






Qwen2.5-Omni-3B是阿里云推出的全能AI模型。它能同时处理视频、音频、图像和文本。只有3B参数,却能在本地运行强大的多模态功能。
近日,已经在Hugging Face上发布。它是小型多模态AI系统的重要突破。
1、 特点

Qwen2.5-Omni-3B与常规语言模型存在显著差异,作为货真价实的多模态系统,它具备同时处理四种内容类型的强大能力。
- 在文本处理方面,Qwen2.5-Omni-3B能够理解并生成丰富多样的语言内容;
- 针对图像分析,它可以精准识别物体与场景,从容解答各类关于视觉信息的疑问;
- 在音频理解领域,该模型支持语音识别、转录工作,并对声音内容进行深入剖析;
- 处理视频时,Qwen2.5-Omni-3B不仅能够描述动作以及场景的动态变化,还可完成时间维度的逻辑推理。
尤为值得一提的是,这一模型仅凭借3B参数便实现上述功能,这使得它能够在计算资源相对匮乏的条件下正常运行 。
2、 技术架构
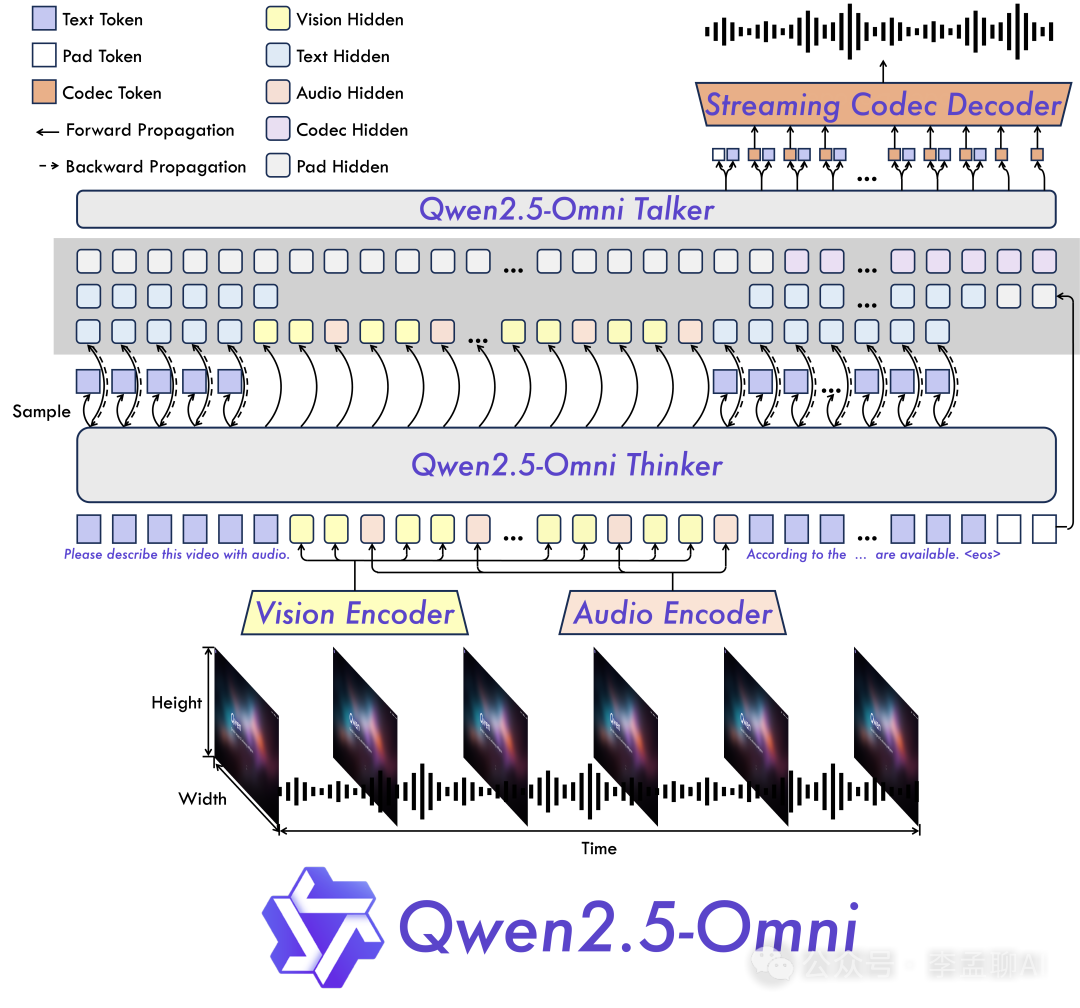
技术架构上,它基于Qwen 2.5模型系列,增加了专门的多模态处理组件。
- Qwen2.5-Omni-3B有统一的Transformer骨干网络,作为基础文本处理管道。
- Qwen2.5-Omni-3B有视觉处理模块,用于提取和理解图像与视频帧的特征。
- Qwen2.5-Omni-3B有音频处理管道,将声波转换为可处理的嵌入向量。
- Qwen2.5-Omni-3B有跨模态注意力机制,建立不同模态之间的连接。
技术创新点包括高效的参数共享,将所有输入作为序列处理,以及使用投影层将不同模态特征映射到共享的嵌入空间。
3、 功能
- 在视频理解方面,它可以描述视频内容,识别动作,检测场景变化,进行时间推理,并回答关于视频的问题。
- 在音频处理方面,它可以进行语音识别和转录,识别说话者,理解音频场景,检测声音事件,回答基于音频的问题。
- 在图像理解方面,它提供详细的图像描述,物体检测和识别,场景理解,视觉问答和基于图像的推理。
- 在文本处理方面,它保持了强大的语言理解能力,可以生成内容,做摘要,回答问题,进行翻译。
Qwen2.5-Omni-3B的真正力量在于整合多模态信息的能力。它可以回答关于带音频的视频的问题,描述文本与图像的关系,基于多模态输入生成文本,从混合媒体内容创建连贯的叙述。
4、测试
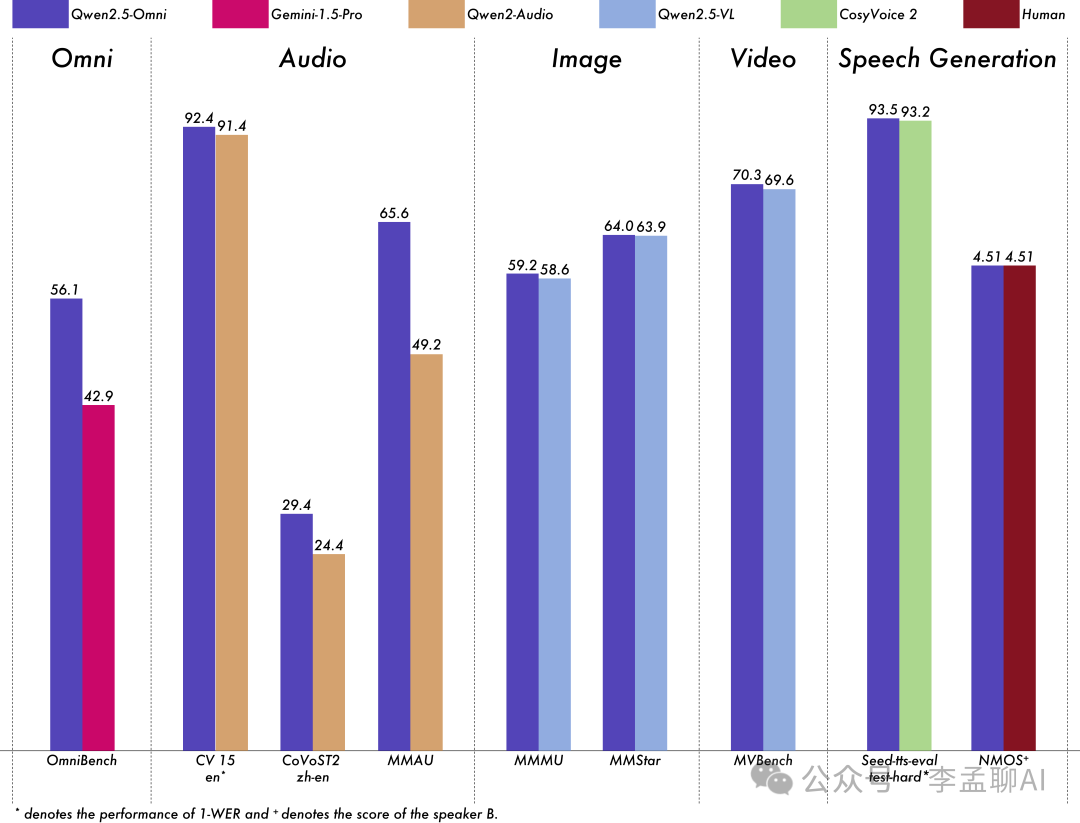
性能测试显示,它在多个基准测试中表现出色,效率高,有时甚至超过了参数量更大的模型。
5、 本地部署
以下是如何使用Python在本地运行模型的方法,不需要任何云端GPU!
第一步:安装必要依赖
运行以下命令设置环境:
pip install torch torchvision torchaudio einops timm pillow
pip install git+https://github.com/huggingface/transformers@v4.51.3-Qwen2.5-Omni-preview
pip install accelerate
pip install git+https://github.com/huggingface/diffusers
pip install huggingface_hub
pip install sentencepiece bitsandbytes protobuf decord numpy av
pip install qwen-omni-utils[decord] -U
第二步:导入模块并加载模型
import soundfile as sf
import torch
from transformers import Qwen2_5OmniForConditionalGeneration, Qwen2_5OmniProcessor
from qwen_omni_utils import process_mm_info
model = Qwen2_5OmniForConditionalGeneration.from_pretrained(
"Qwen/Qwen2.5-Omni-3B",
torch_dtype="auto",
device_map="auto",
attn_implementation="flash_attention_2", # Boost performance
)
processor = Qwen2_5OmniProcessor.from_pretrained("Qwen/Qwen2.5-Omni-3B")
第三步:准备多模态对话
以下是如何输入包含音频的视频和系统上下文:
conversation = [
{
"role": "system",
"content": [
{"type": "text", "text": "You are Qwen, a virtual human developed by the Qwen Team, Alibaba Group, capable of perceiving auditory and visual inputs, as well as generating text and speech."}
],
},
{
"role": "user",
"content": [
{"type": "video", "video": "https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen2.5-Omni/draw.mp4"},
],
},
]
第四步:处理并运行推理
USE_AUDIO_IN_VIDEO = True
# Convert chat template and extract inputs
text = processor.apply_chat_template(conversation, add_generation_prompt=True, tokenize=False)
audios, images, videos = process_mm_info(conversation, use_audio_in_video=USE_AUDIO_IN_VIDEO)
# Tokenize & format input tensors
inputs = processor(
text=text,
audio=audios,
images=images,
videos=videos,
return_tensors="pt",
padding=True,
use_audio_in_video=USE_AUDIO_IN_VIDEO
)
inputs = inputs.to(model.device).to(model.dtype)
# Generate text and audio response
text_ids, audio = model.generate(**inputs, use_audio_in_video=USE_AUDIO_IN_VIDEO)
# Decode text
response_text = processor.batch_decode(text_ids, skip_special_tokens=True, clean_up_tokenization_spaces=False)
print(response_text)
第五步:保存音频输出(可选)
🎧 现在你可以听到模型从多模态输入生成的语音响应!
sf.write(
"output.wav",
audio.reshape(-1).detach().cpu().numpy(),
samplerate=24000,
)
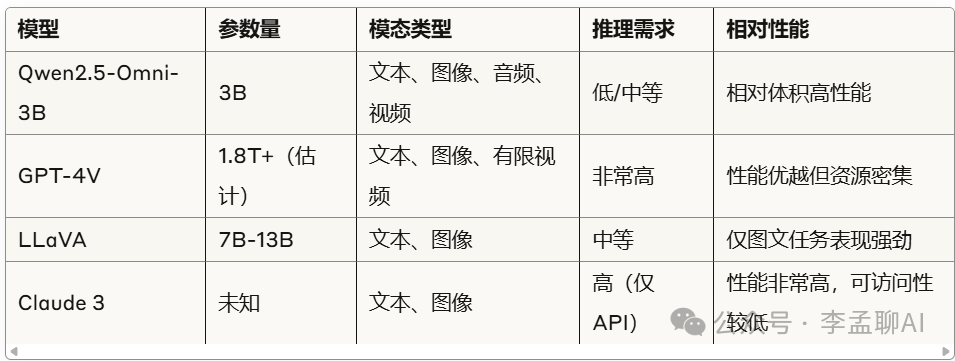
与其他多模态模型对比
6、 结语
Qwen2.5-Omni-3B代表了多模态AI普及化的重要一步。它将视频、音频、图像和文本处理打包到一个紧凑的3B参数模型中,平衡了功能和实用性。
对于开发者、研究人员和组织来说,这是一个不需要大量计算资源就能实现多模态AI的解决方案。在Hugging Face上的可用性进一步降低了使用门槛。
随着多模态AI的发展,像Qwen2.5-Omni-3B这样紧凑而功能强大的模型将在日常应用中发挥关键作用。无论是构建内容审核系统、教育平台还是辅助工具,这个模型都提供了一个有力的基础。
那么,如何系统的去学习大模型LLM?
作为一名从业五年的资深大模型算法工程师,我经常会收到一些评论和私信,我是小白,学习大模型该从哪里入手呢?我自学没有方向怎么办?这个地方我不会啊。如果你也有类似的经历,一定要继续看下去!这些问题啊,也不是三言两语啊就能讲明白的。
所以我综合了大模型的所有知识点,给大家带来一套全网最全最细的大模型零基础教程。在做这套教程之前呢,我就曾放空大脑,以一个大模型小白的角度去重新解析它,采用基础知识和实战项目相结合的教学方式,历时3个月,终于完成了这样的课程,让你真正体会到什么是每一秒都在疯狂输出知识点。
由于篇幅有限,⚡️ 朋友们如果有需要全套 《2025全新制作的大模型全套资料》,扫码获取~

👉大模型学习指南+路线汇总👈
我们这套大模型资料呢,会从基础篇、进阶篇和项目实战篇等三大方面来讲解。


👉①.基础篇👈
基础篇里面包括了Python快速入门、AI开发环境搭建及提示词工程,带你学习大模型核心原理、prompt使用技巧、Transformer架构和预训练、SFT、RLHF等一些基础概念,用最易懂的方式带你入门大模型。

👉②.进阶篇👈
接下来是进阶篇,你将掌握RAG、Agent、Langchain、大模型微调和私有化部署,学习如何构建外挂知识库并和自己的企业相结合,学习如何使用langchain框架提高开发效率和代码质量、学习如何选择合适的基座模型并进行数据集的收集预处理以及具体的模型微调等等。

👉③.实战篇👈
实战篇会手把手带着大家练习企业级的落地项目(已脱敏),比如RAG医疗问答系统、Agent智能电商客服系统、数字人项目实战、教育行业智能助教等等,从而帮助大家更好的应对大模型时代的挑战。

👉④.福利篇👈
最后呢,会给大家一个小福利,课程视频中的所有素材,有搭建AI开发环境资料包,还有学习计划表,几十上百G素材、电子书和课件等等,只要你能想到的素材,我这里几乎都有。我已经全部上传到CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

相信我,这套大模型系统教程将会是全网最齐全 最易懂的小白专用课!!

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









