








论文链接:https://arxiv.org/pdf/2101.07448.pdf.
arxiv 2021
文章目录
1 Background
最近提出的DETR
(detection transformer)通过去掉手工anchor和NMS操作很大程度上简化了目标检测的流程,但是DETR的收敛速度很慢,这增加了算法的设计周期,使得算法很难扩展,限制了它的广泛用途。

接下来回顾一下为了加快DETR的收敛,都有哪些改进的方法:
(1)Deformable DETR:Deformable DETRDeformable DETR将DETR中的attention替换成Deformable attention,只关注参考点周围的一小部分关键点采样,为每个query分配少量固定数量的key,可以缓解收敛性和输入分辨率受限制的问题

(2)TSP:TSP(Rethinking Transformer-based Set Prediction for Object Detection)通过去掉decoder,将FCOS/R-CNN和DETR组合,来加快DETR的收敛速度

(3)Sparse-RCNN:Sparse-RCNN虽然结构上跟DETR没有关系,但是思想上是通过将粗粒度的目标区域扣出来来加快收敛速度

为了增加收敛速度,本文提出了Spatially Modulated Co-attention (SMCA)模块,它是一个即用即插的模块。
2 Motivation
为了加速DETR收敛,本文通过动态预测一个2D的空间高斯weight map,来跟co-attention feature maps相乘来达到加快收敛速度的目的。即插即用,让DETR涨点明显。性能优于可变形DETR、DETR等网络。

其中,Co-attention的概念可以理解为下面红色框的部分,即Q和K、V来自于不同的地方。

3 Related Work
- Object Detection:
- two-stage:eg,RCNN , Fast RCNN ,Faster RCNN
- one-stage:eg,YOLO ,SSD
- end-to-end:无需NMS操作。eg,DETR ,Deformable DETR,TSP
- Transformer:
- CNN和LSTM都可以对序列数据进行建模,Transformer是一种新的序列数据建模架构,在机器翻译、模型预训练、视觉识别等方面都有应用。它处理较长的序列比较难,许多方法被提出来解决这个问题, : eg,Reformer ,Linformer , Longformer
- Dynamic Modulation:
- Attention机制可以看作是动态调制的变体。 eg,Look-Attend-Tell , Dynamic filter , SE-Net
4 Advantages/Contributions
本文提出的Spatial Modulated Co-Attention(SMCA) 通过动态预测一个2D的空间高斯weight map,来跟co-attention feature maps相乘来达到加快收敛速度的目的;同时SMCA通过整合multi-scale features 和 multi-head spatial modulation 来提升检测性能;并在COCO 2017数据集上进行了消融研究
5 Method

整体思路就是先在Decoder部分进行空间调制协同注意力(SMCA,橙色部分)来加快收敛,同时发现高斯权重图G不共享(即每个头一个G,文中称为多头)可以提升性能,为了进一步提升性能,在encoder部分提出了多尺度(蓝色和绿色部分),然后又发现Q对不同的尺度需求不同,因此又在decoder部分加入了scale选择网络(文中黄色部分)。
5.1. A Revisit of DETR

- encoder:

H表示Mutli-Head self-attention有H个头,每个头是按上边那个d的通道数来划分的,比如有8个头,H==8,d=16,那么每个头是d×HW
- decoder:
-
FC表示线性转换
5.2. Spatially Modulated Co-Attention
1)Dynamic spatial weight maps(橙色部分)

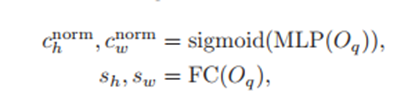
根据上边公式,首先N个queris分别预测中心点坐标和scale(两个公式都可以用图中蓝色部分表示)
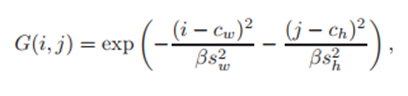
得到坐标个scale之后,根据高斯公式预测出2D高斯权重图,就是上图中的Spatial Prior
2)Spatially-modulated co-attention
然后进行空间调制协同,橙色部分
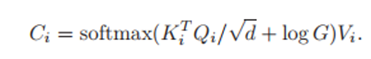
公式就是在DETR的encoder部分的公式上添加上了G(2D高斯权重图),论文中的意思是按元素相乘,这里公式应该是错了,加号应该改为乘号。
3)SMCA with multi-head modulation
这里多头的意思就是橙色部分多个头不共享2D高斯权重图(G),每个头一个G,总共N个G,成为多头。
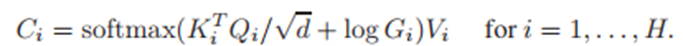
每个头的G是在第一个算出来的G的基础上来算的,即是在第一个G的中心点坐标和Scale的基础上学出自己的中心点和Scale的偏移量来得到自己的C和S
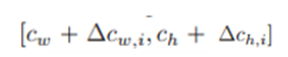
4)SMCA with multi-scale visual features

- Intra-Scale:是指在f16、f32、f64三个平面内,每个平面中的每个位置只和自己平面的其它位置进行self-attention
- Mutli-Scale:指每个平面位置与所有平面进行self-attention
此外,we notice that some queries might only require information from a specific scale but not always from all the scales ,因此
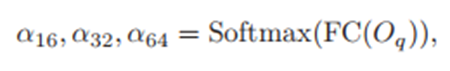
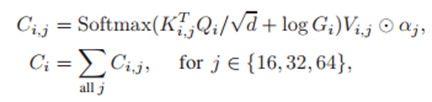
6 Experiments
6.1.Datasets
- COCO 2017
6.2.Comparison with DETR

6.3. Ablation Study
1)The baseline DETR model

2)Head-shared spatially modulated co-attention

3)Multi-head vs. head-shared spatially modulated co-attention

4)Design of multi-head spatial modulation for co-attention

- indep 指的是 G 的三层(不同 scale)计算 h 和 w 时候, FC 不一样,FC1 / FC2/ FC3
- single 指的是 G 的三层(不同 scale)计算 h 和 w 时候, FC 一样
- fixed 指的是 h 和 w 固定,不是学出来的,论文中设置为了 1
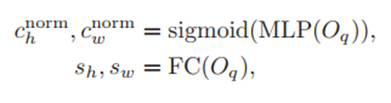
5)Multi-scale feature encoding and scale-selection attention

6)Visualization of SMCA

6.4. Overall Performance Comparison

7 Conclusions
- SMCA与Deformable DETR的不同:(1)SMCA仅仅替换了DETR的decoder的co-attention部分 , Deformable DETR使用 deformable attention 替换了DETR的encoder和decoder两部分(2) Deformable DETR探索的是local信息,SMCA探索的是global信息
- SMCA跟Sparse R-CNN的联系:某种意义上来讲,SMCA和Sparse R-CNN的关系类似于CNN范式中FCOS和Faster-RCNN的关系,一个直接在global的feature上加先验,来达到快速收敛的目的,一个通过ROIAilgn的方式将目标feature扣出来来达到快速收敛的目的。本质上就是拿更好的目标位置先验,帮助定位目标,提取目标context的信息。














 1511
1511











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









