xia, E. Chi, Q. V. Le, D. Zhou, et al. Chain of-thought prompting elicits reasoning in large language models. Advances in neural information processing systems, 35:24824–24837, 2022.
W. Wu,Z.Pan, C. Wang, L. Chen, Y. Bai, K. Fu, Z. Wang, and H. Xiong. Tokenselect: Efficient long-context inference and length extrapolation for llms via dynamic token-level kv cache selection. arXiv preprint arXiv:2411.02886, 2024.
C. Xiao, P. Zhang, X. Han, G. Xiao, Y. Lin, Z. Zhang, Z. Liu, and M. Sun. Infllm: Training-free long-context extrapolation for llms with an efficient context memory. In The Thirty-eighth Annual Conference on Neural Information Processing Systems, 2024a.
G. Xiao, Y. Tian, B. Chen, S. Han, and M. Lewis. Efficient streaming language models with attention sinks. arXiv preprint arXiv:2309.17453, 2023
G. Xiao, J. Tang, J. Zuo, J. Guo, S. Yang, H. Tang, Y. Fu, and S. Han. Duoattention: Efficient long context llm inference with retrieval and streaming heads. arXiv preprint arXiv:2410.10819, 2024b.
M. Zaheer, G. Guruganesh, K. A. Dubey, J. Ainslie, C. Alberti, S. Ontanon, P. Pham, A. Ravula, Q. Wang, L. Yang, et al. Big bird: Transformers for longer sequences. Advances in neural information processing systems, 33:17283–17297, 2020.
E. Zelikman, Y. Wu, J. Mu, and N. D. Goodman. Star: Bootstrapping reasoning with reasoning. In S. Koyejo, S. Mohamed, A. Agarwal, D. Belgrave, K. Cho, and A. Oh, editors, Advances in Neural Information Processing Systems 35: Annual Conference on Neural Information Processing Systems 2022, NeurIPS 2022, New Orleans, LA, USA, November 28
December 9, 2022, 2022
F. Zhang, B. Chen, Y. Zhang, J. Keung, J. Liu, D. Zan, Y. Mao, J. Lou, and W. Chen. Repocoder: Repository-level code completion through iterative retrieval and generation. In H. Bouamor, J. Pino, and K. Bali, editors, Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, EMNLP 2023, Singapore, December 6–10, 2023, pages 2471-2484. Association for Computational Linguistics, 2023a.
K. Zhang, J. Li, G. Li, X. Shi, and Z. Jin. Codeagent: Enhancing code generation with tool integrated agent systems for real-world repo-level coding challenges. In L. Ku, A. Martins, and V. Srikumar, editors, Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), ACL 2024, Bangkok, Thailand, August 11–16, 2024, pages 13643–13658.
Z. Zhang, Y. Sheng, T. Zhou, T. Chen, L. Zheng, R. Cai, Z. Song, Y. Tian, C. Ré, C. Barrett, et al. H2o: Heavy-hitter oracle for efficient generative inference of large language models. Advances in Neural Information Processing Systems, 36:34661–34710, 2023b.
J. Zhao, Z. Fang, S. Li, S. Yang, and S. He. Buzz: Beehive-structured sparse kv cache with segmented heavy hitters for efficient llm inference. arXiv preprint arXiv:2410.23079, 2024.
Z. Zhou, C. Li, X. Chen, S. Wang, Y. Chao, Z. Li, H. Wang, R. An, Q. Shi, Z. Tan, et al. Llm × mapreduce: Simplified long-sequence processing using large language models. arXiv preprint arXiv:2410.09342, 2024.
版权声明:
本文由 youcans@xidian 对论文 Native Sparse Attention: Hardware-Aligned and Natively Trainable Sparse Attention 进行摘编和翻译,只供研究学习使用。
youcans@xidian 作品,转载必须标注原文链接:
【DeepSeek论文精读】8. 原生稀疏注意力(NSA)
Copyright 2025 youcans, XIDIAN
Crated:2025-03


















 393
393

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











