







Paper:Focal Loss for Dense Object Detection :https://arxiv.org/abs/1708.02002
1、Focal Loss for Dense Object Detection 论文解读 https://blog.csdn.net/julialove102123/article/details/79709839
2、如何评价Kaiming的Focal Loss for Dense Object Detection? https://www.zhihu.com/question/63581984
大体解决的问题
众所周知,detector主要分为以下两大门派:
| - | one stage系 | two stage系 |
|---|---|---|
| 代表性算法 | YOLOv1、SSD、YOLOv2、YOLOv3 | R-CNN、SPPNet、Fast R-CNN、Faster R-CNN |
| 检测精度 | 低 | 高 |
| 检测速度 | 快 | 慢 |
这种鱼(speed)与熊掌(accuracy)不可兼得的局面一直成为Detection的瓶颈。在论文中作者去探讨了造成one stage精度低的原因,发现在训练密集目标检测器的过程中出现了严重的foreground-background类别不平衡。
类别不平衡(class imbalance)是目标检测模型训练的一大难点(推荐这篇综述文章Imbalance Problems in Object Detection: A Review),其中最严重的是正负样本不平衡,因为一张图像的物体一般较少,而目前大部分的目标检测模型在FCN上每个位置密集抽样,无论是基于anchor的方法还是anchor free方法都如此。对于Faster R-CNN这种two stage模型,第一阶段的RPN可以过滤掉很大一部分负样本,最终第二阶段的检测模块只需要处理少量的候选框,而且检测模块还采用正负样本固定比例抽样(比如1:3)或者OHEM方法(online hard example mining)来进一步解决正负样本不平衡问题。对于one stage方法来说,detection部分要直接处理大量的候选位置,其中负样本要占据绝大部分,SSD的策略是采用hard mining,从大量的负样本中选出loss最大的topk的负样本以保证正负样本比例为1:3。其实RPN本质上也是one stage检测模型,RPN训练时所采取的策略也是抽样,从一张图像中抽取固定数量N(RPN采用的是256)的样本,正负样本分开来随机抽样N/2,如果正样本不足,那就用负样本填充。
究其原因,就是因为one-stage受制于万恶的 “类别不平衡” 。
1、什么是“类别不平衡”呢?
检测算法在早期会生成很多bbox,而在一幅正常的图像中需要检测的object不会很多,顶多就那么几个object。这就意味着绝大多数的bbox是属于background,使得foreground-background类别不平衡。
2、“类别平衡问题”为什么会导致检测精度低呢?
因为bbox数量爆炸, 而这些bbox中属于background的bbox太多了,假设分类器将所有的bbox全部归为background,那么精度accuracy可以刷的很高,这样的分类器是一个失败的分类器,所以导致目标检测的精度很低。
3、那为什么two-stage系就可以避免这个问题呢?
因为two-stage系有RPN罩着。
因为two stage的第一个stage生成一个候选目标位置组成的稀疏样本集,即第一个stage的RPN会对anchor进行简单的二分类(只是简单地区分是前景还是背景,并不区别究竟属于哪个细类)。经过该轮初筛,属于background的bbox被大幅砍削。虽然其数量依然远大于foreground的bbox(例如3:1),但是至少数量差距已经不像最初生成的anchor那样夸张了。这一阶段就等于是 从 “类别 极 不平衡” 变成了 “类别 较 不平衡” 。But(但是),其实two-stage系的detector也不能完全解决类别不平衡问题,只能说是在很大程度上减轻了“类别不平衡”对检测精度所造成的影响。
接着到了第二个stage时,分类器登场,使用一个卷积神经网络将各候选位置归置foreground类别或者background类别,即在初筛过后的bbox上进行难度小得多的第二波分类(这次是细分类)。这样一来,分类器得到了较好的训练,最终的检测精度自然就高啦。但是经过这么两个stage一倒腾,操作复杂,检测速度就被严重拖慢了。
4、那为什么one-stage系无法避免该问题呢?
因为one stage系的detector直接在首波生成的“类别极不平衡”的bbox中就进行难度极大的细分类,意图直接输出bbox和标签(分类结果)。而原有交叉熵损失(CE)作为分类任务的损失函数,无法抗衡“类别极不平衡”,容易导致分类器训练失败。因此,one-stage detector虽然保住了检测速度,却丧失了检测精度。
5、平衡正负样本:
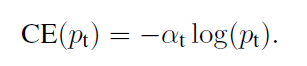
我们为交叉熵加一个权重,α∈[0,1]对于类1,1-α对于类-1。其中权重因子的大小一般为相反类的比重。即负样本不是多吗,它越多,我们给它的权重越小。这样就可以降低负样本的影响。
论文中 α 取0.25。为什么alpha值正样本的权重比负样本还要小?
原因:我们知道alpha 是用来平衡正负样本的,而论文里面的给的alpha=0.25 ,而真实正负样本的比例在 1:10000以上,作者反而缩小正样本的损失
这里主要是因为分类卷积的初始化,论文里把所有样本概率初始化为0.01,而负样本的损失-(0.01)**2*log(1-0.01)=1e-6
所以负样本的在初始化的时候损失是非常小的,pytorch初始化如下
self.class_model[-1].bias.data.fill_(-math.log((1-0.01)/0.01))所以这里的参数仅仅适合这个场景,如果有其他需求还需要自己定制化
参考:https://blog.csdn.net/dsl_gree/article/details/90513797
但是,这只是解决了正负样本的不平衡,并没有解决easy examples和hard examples之间的不平衡。
6、Focal loss 公式分析:
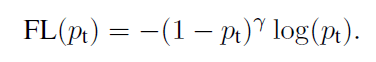
Focal loss 公式如上所示:
对于简单样本easy examples,Pt会比较大,(1-Pt)就会比较小。极端情况:当Pt→1,因子(1-Pt)接近0,那么分的比较好的(well-classified)样本的权值就被调低了。
针对hard example,Pt 比较小,(1-Pt)就会比较大。极端情况:当Pt→0,因子(1-Pt)接近1,那么这些hard example 的权重受影响不大。就是难分样本 Pt 不会趋近于 0,但是既然是 hard example 样本 ,那么Pt也不会很大,经过(1- Pt)的 γ 次方,虽然权重也减小了,但是显然easy examples 权重减小更多
专注参数γ平滑地调节了易分样本调低权值的比例。γ 增大能增强调制因子的影响,实验发现γ取2最好。
直觉上来说,调制因子减少了易分样本的损失贡献,拓宽了样例接收到低损失的范围。举例来说,当γ=2时,一个样本被分类的Pt=0.9的损失比CE小100多倍。这样就增加了那些误分类的重要性(它们损失被缩了4倍多,当Pt<0.5且γ=2)
无论是前景类还是背景类,pt越大,权重 (1-pt) 就越小。也就是说easy example可以通过权重进行抑制。换言之,当某样本类别比较明确些,它对整体loss的贡献就比较少;而若某样本类别不易区分,则对整体loss的贡献就相对偏大。这样得到的loss最终将集中精力去诱导模型去努力分辨那些难分的目标类别,于是就有效提升了整体的目标检测准度。















 5824
5824











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









