







大型语言模型 (LLM) 的兴起一直是自然语言处理 (NLP) 领域的一个决定性趋势,导致它们在各种应用程序中的广泛采用。然而,这种进步往往是排他性的,大多数由资源丰富的组织开发的 LLM 仍然无法向公众开放。
这种排他性提出了一个重要的问题:如果有一种方法可以使对这些强大的语言模型的访问民主化,那会怎样?这就是 BLOOM 出现的原因。
本文首先提供了有关其起源的更多详细信息,从而全面概述了 BLOOM 是什么。然后,它介绍了 BLOOM 的技术规范以及如何使用它,然后强调了它的局限性和道德考虑。
什么是BLOOM?
BigScience 大型开放科学开放获取多语言模型(简称 BLOOM)代表了语言模型技术民主化的重大进步。
BLOOM由来自39个国家的1200多名参与者共同开发,是全球努力的产物。该项目由 BigScience 与 Hugging Face 和法国 NLP 社区合作协调,超越了地理和机构的界限。
它是一个开源的、仅解码器的转换器模型,具有 176B 参数,在 ROOTS 语料库上训练,该语料库是 59 种语言的数百个来源的数据集:46 种口语和 13 种编程语言。
下面是训练语言分布的饼图。
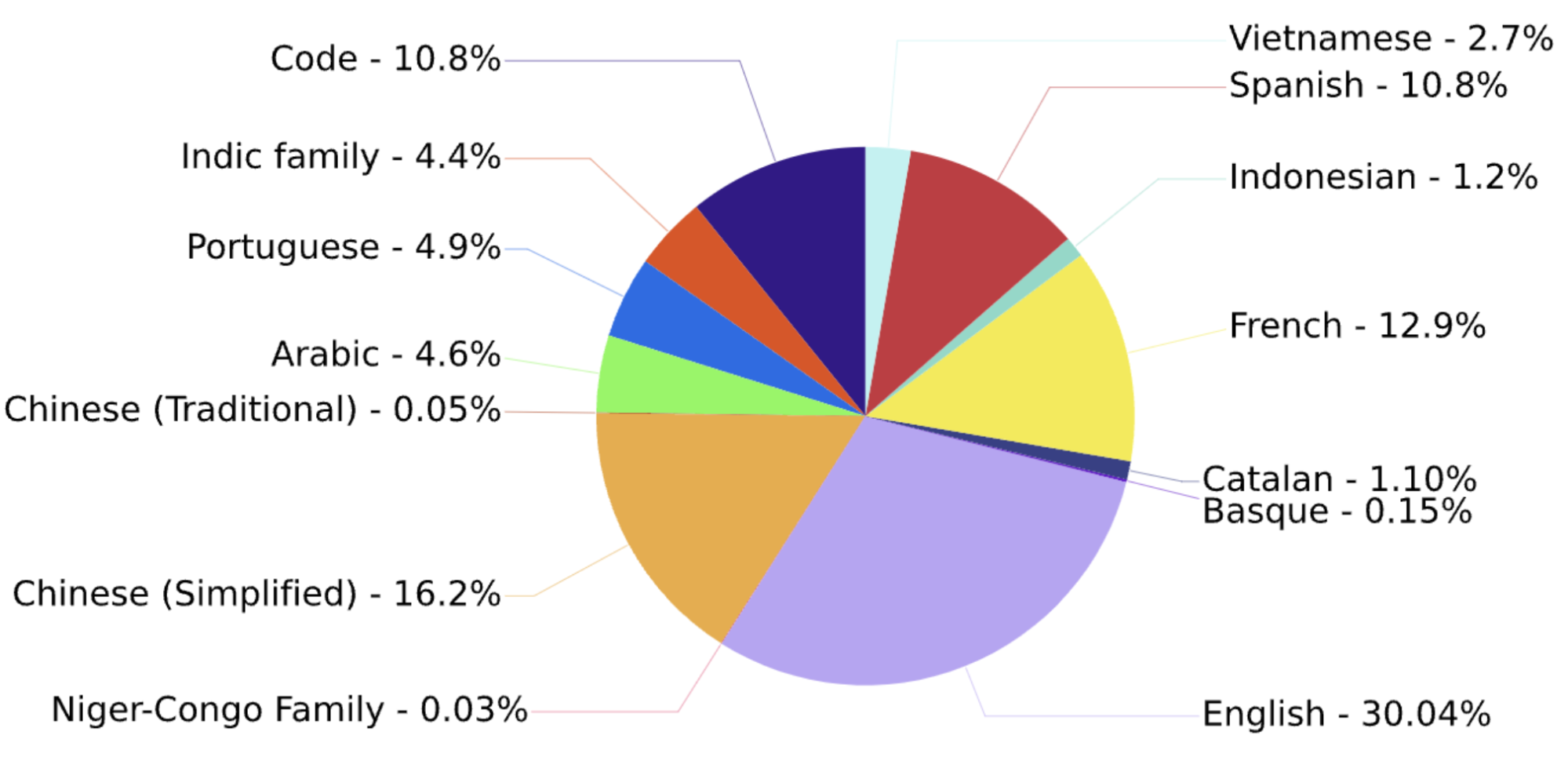
训练语言的分布
该模型被发现在各种基准测试中都取得了显着的性能,并且在多任务提示微调后获得了更好的结果。
该项目在巴黎的Jean Zay超级计算机上进行了为期117天(3月11日至7月6日)的培训课程,并得到了法国研究机构CNRS和GENCI的大量计算资助。
BLOOM不仅是一个技术奇迹,也是国际合作和集体科学追求力量的象征。
BLOOM 模型架构
现在,让我们更详细地描述一下 BLOOM 的架构,它涉及多个组件。
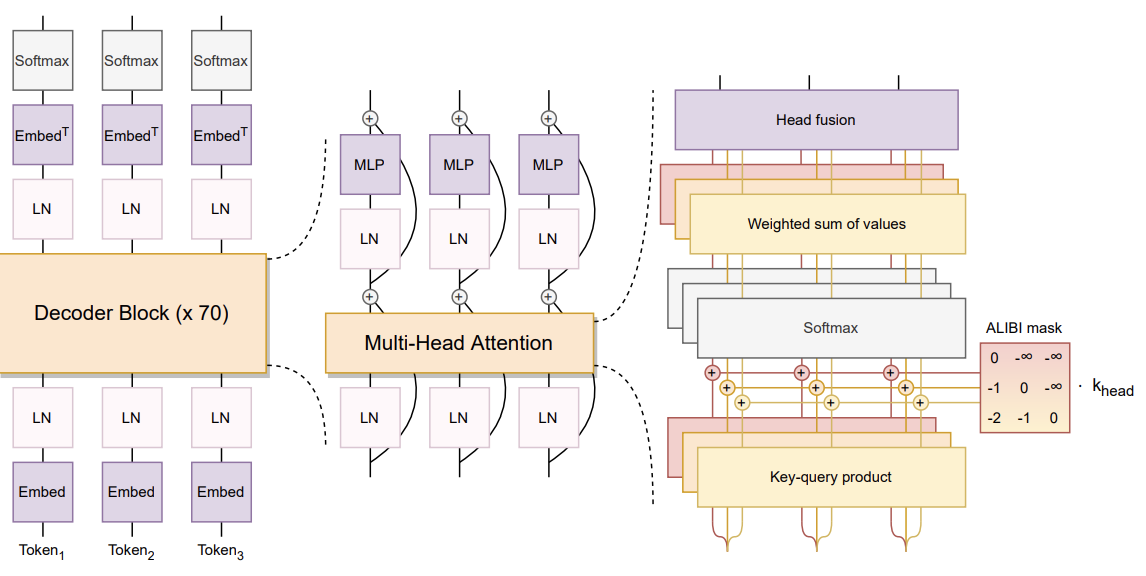
Bloom 架构
如本文所述,BLOOM 模型的架构包括几个值得注意的方面:
- 设计方法: 该团队专注于支持公开可用工具和代码库的可扩展模型系列,并在较小的模型上进行了消融实验,以优化组件和超参数。零样本泛化是评估架构决策的关键指标。
- 架构和预训练目标:BLOOM 基于 Transformer 架构,特别是仅因果解码器模型。与编码器-解码器和其他仅解码器架构相比,这种方法被验证为零样本泛化功能最有效的方法。
- 建模细节:
- ALiBi 位置嵌入:ALiBi 之所以选择传统的位置嵌入,是因为它根据按键和查询之间的距离直接削弱注意力分数。这导致了更顺畅的训练和更好的表现。
- 嵌入 LayerNorm: 在嵌入层之后立即包含额外的层归一化,这提高了训练稳定性。这一决定在一定程度上受到在最终训练中使用 bfloat16 的影响,它比 float16 更稳定。
这些组件反映了团队专注于平
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1800
1800

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









