







 本文介绍了Unity中的ComputeShader原理,包括早期GPU计算的分工与GPGPU的兴起,以及ComputeShader在Unity中的使用方法,包括格式、参数含义和调用示例。重点讲解了如何编写高效ComputeShader,以及其在性能优化中的作用。
本文介绍了Unity中的ComputeShader原理,包括早期GPU计算的分工与GPGPU的兴起,以及ComputeShader在Unity中的使用方法,包括格式、参数含义和调用示例。重点讲解了如何编写高效ComputeShader,以及其在性能优化中的作用。
【图形基础】unity compute shader
一,原理概念
早期的gpu计算中,顶点着色和片元着色完全独立,顶点着色器不能读取纹理,开发者需要按照算力分配vs和fs的复杂度来保证效率,并且图形还需要经过一系列图形管线处理。如下图。
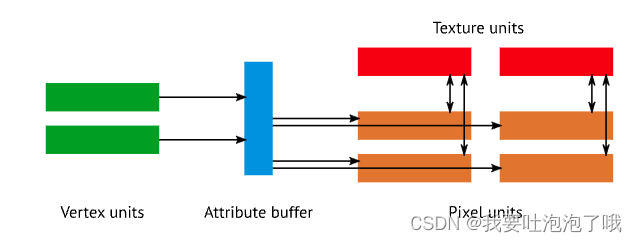
不过随着非图形计算的需求增大,出现了GPGPU(General Purpose GPU,GPU通用计算)业务场景,图形硬件开始引入一种统一的计算单元来处理vertex和pixel,不需要经过图形流水线而是直接用gpu并行计算。如下图,顶点着色和片元着色合并为“compute units”处理。【也有更复杂的内存系统】
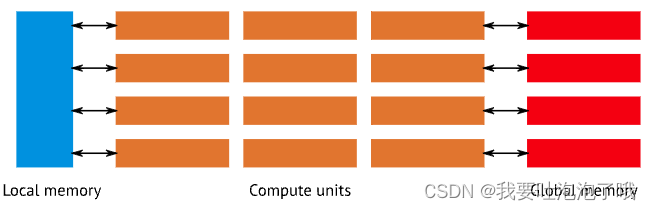
- GPU包含很多compute units,每个compute unit又包含了:
- 若干SIMD units((single instruction multiple data)),由它们来实际执行指令
- 每个SIMD unit可以对多个elements进行同一个操作
- 每个compute unit内部包含了一些local memory,可以用于不同shader stages之间的通信
实现这种计算的Shader,就是Compute Shader。
- 主要优势:
1. 利用gpu的compute units实现高效并行计算
2. 比vertex-frag的方式能更快交换数据,减少CPU bottleneck,避免使用昂贵的多Pass,灵活性更高
3. 语义可以在图形、空间外 - 限制性:
- 不是所有效果都适合用compute shader,比如传统fs里做的很多简单后处理,用其反而降低效率
- 有些gpu架构缺少特定硬件,导致需要针对性设计、兼容
- 难开箱即用,需要不断测试优化
- 为了编写高效的compute shader,应该:
- 把一个大问题分成尽可能多的若干独立的work items,分得越多越好
- 尽量使用uniform变量,速度快,内存小
- 如果代码需要频繁访问内存,应当尽可能减少状态保存
- 一个线程组内避免使用分支
- 将for循环指令拆开
二,unity compute shader
2.1 compute shader格式、参数含义
在unity的中右键-Create-Shader-Compute Shader创建,后缀为 .compute 。
//声明kernel的函数名,至少有一个,可以定义预处理宏
#pragma kernel CSMain
#pragma kernel KernelOne SOME_DEFINE DEFINE_WITH_VALUE=1337
#pragma kernel KernelTwo OTHER_DEFIN 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 564
564

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









