









UniFormer & UniFormerV2 论文笔记
Author: Sijin Yu
文章目录
1. Information
- Uniformer
标题: UniFormer: Unified Transformer for Efficient Spatiotemporal Representation Learning
arXiv URL: https://arxiv.org/abs/2201.04676
code: https://github.com/Sense-X/UniFormer
期刊/会议: ICLR2022
发表时间: 2022 年 01 月
- UniformerV2
标题: UniFormerV2: Spatiotemporal Learning by Arming Image ViTs with Video UniFormer
arXiv URL: https://arxiv.org/abs/2211.09552
code: https://github.com/OpenGVLab/UniFormerV2
期刊/会议: ICCV2023
发表时间: 2022 年 11 月
2. Abstract (UniFormer)
-
在高维的视频中学习丰富的时空特征表示具有挑战性, 因为在视频的每帧之间, 存在大量的局部冗余和复杂的全局冗余.
-
关于此, 最近的主流框架有: 3D CNNs 和 ViTs.
-
3D CNNs 可以高效地整合局部内容, 以降低局部冗余, 但是因为其感受野有限, 无法降低全局冗余.
-
ViTs 可以通过自注意力机制降低全局冗余, 但是因为其盲目地比较所有 tokens, 无法降低局部冗余.
-
我们提出一种新式框架 Unified transFormer (UniFormer), 集成了 CNN 和 ViT 的优点, 并且在计算消耗和正确率之间取得了很好的平衡.
-
与传统的 transfomers 不同, 通过在浅层和深层分别学习局部和全局 token affinity [⚠️注: token affinity (词单元亲和力) 度量了两个 token 之间的关联性], 我们的 relation aggregator (关系聚合器) 可以同时处理时空冗余和依赖关系.
-
我们在主要的 video benchmarks 上做了实验. 在只用 ImageNet-1k 预训练的情况下, UniFormer 在 Kinetics-400 上获得了 82.9% 的准确率, 在 Kinetics-600 上获得了 84.8% 的准确率, 同时需要的 GELOPs 比其它 sota 模型少了 10 倍 [⚠️注: GELOP 指每秒十亿次浮点运算]. UniFormer 在 Something-Something V1 上获得了 60.9% 的正确率, 在 Something-Something V2 上获得了 71.2% 的正确率.
3. Methods (UniFormer)
3.1 Overview
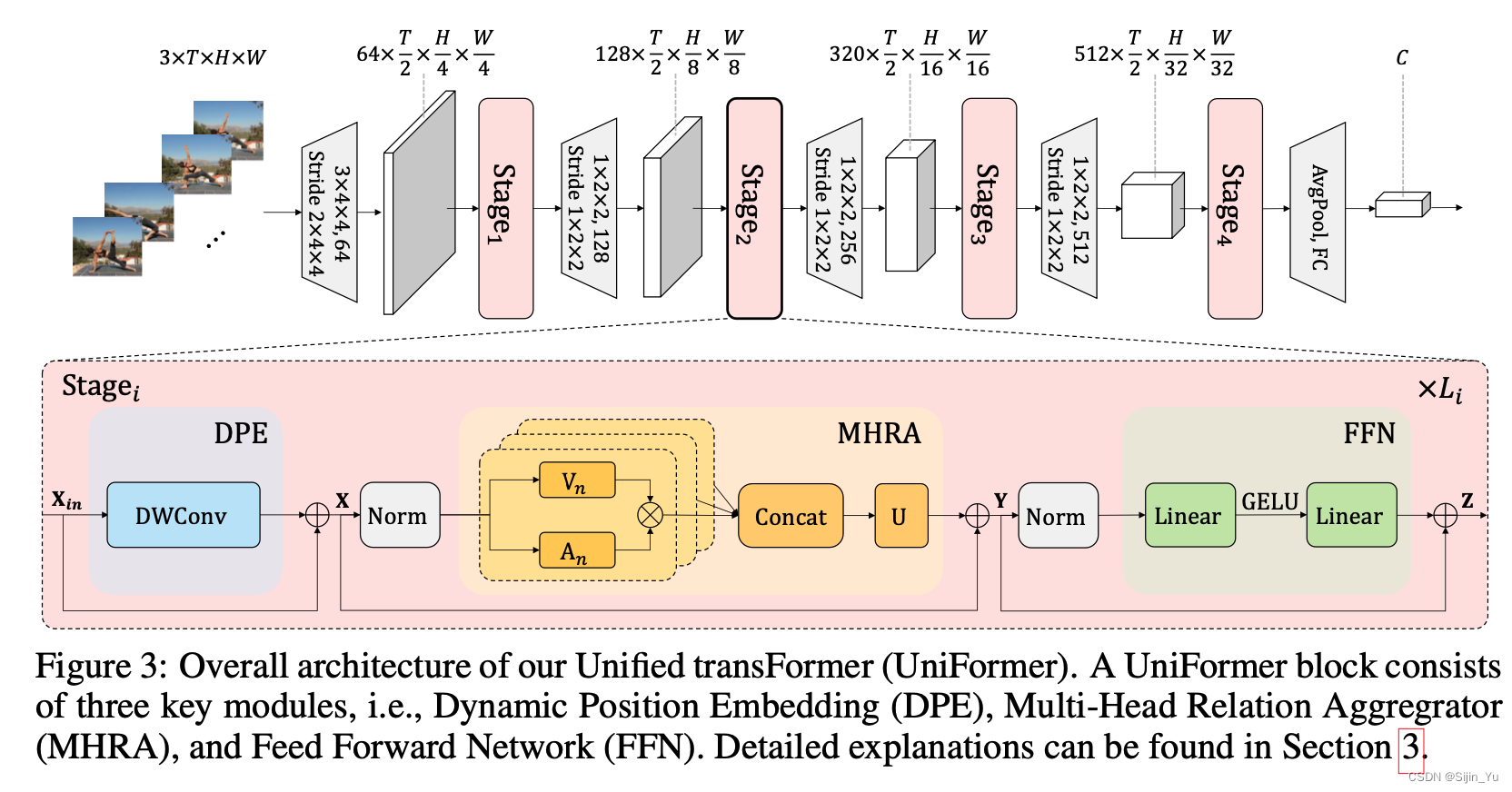
-
由 CNN 层 (灰色梯形) 和 transformer 层 (粉色圆角矩形) 组成.
-
一个 transformer 层 (Stage) 由若干个 UniFormer 块组成.
-
一个 UniFormer 块包含三个主要模块:
- DPE: Dynamic Position Embedding, 动态位置嵌入.
- MHRA: Multi-Head Relation Aggregator, 多头关系聚合器.
- FFN: Feed Forward Network, 全连接层.
具体为:
X = DPE ( X i n ) + X i n (1) \textbf{X}=\text{DPE}(\textbf{X}_{in})+\textbf X_{in} \tag{1} X=DPE(Xin)+Xin(1)Y = MHRA ( Norm ( X ) ) + X (2) \textbf Y = \text{MHRA}(\text{Norm}(\textbf X))+\textbf X \tag{2} Y=MHRA(Norm(X))+X(2)
Z = FFN ( Norm ( Y ) ) + Y (3) \textbf Z = \text{FFN}(\text{Norm}(\textbf Y))+\textbf Y \tag 3 Z=FFN(Norm(Y))+Y(3)
其中, X i n ∈ R 3 × T × H × W \textbf X_{in}\in \mathbb R^{3\times T\times H\times W} Xin∈R3×T×H×W.
3.2 Dynamic Position Embedding (DPE)
DPE ( X i n ) = DWConv ( X i n ) (4) \text{DPE}(\textbf X_{in})=\text{DWConv}(\textbf X_{in}) \tag 4 DPE(Xin)=DWConv(Xin)(4)
DWConv ( ⋅ ) \text{DWConv}(\cdot) DWConv(⋅) 是 0 填充的简单 3D depthwise 卷积.它的输出不改变
3.3 Multi-Head Relation Aggregator (MHRA)
-
给定一层的输入张量: X ∈ R C × T × H × W \textbf X \in \mathbb R^{C\times T\times H\times W} X∈RC×T×H×W.
-
将其 reshape 成一个 tokens 的序列: X ∈ R L × C \textbf X\in\mathbb R^{L\times C} X∈RL×C. 这里 L = T × H × W L=T\times H\times W L=T×H×W.
-
一层 MHRA 有 N N N 个 Relation Aggregator (RA). (即 N N N 头). 以 R n ( ⋅ ) R_n(\cdot) Rn(⋅) 指代第 n n n 个.
-
在一个 R n ( ⋅ ) R_n(\cdot) Rn(⋅) 里的行为:
R n ( X ) = A n V n ( X ) ∈ R L × C N (5) R_n(\textbf X)=A_n V_n(\textbf X)\in\mathbb R^{L\times \frac C N} \tag 5 Rn(X)=AnVn(X)∈RL×NC(5)-
V n ( ⋅ ) V_n(\cdot) Vn(⋅) 是一个全连接层, 输出形状是 R L × C N \mathbb R^{L\times\frac CN} RL×NC.
-
A n ∈ R L × L A_n\in \mathbb R^{L\times L} An∈RL×L 表示 token affinity (词单元亲和力). 它在浅层时用于提取局部亲和力, 在深层时用于提取全局亲和力. 即: MHRA 分为 Local MHRA 和 Global MHRA.
对于 Local MHRA:
-
对于 tokens 序列 X ∈ R L × C \textbf X\in \mathbb R^{L\times C} X∈RL×C, 写成 X = [ X 1 , ⋯ , X L ] T \textbf X=[\textbf X_1,\cdots,\textbf X_L]^T X=[X1,⋯,XL]T, 其中 X i ∈ R 1 × C \textbf X_i\in\mathbb R^{1\times C} Xi∈R1×C 是一个 token.
-
A n ∈ R L × L A_n\in\mathbb R^{L\times L} An∈RL×L 是一个矩阵, 其第 i i i 行、第 j j j 列的元素 (即 index 为 ( i , j ) (i,j) (i,j) 的元素) 是 tokens 序列 X \textbf X X 中的 X i \textbf X_i Xi 和 X j \textbf X_j Xj 之间的时空亲和力. 这里记作: A n l o c a l ( X i , X j ) A_n^{local}(\textbf X_i,\textbf X_j) Anlocal(Xi,Xj).
-
给定一个 token X i \textbf X_i Xi, 可以确定一个关于它的长方体 Ω i t i × h i × w i \Omega_i^{t_i\times h_i\times w_i} Ωiti×hi×wi. 这个长方体度量了它计算局部亲和力的感受野. 具体地:
t i = ⌊ i H × W ⌋ (6) t_i=\left\lfloor \frac{i}{H\times W} \right\rfloor \tag 6 ti=⌊H×Wi⌋(6)h i = ⌊ i − t i × H × W W ⌋ (7) h_i=\left\lfloor \frac{i-t_i\times H\times W}{W} \right\rfloor\tag 7 hi=⌊Wi−ti×H×W⌋(7)
w i = ( i − t i × H × W ) m o d W (8) w_i=(i-t_i\times H\times W)\mod W\tag 8 wi=(i−ti×H×W)modW(8)
这里本质上是为了保证:
给定一个目标 token X i \textbf X_i Xi, 任何一个在它感受野 Ω i t i , h i , w i \Omega_i^{t_i,h_i,w_i} Ωiti,hi,wi 内的邻居 token X j \textbf X_j Xj 应满足:
∣ t i − t j ∣ ≤ t 2 (9) |t_i-t_j|\leq\frac t2 \tag 9 ∣ti−tj∣≤2t(9)∣ h i − h j ∣ ≤ h 2 (10) |h_i-h_j|\leq\frac h2 \tag {10} ∣hi−hj∣≤2h(10)
∣ w i − w j ∣ ≤ w 2 (11) |w_i-w_j|\leq\frac w2 \tag {11} ∣wi−wj∣≤2w(11)
-
令 a n ∈ R t × h × w a_n\in\mathbb R^{t\times h\times w} an∈Rt×h×w 为可学习参数, 则
对于在 X i \textbf X_i Xi 感受野 Ω i t i × h i × w i \Omega_i^{t_i\times h_i\times w_i} Ωiti×hi×wi 内的 X j \textbf X_j Xj:
A n l o c a l ( X i , X j ) = a n [ t i − t j , h i − h j , w i − w j ] (12) A_n^{local}(\textbf X_i,\textbf X_j)=a_n[t_i-t_j,h_i-h_j,w_i-w_j] \tag{12} Anlocal(Xi,Xj)=an[ti−tj,hi−hj,wi−wj](12)
对于不在 X i \textbf X_i Xi 感受野 Ω i t i × h i × w i \Omega_i^{t_i\times h_i\times w_i} Ωiti×hi×wi 内的 X j \textbf X_j Xj:
A n l o c a l ( X i , X j ) = 0 (13) A_n^{local}(\textbf X_i,\textbf X_j)=0 \tag{13} Anlocal(Xi,Xj)=0(13)
对于 Global MHRA:
-
矩阵 A n ∈ R L × L A_n\in\mathbb R^{L\times L} An∈RL×L 的 index 为 ( i , j ) (i,j) (i,j) 的元素由 A n g l o b a l ( X i , X j ) A_n^{global}(\textbf X_i, \textbf X_j) Anglobal(Xi,Xj) 计算.
-
对于 Global 情况, 感受野变为 Ω T × H × W \Omega^{T\times H\times W} ΩT×H×W.
-
Q n ( ⋅ ) Q_n(\cdot) Qn(⋅) 和 K n ( ⋅ ) K_n(\cdot) Kn(⋅) 是两个不同的全连接层, 类似自注意力中的存在. 它们将 R C \mathbb R^{C} RC 映射为 R h i d d e n \mathbb R^{hidden} Rhidden. h i d d e n hidden hidden 是超参数.
-
A n g l o b a l ( X i , X j ) A_n^{global}(\textbf X_i, \textbf X_j) Anglobal(Xi,Xj) 的计算规则为
A n g l o b a l ( X i , X j ) = exp ( Q n ( X i ) T K n ( X j ) ) ∑ j ′ ∈ Ω T × H × W exp ( Q n ( X i ) T K n ( X j ′ ) ) (14) A_n^{global}(\textbf X_i, \textbf X_j)=\frac{\exp\left(Q_n(\textbf X_i)^TK_n(\textbf X_j)\right)} {\sum_{j'\in\Omega^{T\times H\times W}}\exp\left(Q_n(\textbf X_i)^TK_n(\textbf X_{j'})\right)}\tag{14} Anglobal(Xi,Xj)=∑j′∈ΩT×H×Wexp(Qn(Xi)TKn(Xj′))exp(Qn(Xi)TKn(Xj))(14)
-
-
-
最后, MHRA 层的行为是:
MHRA ( X ) = Concat ( R 1 ( X ) ; R 2 ( X ) ; ⋯ ; R N ( X ) ) U (15) \text{MHRA}(\textbf X)=\text{Concat}(R_1(\textbf X);R_2(\textbf X);\cdots;R_N(\textbf X))U\tag{15} MHRA(X)=Concat(R1(X);R2(X);⋯;RN(X))U(15)
其中, U ∈ R C × C U\in \mathbb R^{C\times C} U∈RC×C 是可学习的融合矩阵.
4. Experiment & Result (UniFormer)
4.1 和 SOTA 的对比
下图: 在 Kinetics-400 和 Kinetics-600 上的对比, 以低计算代价达到 SOTA 性能.

下图: 在 Something-Something V1 和 Something-Something V2 上达到 SOTA.

下图: 在计算代价和准确率之间的平衡. (横轴: 计算代价, 纵轴: 准确率)

4.2 消融实验
下图: 消融实验.
- Unified 表示是否使用 local MHRA, Joint 表示是否使用 global MHRA, DPE 表示是否使用 DPE. ✖️ 表示使用 MobileNet 块.
- Type 中的 L/G 表示四层 Stage 分别使用 Local MHRA 还是 Global MHRA.

下图: Local MHRA 中 长方体感受野的敏感性.

下图: 迁移学习的能力. 在 K400 上训练, 在 SSV1 上测试.

下图: 采样方法的敏感性. (帧数 × \times × 时间步)

下图: Multi-clip/crop 实验.
[⚠️注: Multi-clip 指将视频按不同帧切分为多个视频, 对每个视频做分类, 然后将预测结果组合起来获得最终预测结果. Multi-clop 指将每一帧裁剪为不同的区域, 分别得到不同的多个视频, 然后将各视频的预测结果组合起来获得最终预测结果]

5. Conclusion (UniFormer)
主要创新点:
- 将 CNN 和 ViT 融合.
- 设计了 token 亲和力 A n A_n An, 与自注意力有异曲同工之妙. 解决了自注意力机制盲目比较所有 token 的问题.
主要成果:
- 能同时处理局部冗余和全局冗余.
- 计算代价相对小.
6. Abstract (UniFormerV2)
- 学习具有区分性的时空特征表示是视频理解的关键问题.
- ViTs 通过自注意力展现了他们在学习长视频依赖性上的强大能力. 但不幸的是, 因为它们盲目地比较所有 tokens, 在处理局部视频冗余问题上展现出局限性.
- UniFormer 通过在 transformer 架构中整合 CNNs 和自注意力为关系聚合器 (relation aggregator), 成功地缓解了这一问题.
- 但是 UniFormer 在视频微调之前, 需要复杂的图像预训练步骤. 这限制了它的广泛应用.
- 与之相反, 大量开源的 ViTs 已经在丰富的图像监督下预训练.
- 基于这些观察, 我们通过结合预训练的 ViTs 和 UniFormer, 提出一种搭建强大视频网络族的通用范式. 我们称之为 UniFormerV2.
- 它包含了全新的 local 和 global aggregators, 并且通过集成 ViTs 和 Uniformer 的优点, 在计算代价和准确率上取得很好的平衡.
- UniFormerV2 在 8 个主流的视频 benchmarks 上获得了 SOTA 性能, 包括 K400/600/700 和 SSV1/V2. 它是第一个在 Kinetics-400 数据集上获得 90% top-1 准确率的模型.
7. Model (UniFormerV2)
7.1 Overview
-
动机: UniFormer 和 ViT 的对比

- L L L 是 Local MHRA, G G G 是 Global MHRA, T T T 是 Temporal MHSA.
- SL 是有监督学习, CL 是对比学习, MIM 是 Mask Image Modeling.
- ViTs 在图像预处理方面有优势, 而 UniFormer 在视频微调方面有优势.
- 本模型旨在融合 ViTs 和 UniFormer 的优势.
-
UniFormerV2 模型的设计和与 SOTA 的对比

比起 ViTs 的主要改进:
- 将 Temporal MHSA 改为 Loacl MHRA.
- 将 ViT 层的输出传给 Global MHRA 并将它们在最后融合.
下图: 模型框架.
7.2 Local UniBlock

Local UniBlock 的行为:
X
T
=
LT_MHRA
(
Norm
(
X
i
n
)
)
+
X
i
n
(16)
\textbf X^T=\text{LT\_MHRA}(\text{Norm}(\textbf X^{in}))+\textbf X^{in}\tag{16}
XT=LT_MHRA(Norm(Xin))+Xin(16)
其中,
LT_MHRA
(
⋅
)
\text{LT\_MHRA}(\cdot)
LT_MHRA(⋅) 表示使用局部亲和力的 MHRA. 即
A
n
(
X
i
,
X
j
)
A_n(\textbf X_i,\textbf X_j)
An(Xi,Xj) 的计算方式为式 (12) (13).
X
S
=
GS_MHRA
(
Norm
(
X
T
)
)
+
X
T
(17)
\textbf X^S=\text{GS\_MHRA}(\text{Norm}(\textbf X^T))+\textbf X^T\tag{17}
XS=GS_MHRA(Norm(XT))+XT(17)
其中,
GS_MHRA
(
⋅
)
\text{GS\_MHRA}(\cdot)
GS_MHRA(⋅) 表示使用全局亲和力的 MHRA. 即
A
n
(
X
i
,
X
j
)
A_n(\textbf X_i,\textbf X_j)
An(Xi,Xj) 的计算方式为式 (14).
X
L
=
FFN
(
Norm
(
X
S
)
)
+
X
S
(18)
\textbf X^L = \text{FFN}(\text{Norm}(\textbf X^S))+\textbf X^S\tag{18}
XL=FFN(Norm(XS))+XS(18)
[⚠️注: 留意到, Local UniBlock 的输入和输出形状是完全一样的.]
7.3 Global UniBlock
Global UniBlock 的行为:
X
C
=
DPE
(
X
L
)
+
X
L
(19)
\textbf X^C=\text{DPE}(\textbf X^L)+\textbf X^L\tag{19}
XC=DPE(XL)+XL(19)
其中,
DPE
(
⋅
)
\text{DPE}(\cdot)
DPE(⋅) 是 Dynamic Position Embedding, 同式 (4).
X
S
T
=
C_MHRA
(
Norm
(
q
)
,
Norm
(
X
C
)
)
(20)
\textbf X^{ST}=\text{C\_MHRA}(\text{Norm}(\textbf q), \text{Norm}(\textbf X^C))\tag{20}
XST=C_MHRA(Norm(q),Norm(XC))(20)
其中,
C_MHRA
(
q
,
⋅
)
\text{C\_MHRA}(\textbf q,\cdot)
C_MHRA(q,⋅) 是互注意力风格的 MHRA. 它的第
n
n
n 个关系聚合器头 (Relation Aggregator)
R
n
C
(
q
,
⋅
)
R_n^C(\textbf q,\cdot)
RnC(q,⋅) 表示如下, 其中
q
∈
R
1
×
C
\textbf q\in\mathbb R^{1\times C}
q∈R1×C 是一个可学习的 query. [⚠️注:
q
\textbf q
q 的迭代和 Multi-stage Fusion 模块有关]
R
n
C
(
q
,
X
)
=
A
n
C
(
q
,
X
)
V
n
(
X
)
(21)
R_n^{C}(\textbf q, \textbf X)=A_n^{C}(\textbf q, \textbf X)V_n(\textbf X)\tag{21}
RnC(q,X)=AnC(q,X)Vn(X)(21)
其中,
A
n
C
(
q
,
X
)
A_n^C(\textbf q,\textbf X)
AnC(q,X) 是互注意力亲和力矩阵, 用于学习
q
\textbf q
q 和
X
\textbf X
X 的关系.其计算如下:
A
n
C
(
q
,
X
j
)
=
exp
(
Q
n
(
q
)
T
K
n
(
X
j
)
)
∑
j
′
∈
Ω
T
×
H
×
W
exp
(
Q
n
(
q
)
T
K
n
(
X
j
′
)
)
(22)
A_n^C(\textbf q,\textbf X_j)=\frac {\exp\left( Q_n(\textbf q)^TK_n(\textbf X_j) \right)} {\sum_{j'\in\Omega^{T\times H\times W}}\exp\left( Q_n(\textbf q)^TK_n(\textbf X_{j'}) \right)}\tag{22}
AnC(q,Xj)=∑j′∈ΩT×H×Wexp(Qn(q)TKn(Xj′))exp(Qn(q)TKn(Xj))(22)
其中,
V
n
(
⋅
)
V_n(\cdot)
Vn(⋅),
Q
n
(
⋅
)
Q_n(\cdot)
Qn(⋅),
K
n
(
⋅
)
K_n(\cdot)
Kn(⋅) 都是全连接层.
同式 (15),
C_MHRA
(
q
,
⋅
)
\text{C\_MHRA}(\textbf q,\cdot)
C_MHRA(q,⋅) 的计算为:
C_MHRA
(
q
,
X
)
=
Concat
(
R
1
C
(
q
,
X
)
;
R
2
C
(
q
,
X
)
;
⋯
;
R
N
C
(
q
,
X
)
)
U
(23)
\text{C\_MHRA}(\textbf q, \textbf X)=\text{Concat}(R_1^C(\textbf q, \textbf X);R_2^C(\textbf q,\textbf X);\cdots;R_N^C(\textbf q,\textbf X))U\tag{23}
C_MHRA(q,X)=Concat(R1C(q,X);R2C(q,X);⋯;RNC(q,X))U(23)
最后, 计算
X
G
\textbf X^G
XG:
X
G
=
FFN
(
Norm
(
X
S
T
)
)
+
X
S
T
(25)
\textbf X^G=\text{FFN}(\text{Norm}(\textbf X^{ST}))+\textbf X^{ST}\tag{25}
XG=FFN(Norm(XST))+XST(25)
7.4 Multi-stage Fusion
这一模块的任务: 将 Local UniBlock 输出的 X L \textbf X^L XL 和 Global UniBlock 输出的 X G \textbf X^G XG 融合, 并更新 query q \textbf q q. 下图: 四种设计思路

记第 i i i 个 Global UniBlock 的输出为 X i G = G i ( q i , X i L ) \textbf X_i^G=G_i(\textbf q_i, \textbf X_i^L) XiG=Gi(qi,XiL).
-
Sequential 方式: 更新 q i \textbf q_i qi 为上一个 Global UniBlock 的输出, 即:
q 1 ← Random ( ) \textbf q_1\gets \text{Random}() q1←Random()q i = X i − 1 G \textbf q_i = \textbf X_{i-1}^G qi=Xi−1G
X i G = G i ( q i , X i L ) = G i ( X i − 1 G , X i G ) \textbf X_i^G=G_i(\textbf q_i, \textbf X_i^L)=G_i(\textbf X_{i-1}^G, \textbf X_i^G) XiG=Gi(qi,XiL)=Gi(Xi−1G,XiG)
F = X N G \textbf F =\textbf X_{N}^G F=XNG
-
Parallel 方式: 随机初始化所有的 q i \textbf q_i qi, concat 所有 X i G \textbf X^G_i XiG 并映射到对应的形状, 即:
q 1 , q 2 , ⋯ , q N ← Random ( ) \textbf q_1, \textbf q_2,\cdots,\textbf q_{N}\gets \text{Random}() q1,q2,⋯,qN←Random()X i G = G i ( q i , X i L ) \textbf X_i^G=G_i(\textbf q_i, \textbf X_i^L) XiG=Gi(qi,XiL)
F = Concat ( X 1 G ; X 2 G ; ⋯ ; X N G ) U F \textbf F = \text{Concat}(\textbf X_1^G;\textbf X_2^G;\cdots;\textbf X_N^G)U^F F=Concat(X1G;X2G;⋯;XNG)UF
其中, U F ∈ R N × C U^F\in\mathbb R^{N\times C} UF∈RN×C 是可学习的.
-
Hierarchical KV 方式: 随机初始化所有的 q i \textbf q_i qi, 但将上一个 Global UniBlock 的输出作为当前 Global UniBlock 的输入之一, 即:
q 1 , q 2 , ⋯ , q N ← Random ( ) \textbf q_1, \textbf q_2,\cdots,\textbf q_{N}\gets \text{Random}() q1,q2,⋯,qN←Random()X i G = G i ( q i , [ X i − 1 G , X i L ] ) \textbf X_i^G=G_i(\textbf q_i, [\textbf X_{i-1}^G,\textbf X_i^L]) XiG=Gi(qi,[Xi−1G,XiL])
F = X N G \textbf F =\textbf X_{N}^G F=XNG
-
Hierarchical Q 方式: 随机初始化所有的 q i \textbf q_i qi, 但将上一个 Global UniBlock 的输出作为当前 Global UniBlock 的 q \textbf q q 之一, 即:
q 1 , q 2 , ⋯ , q N ← Random ( ) \textbf q_1, \textbf q_2,\cdots,\textbf q_{N}\gets \text{Random}() q1,q2,⋯,qN←Random()X i G = G i ( [ X i − 1 G , q i ] , X i L ] ) \textbf X_i^G=G_i(\textbf [\textbf X_{i-1}^G,q_i], \textbf X_i^L]) XiG=Gi([Xi−1G,qi],XiL])
F = X N G \textbf F =\textbf X_{N}^G F=XNG
实验表明, Sequential 方式和 Hierarchical Q 方式最有效 (见消融实验部分), 模型采用 Sequential 方式作为基准.
8. Experiment & Result (UniFormerV2)
8.1 和 SOTA 的对比
下图: 在 K400 上的性能比较.

下图: 在 K600/700 上的性能比较.

下图: 在 MiT V1 上的性能比较.

下图: 在 SSV2 上的性能比较.

原文在 SSV1, ActivityNet, HACS 上也做了实验, 均达到了 SOTA.
8.2 消融实验


9. Conclusion (UniFormerV2)
主要创新点:
- 将 UniFormer 的设计放入 ViT 框架中.
- 为 X G \textbf X^G XG 的融合设计了四种方式.
10. 总结
UniFormer 设计了多头关系聚合器 (MHRA), 很好地处理了视频数据的局部冗余和全局冗余; UniFormerV2 在此基础上, 将 UniFormer 中大获成功的 MHRA 设计成块, 设计了 Local UniBlock 和 Global UniBlock, 并且设计了 Global Cross MHRA, 在 Multi-stage Fusion 中提出四种方式, 结合了 ViTs 的优点, 大大提高了视频理解的性能.


















 624
624

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











