






一、image_encoder
vit结构
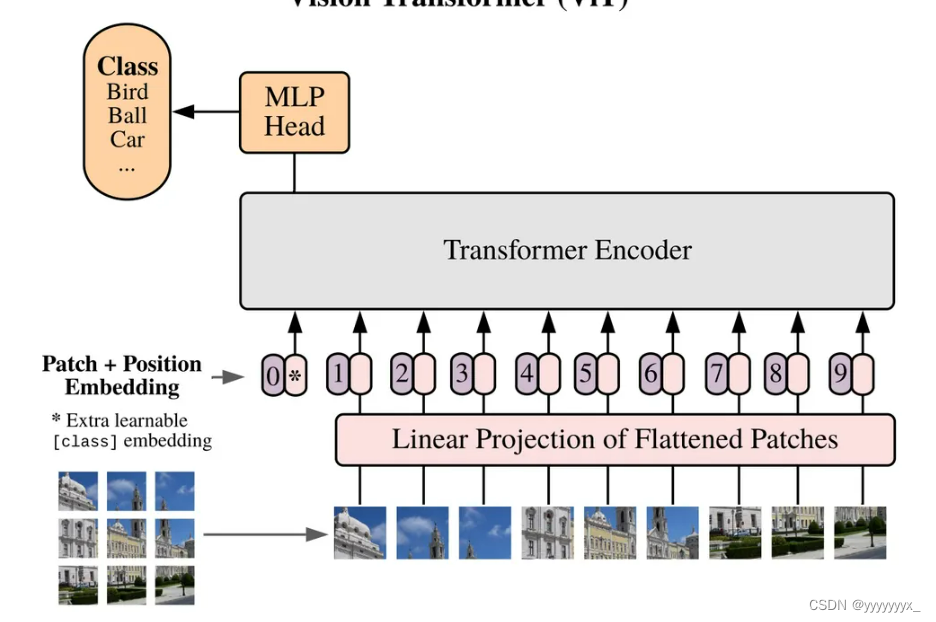
SAM的image_encoder结构

输入的图像会resize到 1024×1024 ,然后通过一个卷积核为16且步长为16的卷积下采样到 64×64 ,之后加入位置编码送入Transformer Block中。
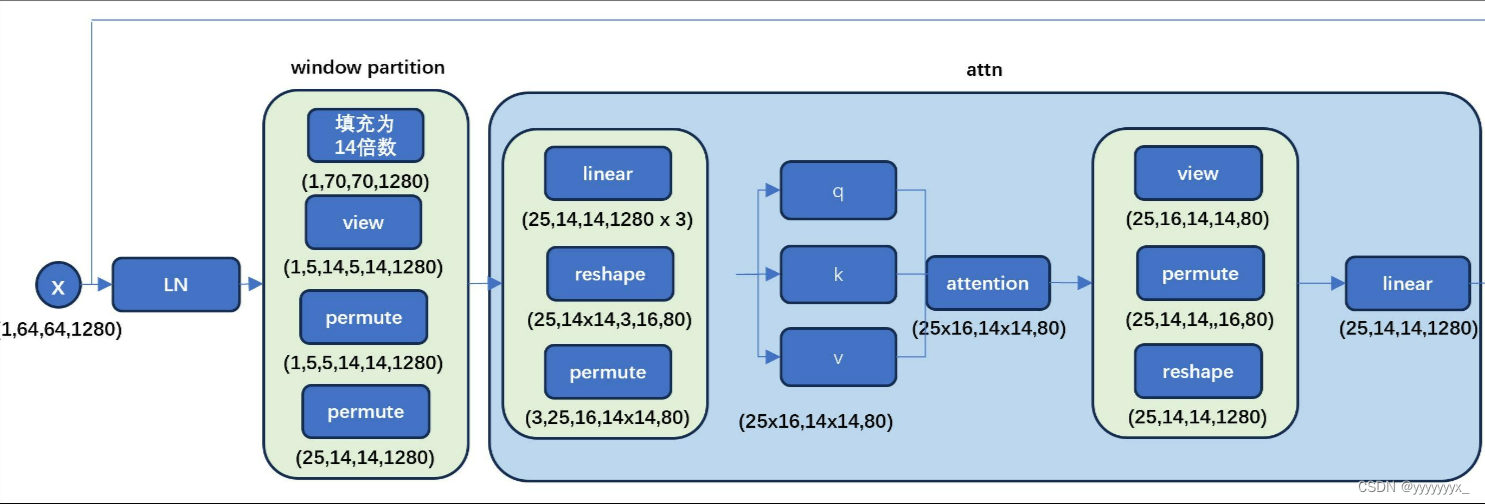
class Attention(nn.Module):
"""Multi-head Attention block with relative position embeddings."""
def __init__(
self,
dim: int,
num_heads: int = 8,
qkv_bias: bool = True,
use_rel_pos: bool = False,
rel_pos_zero_init: bool = True,
input_size: Optional[Tuple[int, int]] = None,
) -> None:
"""
Args:
dim (int): Number of input channels.
num_heads (int): Number of attention heads.
qkv_bias (bool): If True, add a learnable bias to query, key, value.
rel_pos (bool): If True, add relative positional embeddings to the attention map.
rel_pos_zero_init (bool): If True, zero initialize relative positional parameters.
input_size (tuple(int, int) or None): Input resolution for calculating the relative
positional parameter size.
"""
super().__init__()
self.num_heads = num_heads
head_dim = dim // num_heads
self.scale = head_dim**-0.5
self.qkv = nn.Linear(dim, dim * 3, bias=qkv_bias)
self.proj = nn.Linear(dim, dim)
self.use_rel_pos = use_rel_pos
if self.use_rel_pos:
assert (
input_size is not None
), "Input size must be provided if using relative positional encoding."
# initialize relative positional embeddings
self.rel_pos_h = nn.Parameter(torch.zeros(2 * input_size[0] - 1, head_dim))
self.rel_pos_w = nn.Parameter(torch.zeros(2 * input_size[1] - 1, head_dim))
def forward(self, x: torch.Tensor) -> torch.Tensor:
B, H, W, _ = x.shape
# qkv with shape (3, B, nHead, H * W, C)
qkv = self.qkv(x).reshape(B, H * W, 3, self.num_heads, -1).permute(2, 0, 3, 1, 4)
# q, k, v with shape (B * nHead, H * W, C)
q, k, v = qkv.reshape(3, B * self.num_heads, H * W, -1).unbind(0)
attn = (q * self.scale) @ k.transpose(-2, -1)
if self.use_rel_pos:
attn = add_decomposed_rel_pos(attn, q, self.rel_pos_h, self.rel_pos_w, (H, W), (H, W))
attn = attn.softmax(dim=-1)
x = (attn @ v).view(B, self.num_heads, H, W, -1).permute(0, 2, 3, 1, 4).reshape(B, H, W, -1)
x = self.proj(x)
return x
而这段代码就对应的是上图的Attention
Transformer Block和上图ViT中的Transformer Encoder结构完全相同,根据SAM模型大小的不同,Block数量也会各不相同。在Block内部特征图被切分为 14×14 的小块,值得注意的是由于 64×64 不能正好完全切分,需要先Pad成 70×70 ,然后切成 7014×7014=5×5=25 个小块。
二、prompt_encoder
prompt分为dense prompt(mask图)和sparse prompt(点和框和文字)。dense prompt的输入经过几层卷积后就和image embedding相加,而sparse prompt经过复杂处理(文中说参考了这按文章的编码方式:Fourier Features Let Networks Learn High Frequency Functions in Low Dimensional Domains)最终形状为 64×2×256 的prompt tokens。(我们以SAM分割图片所有物体为例,首先会自动产生 32×32=1024 个点均匀分布在输入图像上,然后每次选出64个点计算对应的mask,这就是sparse prompt形状第一维为64的原因)。
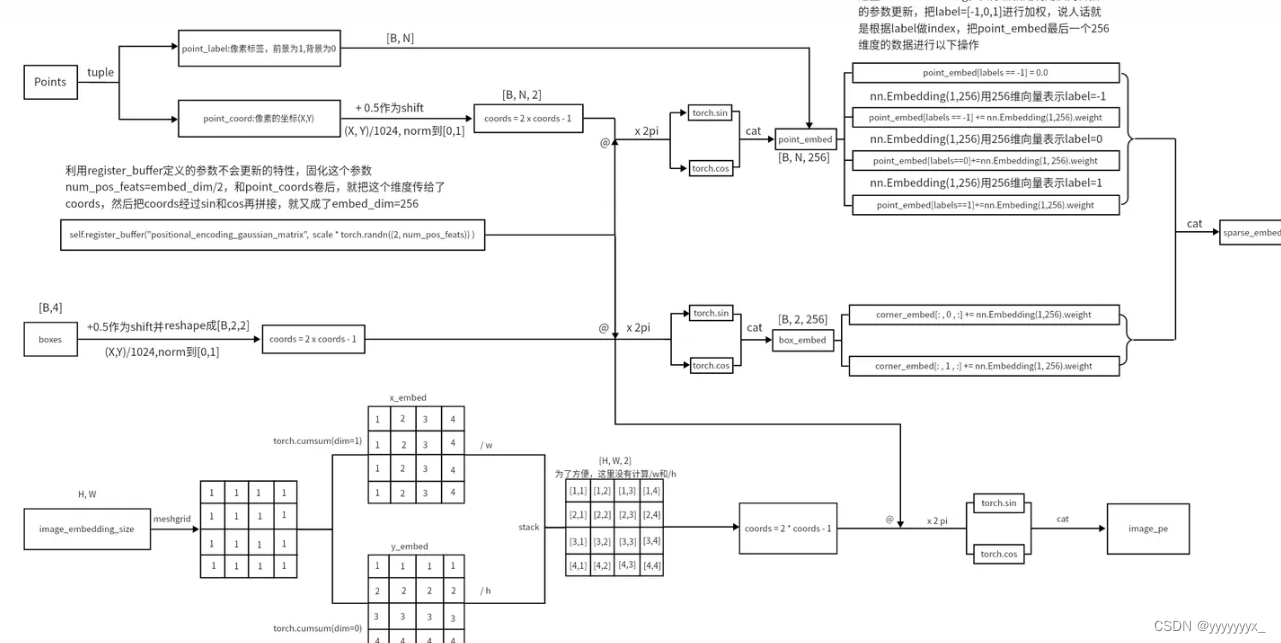
此外还会生成一个 64×1×256 的IoU token和 64×4×256 的mask token,两者拼接在一起组成 64×5×256 output tokens,然后output tokens和prompt tokens拼接为 64×7×256 的token送入mask decoder。
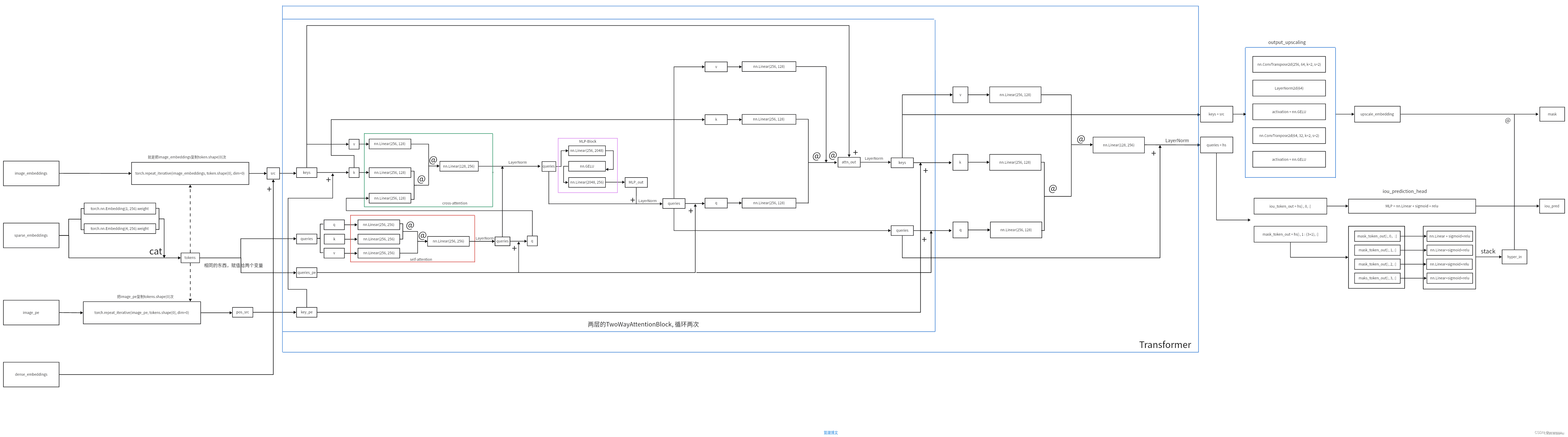
三、mask decoder
mask decoder和常规的语义分割网络有很大差别,这里作者主要参考了DETR和MaskFormer两篇文章的结构。以Unet为例,假设我们语义分割的目标有猫、狗和猪,那么网络经过处理最终会输出一个四层的特征图(包含背景,也就是不属于猫狗猪),特征图上每一个像素点有四个通道,表示这个像素点属于每一类的概率。而在SAM中经过image encoder得到了图像的特征图后,我们产生一些mask token和特征图做cross attention,这些mask token就相当于查询向量,每一个mask token最终都会预测一个分割图。
文字描述很晦涩,以目标检测中的DETR为例,图像经过backbone和encoder后会送入decoder,注意decoder中的另一个输入是object queries相当于查询向量,有4个(以这张图举例,实际会有上百个)object queries送入decoder最终也会输出4 个向量,折4 个向量经过简单后处理后每个都会预测一个检测框。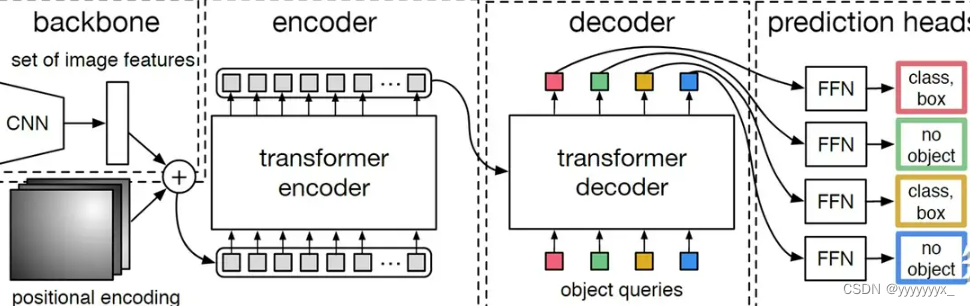
MaskFormer中的一张图,将语义分割分为per-pixel classifications和per-mask classification,SAM和MaskFormer就属于后者。















 663
663

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









