







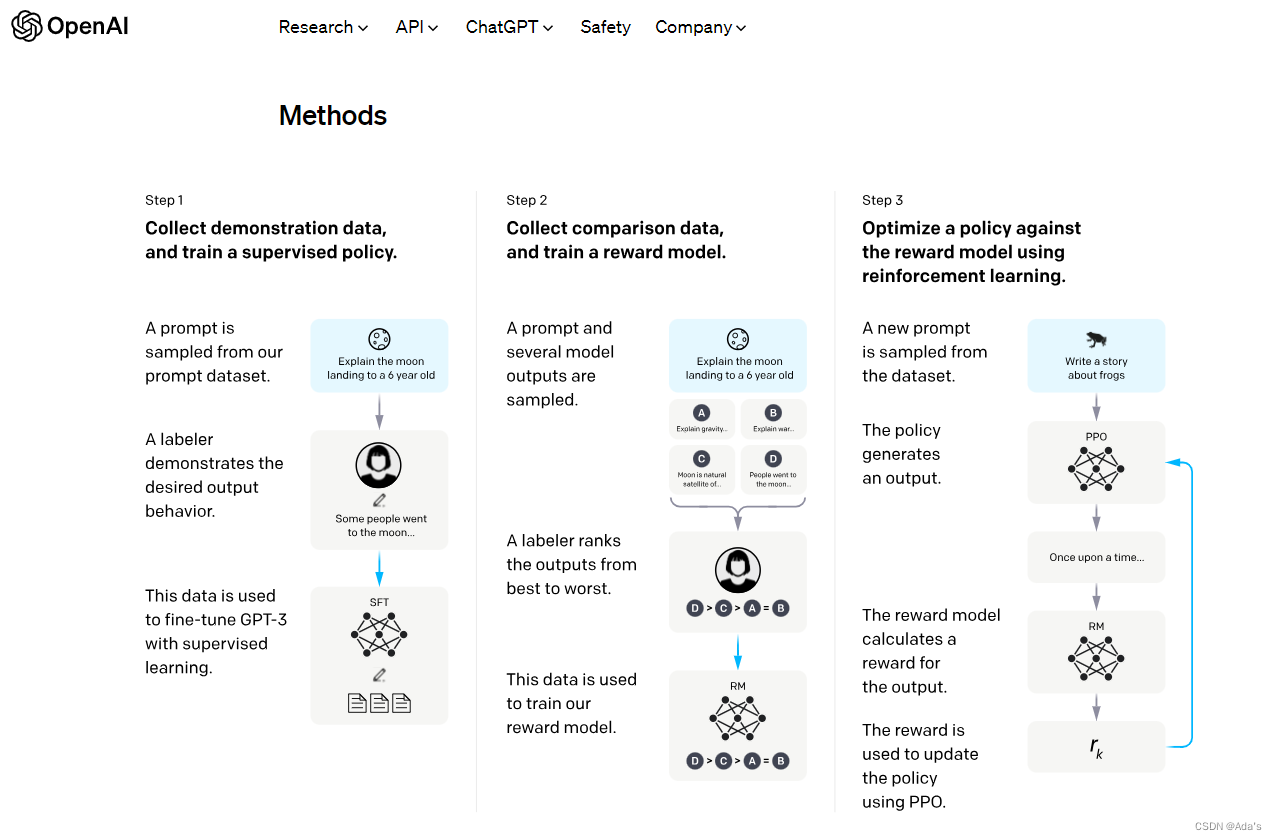
AttentionRNN(2014年)
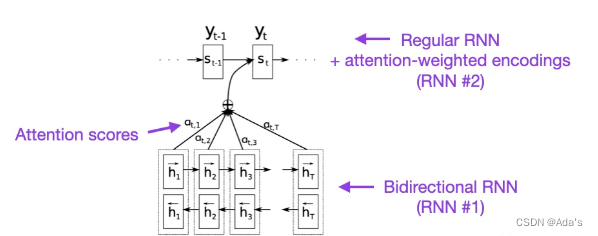
十年前,上面的这篇文章算是为自然语言领域的RNN和Attention奠定了基础,BiRNN1997年,RNN encoder-decoder2014年分别为该论文奠定了基础,在这篇论文中详细阐述了通过软注意力解决对齐问题,也就是硬注意力和软注意力的一个区别,主要作用在隐含层得分问题上的基础研究。大佬之所以是大佬是能对一个现象级问题进行抽象并建模分析,同时先通过定性后定量实现系统性研究,下图是当时大佬们在这项研究中的核心工作。

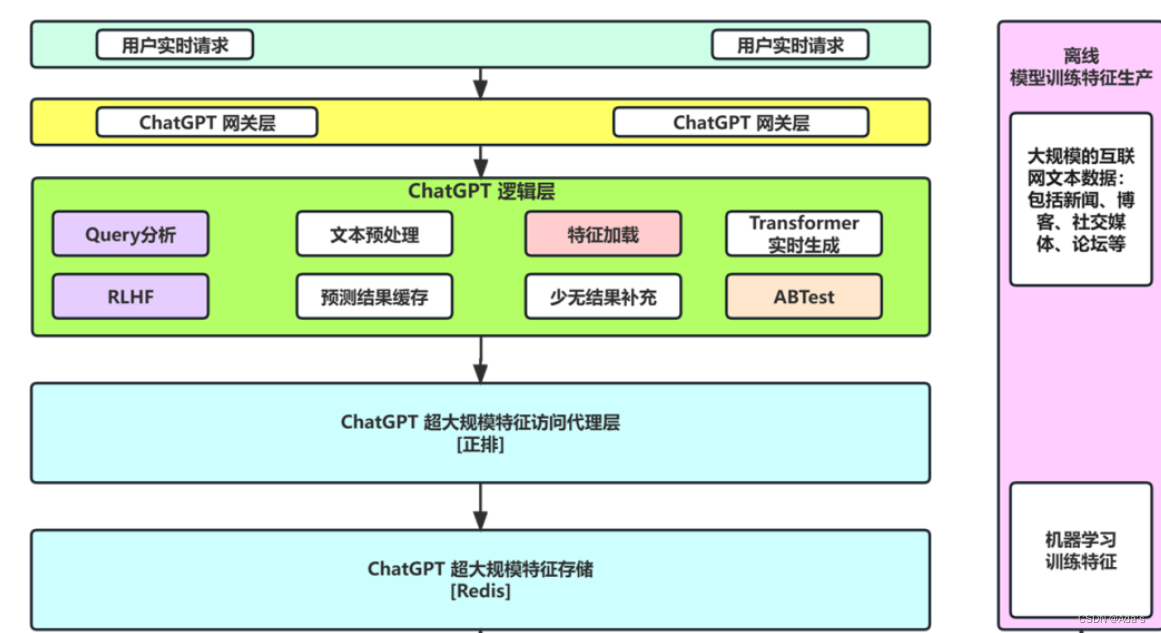
seq2seq(2014)
同样在自然语言处理领域,2014年谷歌提出了seq2seq这种序列化编解码结构,该结构在翻译领域开始迅速爆火。2015年attention正式被提出后,2017年seq2seq+attention进入融合阶段。在该阶段主要工作是通过编码输入序列获取语义信息的编码向量,在解码阶段通过解码得到输出序列,这种阶段还无法解决语义多维空间问题直到embedding方法出现才彻底解决。它的强大是输入和输出可以不一样,融合结果展示如下图。


Transformer(2017)
这篇论文出现,再次证明了大佬们的操作就是朴实无华,大道至简。一个好论文必先有个好名字,当时出现了一堆xxx is all u need。而这篇文章我个人理解最大贡献是通过编解码器思路用多头注意力实现位置时序信息和语义信息同时编码。这样输入的token不仅和它前后位置的内容相关同时关联了整个输入token内容语义,具体实现如下图。

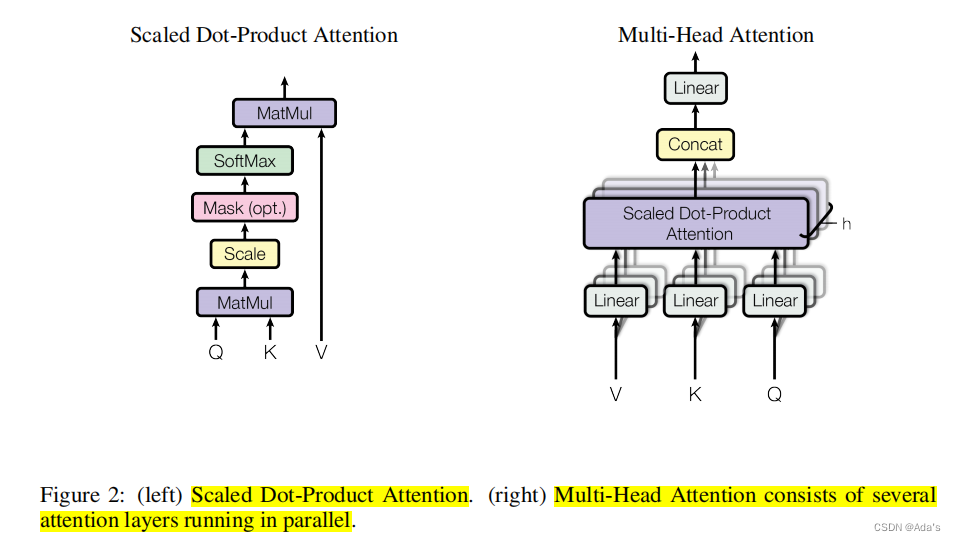
经过我读论文发现它的基线模型应该是ByteNet和ConvS2S。老外写东西就是这么坦率!

BERT
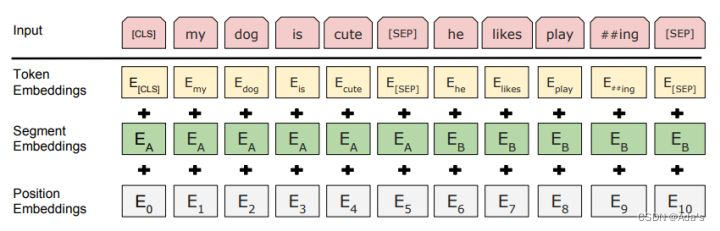
BERT的输入的编码向量(d_model=512)是3个嵌入特征的单位和,这三个词嵌入特征是:
WordPiece 嵌入[Google’s neural machine translation system: Bridging the gap between human and machine translation. ]:WordPiece是指将单词划分成一组有限的公共子词单元,能在单词的有效性和字符的灵活性之间取得一个折中的平衡。例如示例中‘playing’被拆分成了‘play’和‘ing’。
位置嵌入(Position Embedding):位置嵌入是指将单词的位置信息编码成特征向量,位置嵌入是向模型中引入单词位置关系的至关重要的一环。Note: BERT的位置编码是学习出来的,Transformer是通过正弦函数生成的。BERT中使用的是学习位置嵌入(learned position embedding),是绝对位置的参数式编码,且和相应位置上的词向量进行相加而不是拼接。
分割嵌入(Segment Embedding):用于区分两个句子,例如B是否是A的下文(对话场景,问答场景等)。对于句子对,第一个句子的特征值是0,第二个句子的特征值是1。(lz:/segment_ids/token_type_ids。如果不使用,可以全默认为0)。
1 图中的两个特殊符号[CLS]和[SEP],其中[CLS]表示该特征用于分类模型,对非分类模型,该符合可以省去。[SEP]表示分句符号,用于断开输入语料中的两个句子。
2 语料的选取很关键,要选用document-level的而不是sentence-level的,这样可以具备抽象连续长序列特征的能力。
为什么BERT在第一句前会加一个[CLS]标志?
BERT在第一句前会加一个[CLS]标志,最后一层该位对应向量可以作为整句话的语义表示,从而用于下游的分类任务等。
为什么选它呢,因为与文本中已有的其它词相比,这个无明显语义信息的符号会更“公平”地融合文本中各个词的语义信息,从而更好的表示整句话的语义。
当然,也可以通过对最后一层所有词的embedding做pooling去表征句子语义。
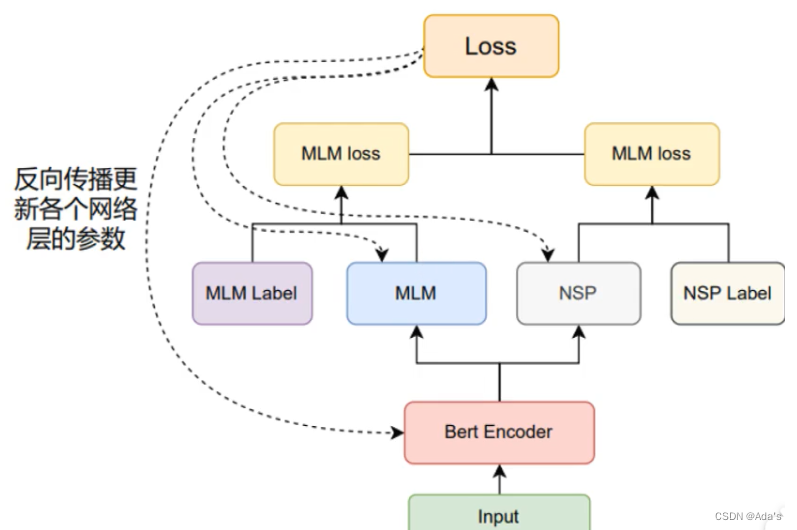
[为什么BERT在第一句前会加一个[CLS]标志?],解决Masked Language Model/完形填空(Cloze task),Next Sentence Prediction
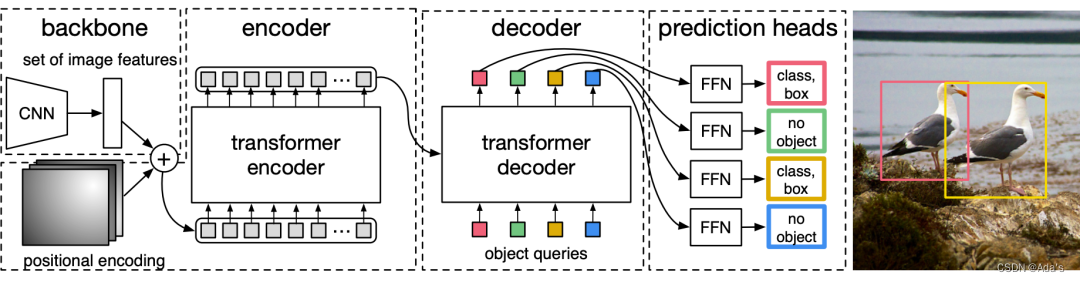
DERT
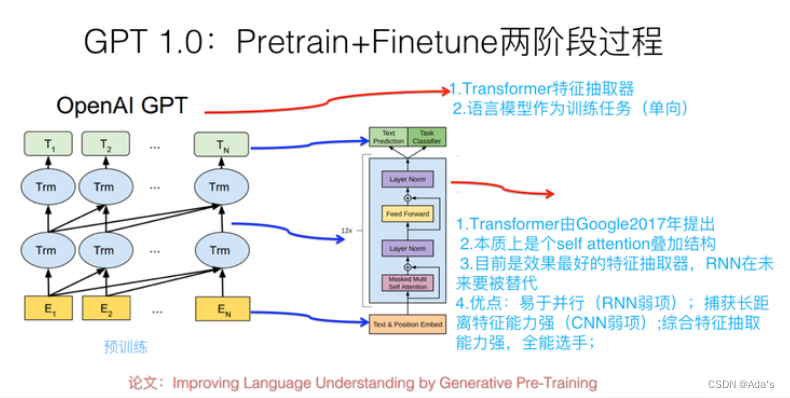
GPT

GLM

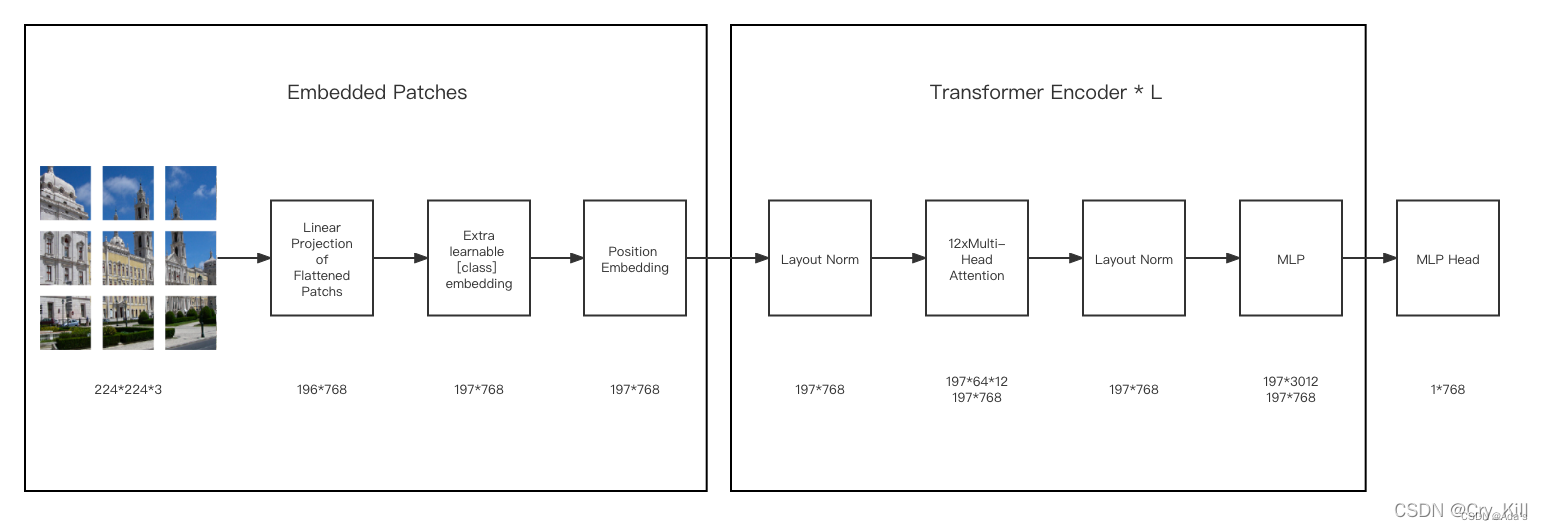
ViT

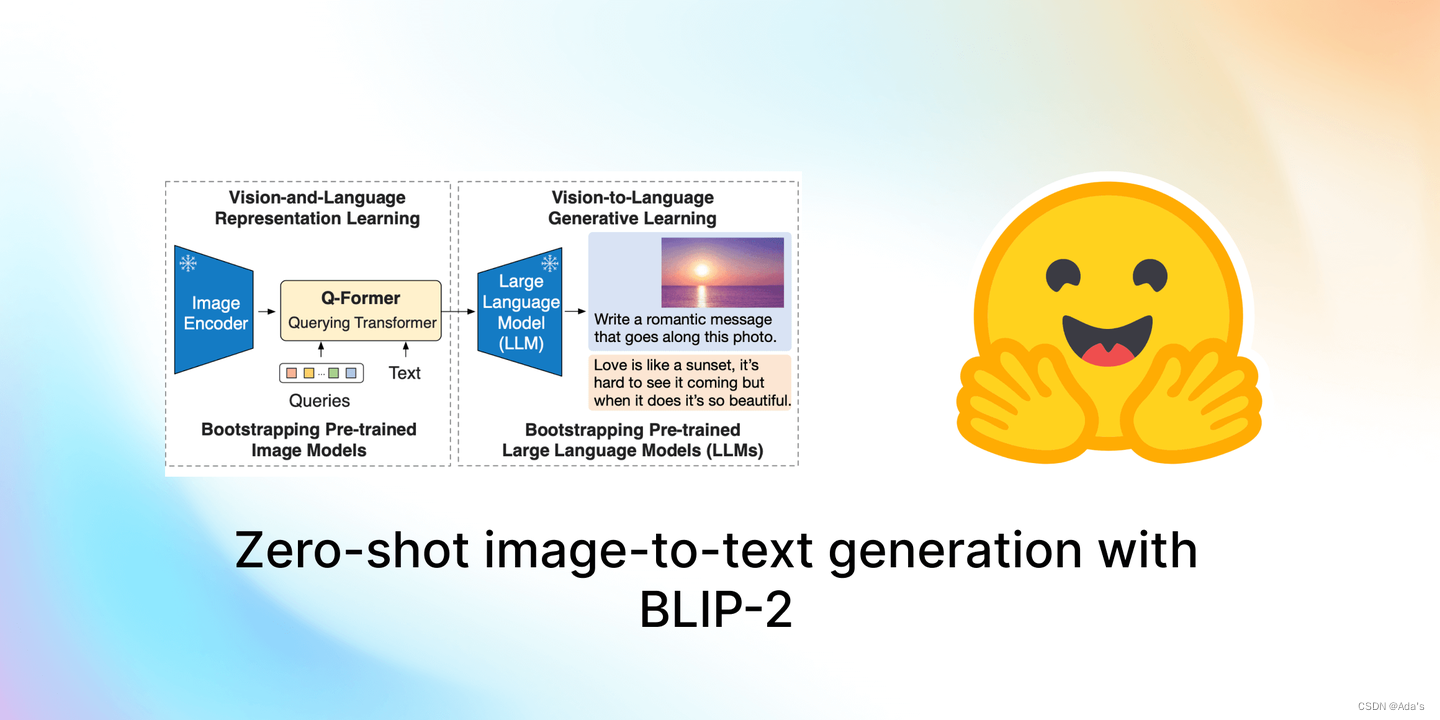
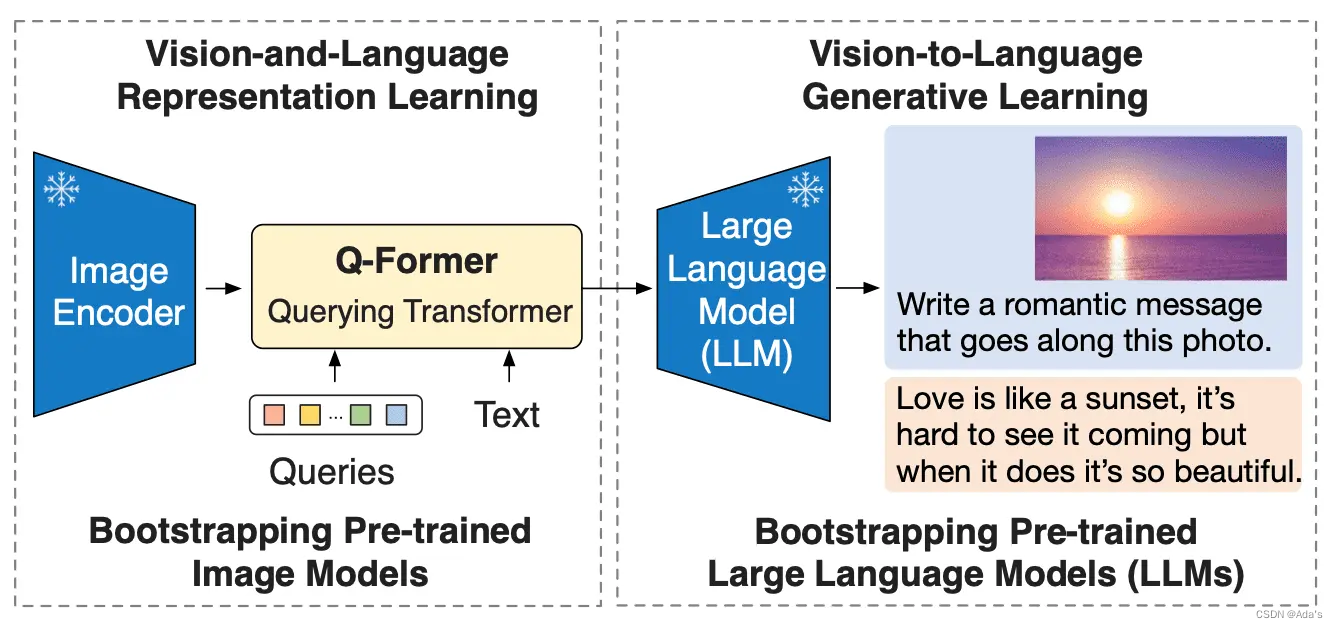
CLIP & BLIP

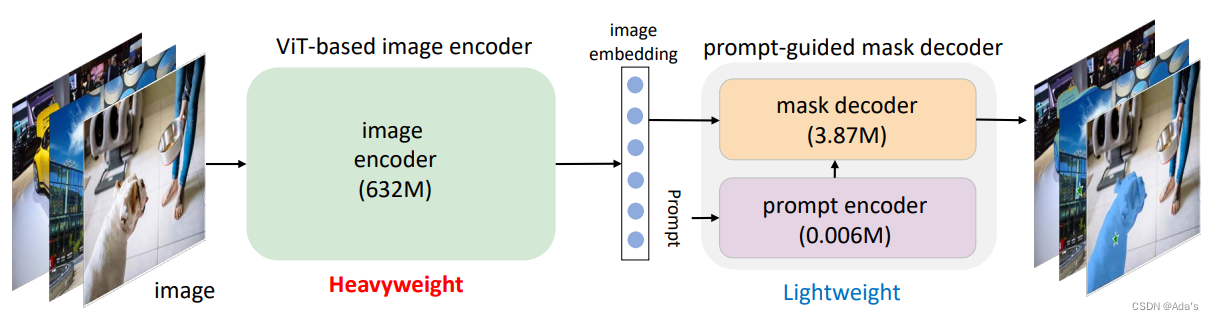
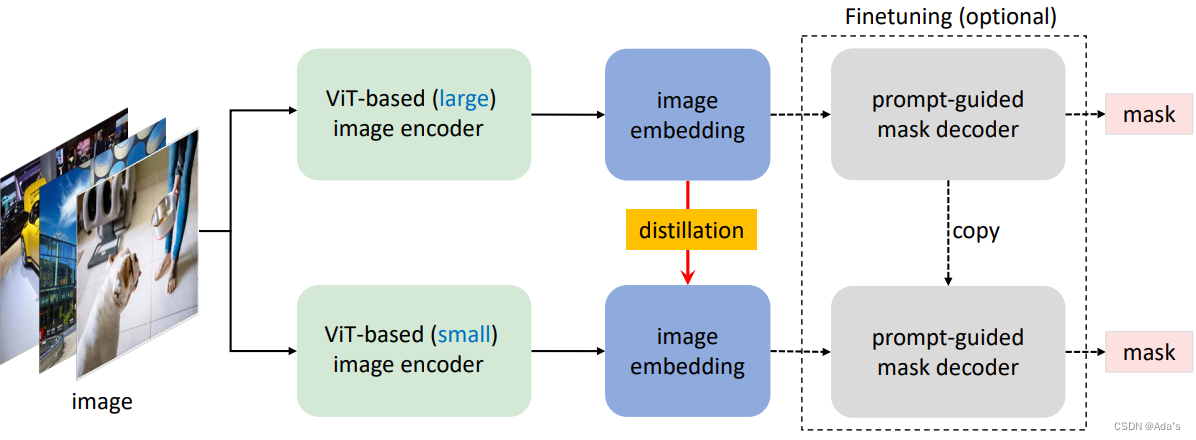
SAM

















 6864
6864











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









