






Broad and deep neural network for high-dimensional data representation learning
- 由于结构浅,BLS存在高维数据分类困难的问题。为此,本文从表示学习的角度提出了卷积特征映射和增强映射广义学习系统(CCFEBLS)框架的级联。
- 首先,利用卷积核构造卷积特征节点和增强节点,而不是在BLS中使用稀疏自编码或线性组合;
- 其次,设计了一种新颖的广深架构,将特征映射和增强映射级联为广深表示,直接连接CCFEBLS框架的输出。该体系结构充分利用了所有表示形式,提高了表示学习能力。
- 此外,为了提高CCFEBLS的鲁棒性,分别采用加权超参数和群正则化来调整广义表示和深度表示,并要求群输出直接接近标签。
Introduction
- 表征学习方法大致可分为三类
- 特征工程
- 数据转换
- 基于深度学习模型的自动表示学习方法
- 深度学习的网络架构探索
- CNN和VGG模型
- 残差网络(ResNet)和宽残差网络(WRNs)
- DenseNet
- ShuffleNet
- BLS
- 鲁棒广义学习系统(RBLS)
- 带有判别信息的图正则化广义学习系统(GBLS)
- 正则化 : 提高表示学习的鲁棒性和质量
- l 2 l_2 l2范数正则化、组稀疏正则化、批规范化和dropout技术
- Cutout正则化
- 由于结构较浅,从BLS中学习到的特征在RGB真实图像分类中表现力不足。CNN有利于提取真实图像的抽象特征,因为每个卷积核都吸收图像的信息,同时从所有像素中提取特征。因此,在特征节点和增强节点上应用卷积核来提高BLS的表示学习能力是我们的思路和动机。本文利用卷积核的优点,将宽深度结构、加权超参数和群正则化相结合,提出了用于高维数据表示学习和分类的卷积特征映射和增强映射广义学习系统(CCFEBLS)。
- 通过将特征映射和增强映射前馈连接起来,本文首次实现了新颖的广深网络架构CCFEBLS框架。它将特征映射和增强映射级联为广义和深度表示,以直接连接输出。
- 引入一组加权超参数对广义和深度表示进行调整和归一化,重点介绍了最后一组增强映射,进一步提高了CCFEBLS的表示学习能力。
- 为了增强CCFEBLS的鲁棒性,我们利用标签信息对广义和深度表示进行正则化,并提出将群正则化嵌入到目标函数中。
- CCFEBLS具有更高的测试精度、更少的参数和训练时间。
The Proposed CCFEBLS Model
The Broad and Deep CCFEBLS Modeling
- 与BLS中的特征节点和增强节点类似,CCFEBLS也具有特征映射和增强映射。与BLS不同的是,受深度学习网络的启发,CCFBLS将每组特征映射/增强映射前馈和顺序地连接起来。因此,特性映射和增强映射的每一组都是级联的,彼此不是独立的。此外,CCFEBLS通过将特征映射和增强映射连接在一起,得到了广义和深度的表示
- 在图(a)中CCFEBLS网络有
n
n
n组特征映射和
m
m
m组增强映射。特征映射和增强映射中的每一组都采用
F
F
F个卷积构建块叠加前馈构造,一组特征映射或增强映射的结构如图3(b)所示
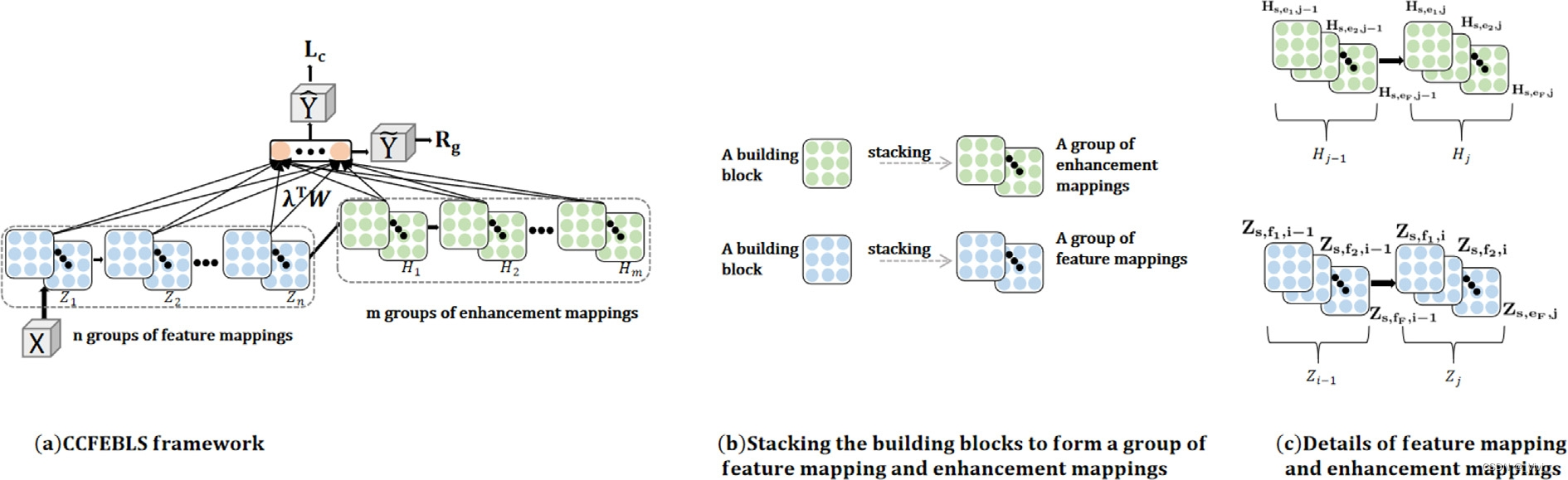
- 传统的深度学习网络只使用最后一层的表示来对数据进行分类。然而,它可能会错过一些隐藏在浅层中的重要表示。对于广义学习系统,表示法的学习能力受到浅层结构的限制。具有广深架构的CCFEBLS框架充分利用所有特征映射和增强映射,增强CCFEBLS在高维数据上的表示学习能力。
The Group Regularization
- 将标签看作是一种先验知识,继续提出通过定义组输出和组正则化来提高特征映射的质量和增强映射。
- 分组正则化的目的是让分组输出尽可能接近标签。假设one-hot标签向量和模型输出也可以描述为标签分布和输出分布,通过群正则化,随着优化过程中CCFEBLS的输出分布变得更加清晰,分类的性能变得更好。群正则化充分利用了所有的特征映射和增强映射,增强了CCFEBLS的逼近能力。本文的实验也表明,群正则化提高了CCFEBLS的分类性能。
Final Loss of CCFEBLS
- 已知交叉熵损失、罚正则化损失和群正则化,得到CCFEBLS的最终损失函数。使用随机梯度下降进行优化。
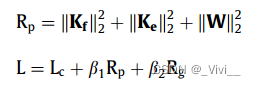

CCFEBLS Variants
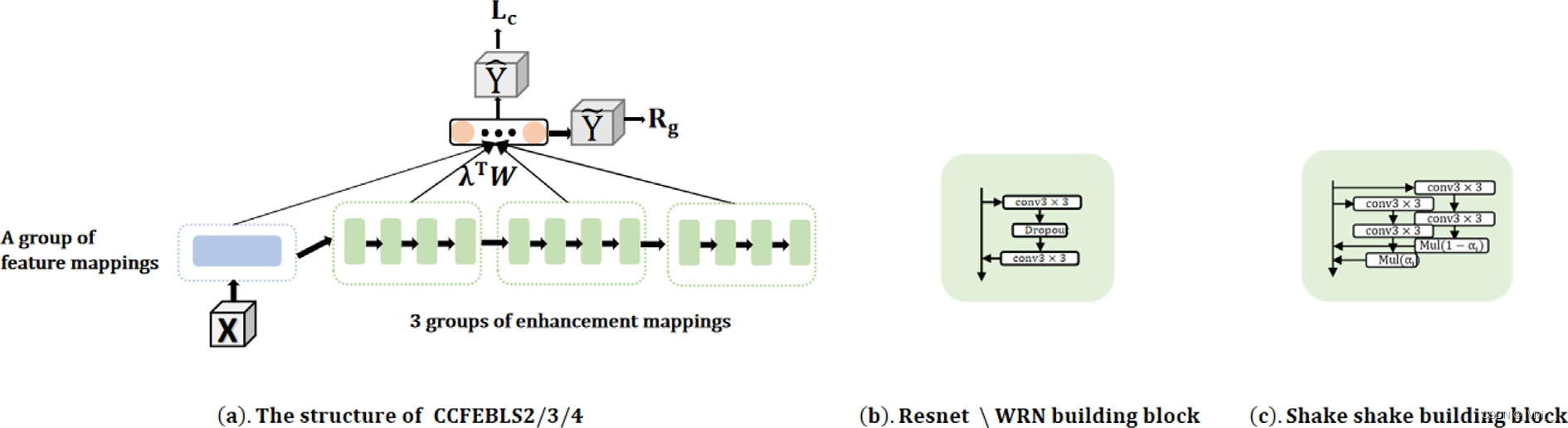
CCFEBLS变体可以用不同的构建块灵活地构建
WRN Building Blocks based CCFEBLS2
- 对于基于WRN构建块的CCFEBLS2
- 共有28个层次卷积层,用缩写CCFEBLS2-28来表示。
- CCFEBLS2模型的总体结构如图(a)所示。
- CCFEBLS2-28模型有一组由单一卷积层组成的特征映射。
- CCFEBLS2-28有3组增强映射,用于为输出提供分层的广泛和深度表示。每组增强映射都是通过前馈叠加4个WRN构建块构建的。
- WRN构建块的细节如图(b)所示。WRN构建块中有2个分支,第一个分支包含两个连通前馈的卷积层,WRN构建块中的第二个分支是一个标识映射。
Shake-shake Regularization Building Blocks based CCFEBLS4
- shake-shake正则化网络证明了在每次迭代的前向和后向训练过程中对卷积核的梯度进行弱振荡有利于提高表示的鲁棒性。
- 按照这个策略,提出了CCFEBLS4模型,其中增强映射是用抖动-抖动构建块构造的。CCFEBLS4-26共包含26个卷积层,CCFEBLS4-26中有1组特征映射和3组增强映射。每组增强映射都是用4个前馈3分支shake-shake构建块构造的。
- 在每个shack-shack构建块中(如图©所示),第1支和第2支是卷积特征学习分支,第3支是直接将输入传输到下一个计算的身份映射。梯度的抖动函数是通过将超参数分别与第1分支和第2分支的输出相乘来实现的。
Model analysis and discussion
- 在BLS中,特征节点与增强节点的级联向量仅捕获浅层特征,这不足以帮助建立与单热标签的强连接,导致分类结果较低,因此使用卷积构建块来构建CCFEBLS。所提出的CCFEBLS模型使用SGD优化方法找到最优权重,将广义和深度表示映射到单热标签向量。它可以避免大尺度和高维数据由于逆计算需要非常大的空间而影响BLS分类性能的困难。
- 由于特征映射和增强映射直接与输出连接,因此提出的广深架构有助于提高分布捕获能力。在优化过程中,它们的误差由最后一层误差和顶部输出层误差两部分组成。它可以防止梯度消失问题,加快优化速度。另一方面,这种架构带来了由k集加权的广义和深度表示,它为近似标签分布ys提供了最重要的表示。
- 与前馈深度学习模型仅使用最终隐层特征对数据进行分类相比,与使用浅层特征近似标签的BLS相比,CCFEBLS吸收了深度学习模型和广义学习系统的优点,提供了广义和深度表示来更好地完成分类
- 分析所提出的群正则化的有效性。在优化过程中,特征映射和增强映射的分布分别变得更加清晰,表达能力和表示能力的质量逐渐增强。提出的组表示正则化增强了CCFEBLS的鲁棒性,因为中的正则化要求组输出等于标签分布。
Experiments
Experiments on CIFAR10 and CIFAR100
对CIFAR10、CIFAR100、SVHN和模拟合成SVHN在内的高维数据集进行了大量的实验,以验证CCFEBLS模型。
- 在CIFAR10和CIFAR100上的分类结果表明,CCFEBLS模型的表现比BLS方法与深度学习模型好。
- 此外,CCFEBLS模型优于基线深度模型,因为在每组对比实验中,CCFEBLS模型在CIFAR10和CIFAR100数据集上的测试分类精度高于相应的深度学习模型。
- 增加增强映射的长度可以提高CCFEBLS模型的测试精度。随着增强图长度从18增加到34再增加到50,CCFEBLS1在CIFAR10和CIFAR100上的测试精度逐渐提高。
- 在保持增强映射长度不变的情况下,增加增强映射的基本通道数量也提高了CCFEBLS4模型的分类能力。
- CCFEBLS1-18的测试精度高于Res-50的测试精度,是所有ResNets中的最佳结果。
- CCFEBLS1-18模型的训练时间和参数更少,这表明CCFEBLS模型可以简化深度学习网络的计算和时间消耗。
- CCFEBLS2-28的分类精度在CIFAR10和CIFAR100上都优于WRN-34,且参数和训练时间更少。
Experiments on SVHN
- CCFEBLS3R-18和CCFEBLS3W-16的测试精度分别高于Cu_Res-18和Cu_WRN-16。
- CCFEBLS3R-18和CCFEBLS3W-16的分类结果优于两种不同优化方法的BLS方法,表明所提模型提高了BLS对高维数据的表示学习能力和分类能力。
Experiments on Simulated and Synthetic SVHN
- 本文提出的CCFEBLS3R-18在合成数据上的表现仍然优于ResNet-18模型,这也表明了本文提出的CCFEBLS无论是在原始SVHN数据集上,还是在模拟和合成SVHN数据集上都具有鲁棒性。实例验证了CCFEBLS框架的分类能力与理论分析相一致。
The Effect of Group Regularization
- 在CIFAR100上测试了Cu Res-18, CCFEBLS3R-18的群正则化和CCFEBLS3R-18没有群正则化。
- 从表实验结果来看,对比Cu Res-18和没有进行组正则化的CCFEBLS3R-18, CCFEBLS3R-18的测试精度高于Cu Res-18,这表明即使没有进行组正则化,所提出的CCFEBLS结构在高维数据集分类上也更有效。
- 对比未进行群正则化的CCFEBLS3R-18和进行群正则化的CCFEBLS3R-18的测试精度,我们可以得出结论,提出的群正则化有助于进一步提高CCFEBLS的分类性能。
The Hyper-parameters Sensitivity Analysis of the CCFEBLS
- 分析超参数的敏感性, 提出参数选择方法。














 1153
1153











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









