







目录
前言
Simulink提供了将模型转换为可优化的嵌入式C代码的功能,为了生成嵌入式代码,至少需要配置3部分:Solver(求解器)、Hardware Implementation(硬件实现) 、Code Generation(代码生成)。
一. 配置设定
1. Solver
推荐红框设置。

仿真时间:开始时间与结束时间分别代表仿真模块的开始与停止时间,关于这部分设置,需要指定仿真或生成的代码的开始时间,双精度值,以秒为单位,默认值0.0,结束时间随个人习惯设置而定,其中 inf 代表仿真停止时间为无限。
注意:1. 开始时间必须小于等于停止时间。
2. 仿真时间与时钟时间不同。总仿真时间取决于模型的复杂度、求解器步长大小和 计算机速度等因素。
求解器选择:选择用于模型仿真的求解器类型。包含:Variable-Step(变步长)、Fixed-Step(固定步长)。
- 当选择变步长时,需要设置参数如下:

最大步长:解算器可以采用的最大步长;
最小步长:解算器可以采用的最小步长;
初始步长:解算器第一步采用的步长;
相对容差:可接受的最大相对误差容限;
绝对容差:可接受的最大绝对误差容限;
形状保持:开启时使用微分信息提升积分的精确度;
连续最小步数:当步长超出了最大步长或小于最小步长时称为步长违例,此选项用于设置连续出现步长违例的步数,一旦超过这个步数就报警或者报错,默认为1。
- 当选择定步长时,需要设置参数如下:(通常设置)

通常情况下,求解器必须采用固定步长,因为模型用于生成嵌入式代码并下载到硬件芯片中去实时执行,硬件芯片都是提供稳定频率的时钟源,无法提供变步长求解器的采样时刻计算方式,在模型没有连续状态,可选择discrete(离散)。固定步长应与内核中定时器的中断周期相一致,确保生成的代码在硬件芯片中以同样的时间间隔执行。
2. Hardware Implementation
推荐红框设置。

Hardware Implementation选项是规定目标硬件规格的选项。在这个选项卡中可以配置芯片的厂商和类型,设置芯片的字长、字节顺序等。
Hardware board:选择运行模型的硬件板
Code generation system target file:Code generation选择系统目标文件ert.tlc
设备供应商:选择用于实现此模型的硬件制造商
设备类型:选择用于实现此模型的硬件类型
硬件参数:默认值
3. Code Generation
推荐红框设置。

目标选择:整个界面中关键的设置选项是控制整个代码生成过程的系统文件目标。ert.tlc文件是Embedded Coder提供的能生成专门用于嵌入式系统C代码的系统目标文件。在代码生成页面中,点击浏览即可进入选择系统目标文件的设置其中包含多个架构类型的选项。如下图:

编译过程:此部分主要是针对于代码的设置与工具链设置。
①关于生成代码,是指生成代码相关的文件,然后一些编译的文件它会忽略掉,建议选只仅生成代码。若不勾选此选项会多生成一些文件,对代码本身没有影响,因此为了减少生成不必要的文件我们对其进行勾选。
②关于代码和工具打包,如果把这个选项勾上,它会把代码和一些生成的必要文件会打包成一个zip文件,这里可以写上压缩包的名字。目前是不需要打包的,所以这里就不用选了。
③关于工具链,默认即可。
代码生成目标:此部分主要是针对于代码生成目标设置,选择模型代码生成的最优先目标,通常情况不用设置,默认即可,但在此选择大多数汽车行业都要遵循的标准MISRA C:2012 规范。

生成代码检查模型:在代码生成前,查看模型是否运行且无异常,通常情况不用设置,默认即可,也可以根据实际情况选择。
3.1优化
推荐红框设置。

默认参数行为:该配置中包含两个选项可调和内联。如果选可调,参数通过其他文件调用的;如果选内联,会把参数“内联”到代码中,表现为直接的数值。
注意:两种情况对代码运行都不会出现影响,但是可调式会占用RAM资源,最终可能会导致资源溢出。
可重用子系统输出的传递方式:默认是 单个参数,指的是输出为局部变量。还有一个选项是结构体引用,会生成一个全局结构体变量,然后可复用子系统对应的函数会调用这个结构体的指针,当使用结构体引用时,会生成一个结构体的全局变量、同上文一样,会出现RAM资源紧张问题,推荐使用单个参数。
删除根级I/O零初始化:是设置在初始化子系统后所有的输入输出会不会默认为0。不勾选此项时,会生成接口默认值为0的代码,同理,这部分代码也会占用RAM资源,建议直接勾选此项。除了一种特殊的情况,如果控制器因为某种原因,复位后没有将RAM中的数值清零。这时候就需要这部分的初始化函数,默认即可。
删除内部数据零初始化:有些模块可能存在内部变量存储,以及默认存储值。若不勾选此项,这里会对模块内部的全局变量初始化为0,若勾选此项,这里就不会对模块内部的全局变量初始化为0,默认即可。
优化的级别:选择要应用于生成代码的优化级别,默认即可。
3.2报告
推荐红框设置。

创建代码生成报告:可以选择是否创建HTML格式的代码生成报告,推荐勾选。
自动打开报告:可以选择是否生成完代码后主动弹出报告,推荐勾选。
生成静态代码指标:生成一些静态代码指标,例如圈复杂度,最长路径等,默认即可。
3.3注释
推荐使用默认设置。

包括注释选项的勾选决定是否在代码生成中添加Simulink自带的注释,勾选此选项后,自动生成的注释以及自定义注释的选项便会被激活,可以根据实际情况选择希望生成的注释内容。
3.4标识符
推荐使用默认设置。

此页用于设置ert.tlc系统目标文件控制下的代码生成不变定义规则,如上图所示。这些符号包括数据变量和数据类型的定义、常用宏、子系统方法、模块的输出变量、局部临时变量及命名的最长字符数等。标示符的具体意义如下表所示:

通过上表中各种标示符的不同组合,即可规定生成代码中各部分(变量、常量、函数名、结构体及对象)的名称的生成规则。
3.5自定义代码
推荐使用默认设置。

主要用于添加用户自定义的或者编程模型时必须的源文件、头文件、文件夹或者文件库等。
3.6接口
推荐使用默认设置。

软件环境:提供 CPL(代码替换库)的选择,将Simulink模块与所对应目标语言的数学函数以及操作函数库挂接,以便从模型生成代码,Embedded Coder提供默认的CPL。
支持:每个选项代表一种嵌入式编码器对代码生成的支持功能,其中一些功能是需要Simulink提供的头文件来支持才能编译为目标文件的,这些头文件一部分储存在路径为ATAB/Broot/simulink/include的文件夹中,一部分是在模型生成diamante过程中自动发生成的(rt开头的头文件)。如下:

代码接口与数据交换接口:这里的参数组用来配置生成代码的接口及数据记录的方式,如无特殊要求建议使用默认配置。
3.7代码样式
推荐使用默认设置。

此页面提供了一些关于生成代码风格的选项,如:if else分支的完整性确保,if else与switch case语句的选用,生成括号的频度,是否保留函数声明中的extern关键字等。
3.8验证
推荐使用默认设置。

此页面主要是关于代码验证方式SIL与PIL的配置,是否使能代码中函数执行时间记录、代码覆盖度记录,以及是否创建用于SIL与PIL的模型等。
3.9模板
推荐使用默认设置,红框不勾选。

此页面内为嵌入式编码器提供了默认的代码生成模板。
ert_code_template.cgt:主要规定了代码段的顺序,包含了源文件从注释到变量再到函数体各种分段。代码段顺序如下:
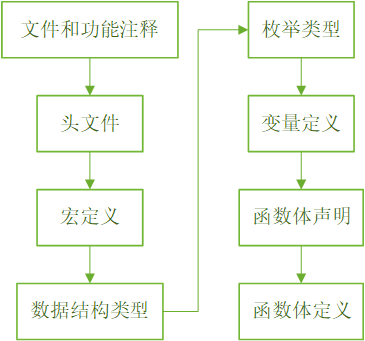
生成代码主程序:提供是否生成一个示例主函数的选项。若在项目的工程文件中,有定义工程的主函数,可以在代码生成的配置中取消main函数的生成,通常推荐不勾选。
3.10 代码布局
推荐使用默认设置。

此页提供的选项将影响代码生成的文件组织方式和数据存储方式及头文件包含的分隔符选择等,常用的选项是文件打包格式,便是生成文件的组织方式,对应生成文件的个数不同,内容紧凑度也不同,具体如下:

省去的只是文件的个数,但是内容被合并到其他文件中,具体内容如下:

推荐使用默认设置,如果希望生成代码文件列表中的文件减少,可以考虑其他设置。
3.11 数据类型替换
推荐使用默认设置。

二. 生成代码流程
在完成以上设置以后,就可以进行生成代码操作了。
①在APP选项中选择Embedded Coder功能卡,如下:

②选择以后进入Embedded Coder APP,点击Build按钮,生成嵌入式C代码。如下:

③显示代码且自动弹出报告,则生成代码完毕。


三. 代码文件简介
1. ert_main.c
该文件中会调用 “模型名称_step();”函数,用于单步执行,可以根据实际情况放在定时器中断或者任务调度里面执行该函数。除此之外,该文件中的main函数会初始化模型,调用“模型名称_initialize();”函数。该函数实际使用时也必须在模型执行前初始化。在实际使用时该文件不必添加进工程。
2. 模型名称_xxx.c
该文件是根据模型生成的代码,包含“模型名称_step();”函数,“模型名称_initialize();”函数,“模型名称_terminate(void);”函数。
3. 模型名称_xxx.h
该文件包含模型中的模块数据结构定义。
4. 模型名称_xxx_private.h
该文件包含模型中的私有变量,主要是声明的全局变量。
5. 模型名称_xxx_types.h
该文件包含模型中的结构体定义。
6. shared_files
该文件夹中的文件是一些乘除法的函数方法,需要添加至工程中。文件在./slprj/ert/_sharedutils目录中。
7. OtherFiles
该文件夹中是在自定义代码页中添加的源文件,需要添加至工程中进行编译。

四. 代码生成技巧
1. 通过信号关联,提高代码可读性
通过建立信号和参数的对象,对数据进行管理,然后右击信号线->属性,勾选关联信号对象,出现蓝色的叉子表示关联成功。
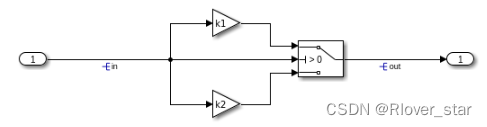
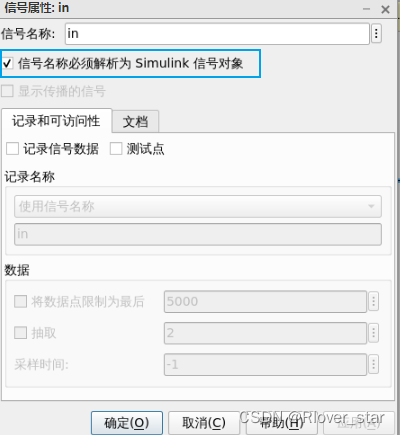
2. Simulink模块代码生成的接口优化
默认ert.tlc作用下生成的接入点函数有2个:xxx_initialize()和xxx_step(),xxx_initialize()将在xxx_step()函数运行之前调用一次对模型进行初始化,xxx_step()函数将在每个rt_Onestep中被周期性调用(需要绑定到目标硬件上实现)。其实xxx_step()函数内部包含2个子函数xxx_update()和xxx_output(),分别用于计算模型中的离散状态变量及模型的输出,通过勾选单一输出/更新函数选项可以分开生成。

注意: (1)通过勾选需要终止函数,可以生成xxx_terminate()函数。
(2)经典调用接口默认不勾选,生成的代码层次较少,执行效率较高;若勾选此选项,模型生成的代码将按照C MEX S函数的各个子方法组织,得到非常复杂的处理机制。
(3) 组合信号/状态结构体默认不勾选,模型的信号和状态,二者相辅相成,信号作为模型输入/输出和连接的桥梁,状态则为模型不同时刻的数据缓冲提供支持。默认情况下它们会分别生成到各自的结构体中,如果勾选了此项,那么生成代码时模型中的信号变量和状态变量会结合在一个结构体变量中。
3. 通过原子系统优化重复的功能模块
(1)首先,我们需要建立一个原子子系统,选中第一个功能模块,鼠标右键,选择创建子系统。

(2)接下来选中所创建的子系统,鼠标右键,然后选择模块参数(Subsy-
stem)。

(3)在弹出的对话框中进行如下设置。函数打包是必须进行设置的,如果是默认状态,生成的代码将不会改变。函数名可以设置也可以不设置,不设置系统将自动分配一个名字,基本是:模型名_Subsystem。建议设置函数名,函数名应该能尽量表示该函数所实现的功能。


(4)另一个模块也按照上述方式进行设置,或将设置好的模块复制一份,完成后如图所示。

(5)生成代码,可以看到生成了一个名为MySelfFunction函数,且该函数被调用了两次。















 4772
4772

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









