






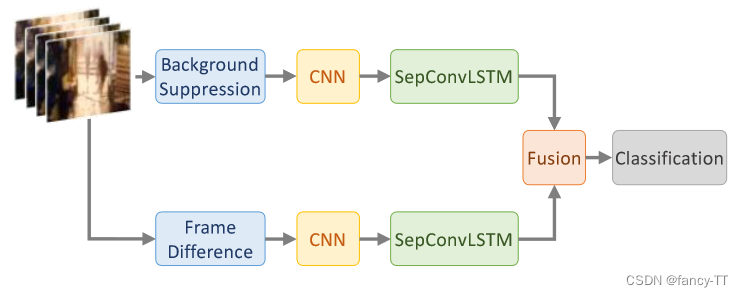
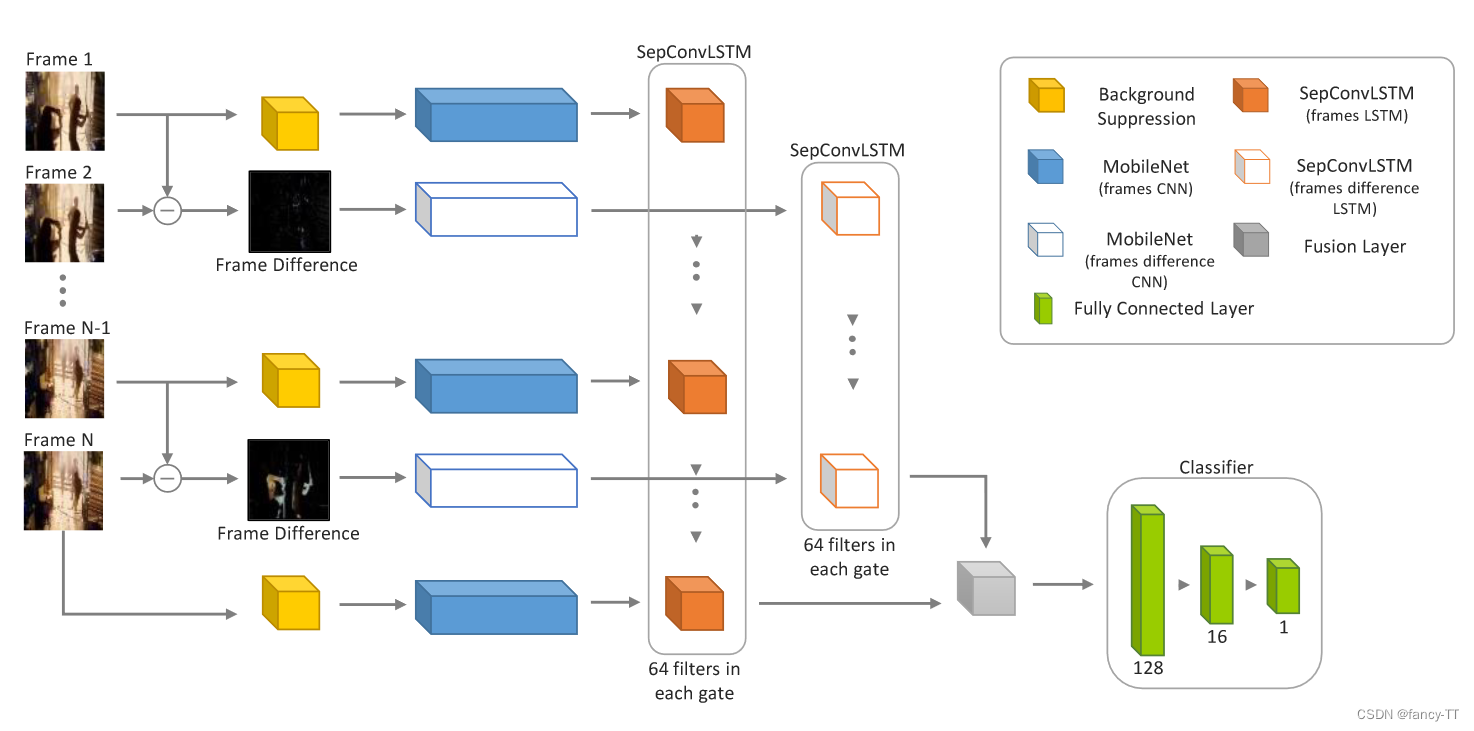
1. Conv + LSTM:Efficient Two-Stream Network for Violence Detection Using Separable Convolutional LSTM:
相邻两帧图像会做一个相减操作,
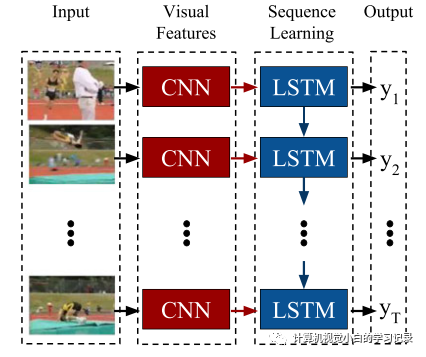
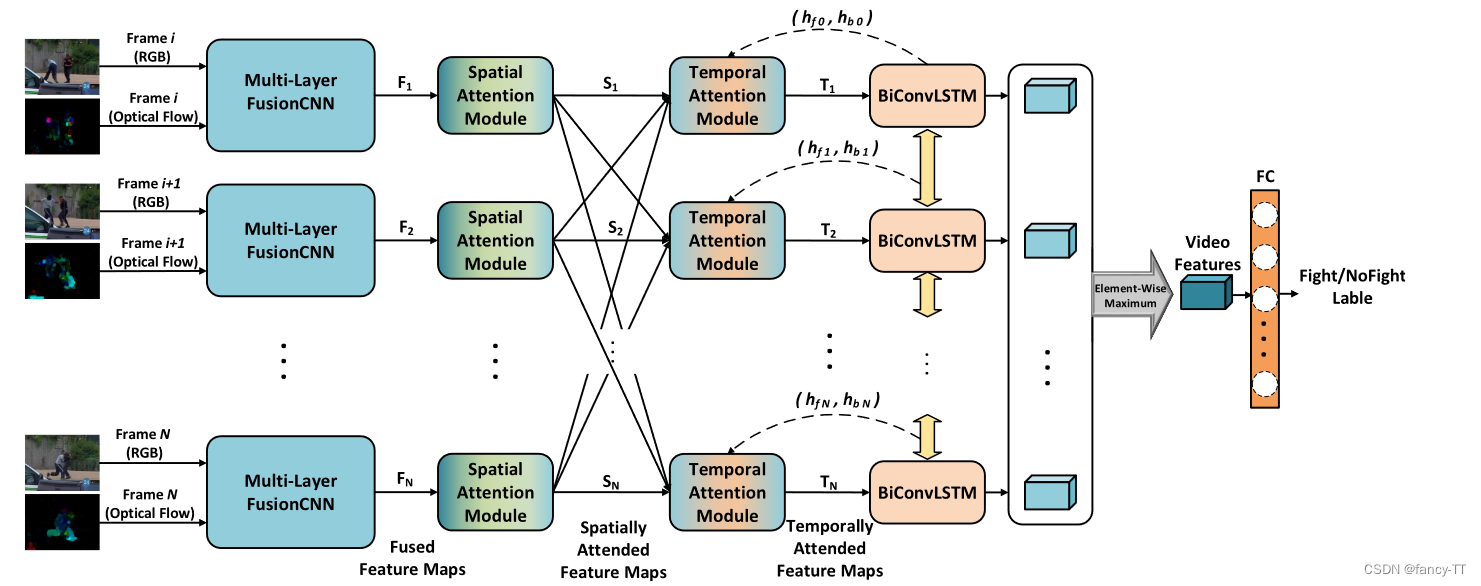
2.两种图像融合技术: Multi-Level Two-Stream Fusion-Based Spatio-Temporal Attention Model for Violence Detection and Localization。
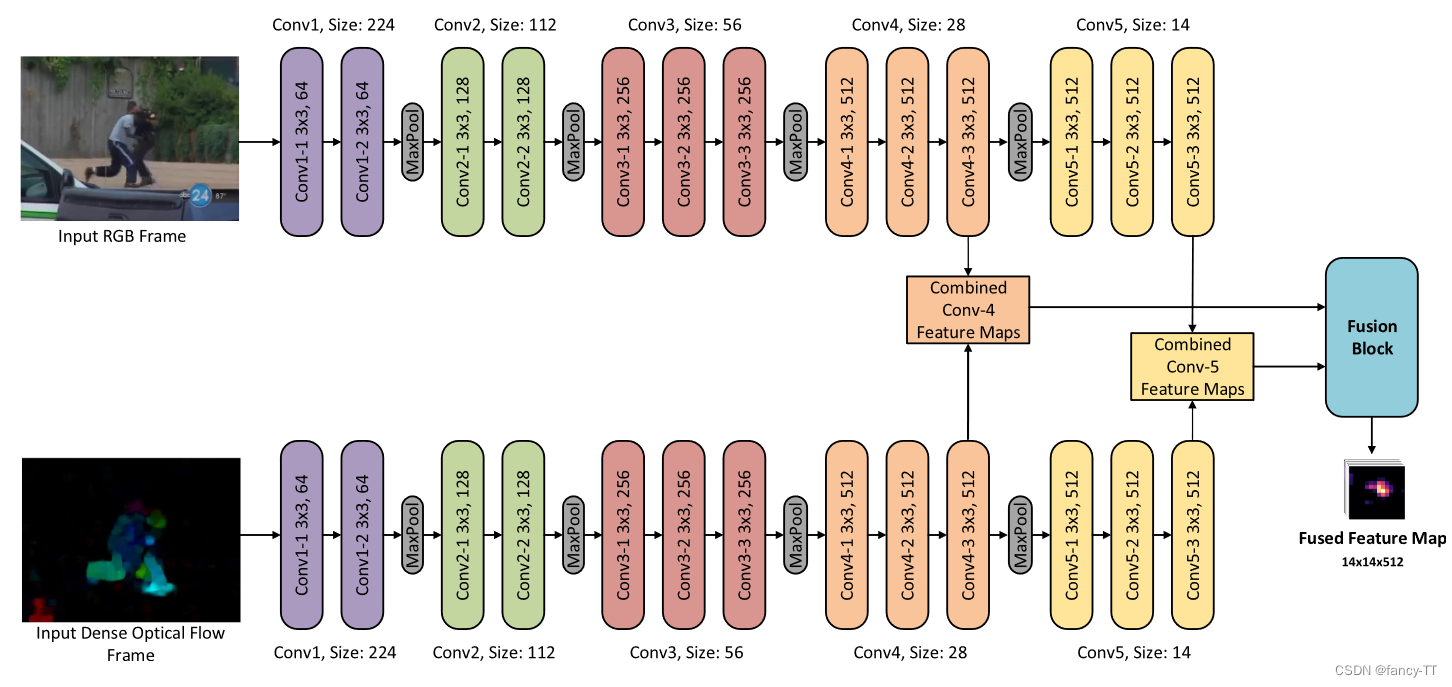
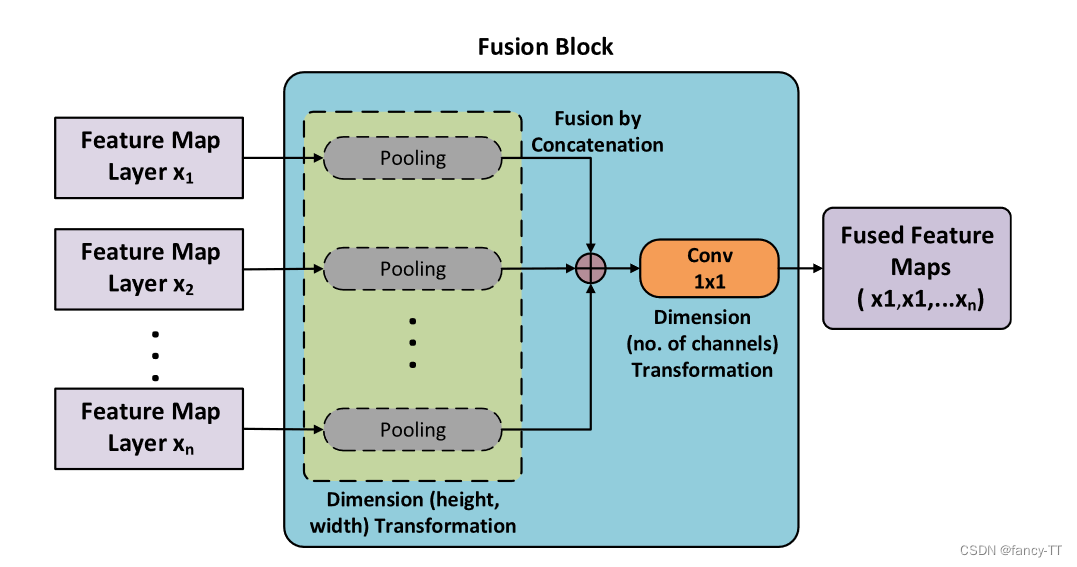
3. 人体关键节点检测:个人感觉不太适用于无人机图像,
4. 引入transformer结构:TPH-YOLOv5: Improved YOLOv5 Based on Transformer Prediction Head for Object Detection on Drone-captured Scenarios
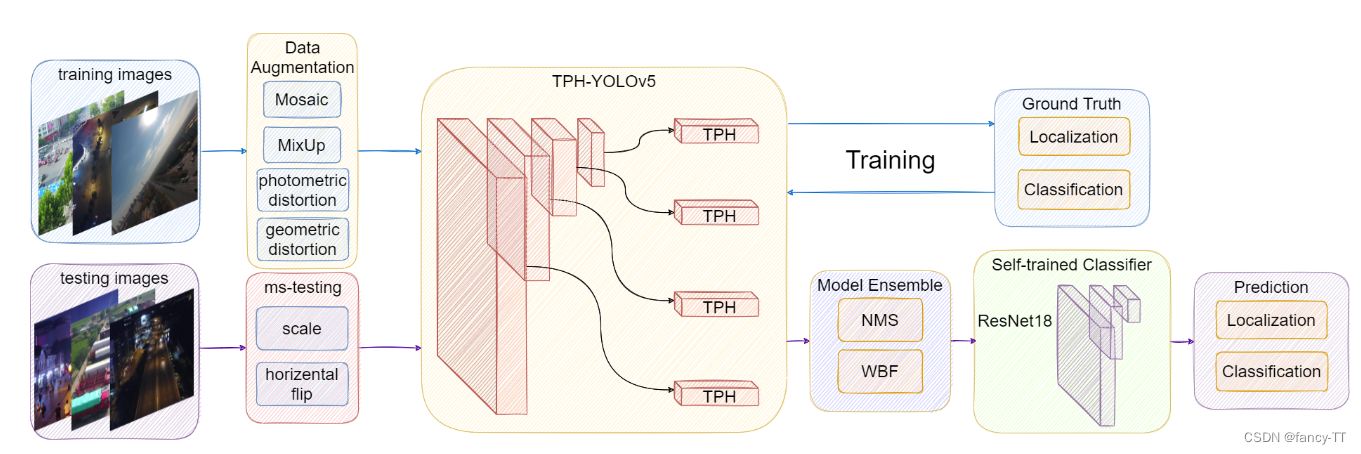
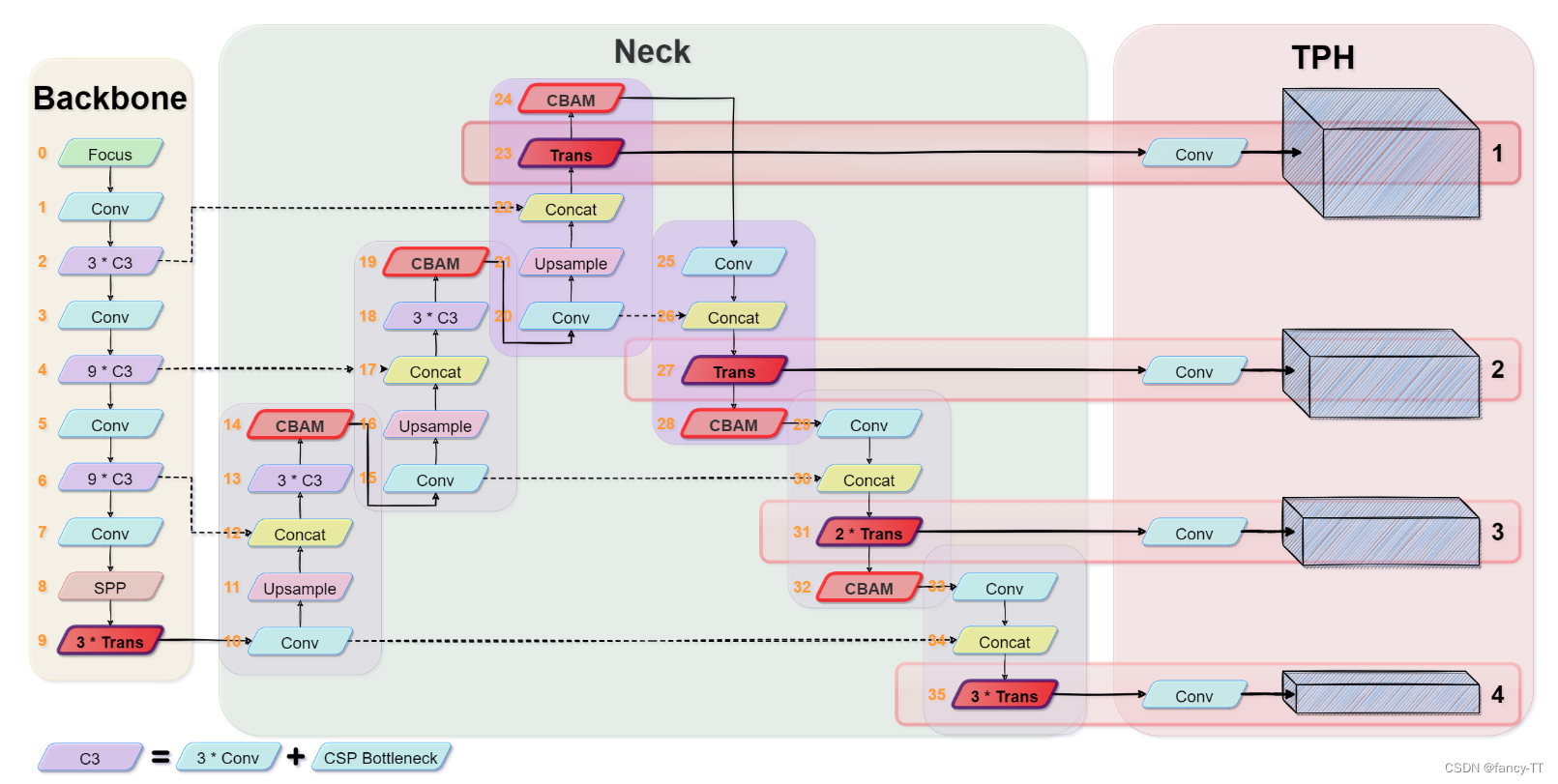
References:
[1] M. Liu, X. Li, J. Dezert and C. Luo, "Generic object recognition based on the fusion of 2D and 3D SIFT descriptors," 2015 18th International Conference on Information Fusion (Fusion), Washington, DC, USA, 2015, pp. 1085-1092.


















 9181
9181

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











