






一、我们为什么要微调SAM模型
SAM(Segment Anything Model)是一种通用图像分割模型,能够对任何类型的图像进行分割。然而,医疗领域有一些独特的需求和挑战,使得在这个领域对SAM进行微调是必要的。以下是一些原因:
数据的特殊性:
医疗图像,如MRI、CT扫描、X光片等,与日常图像有很大的不同。它们通常包含更复杂和细致的结构,需要特定的医学知识来正确理解和标注。
医疗图像的纹理、对比度和噪声特征也不同于一般的自然图像,因此需要专门训练来适应这些特征。
高精度需求:
在医疗领域,图像分割的精度非常关键,因为错误可能会导致误诊或漏诊,从而对患者的健康产生严重影响。
SAM虽然是通用模型,但在高精度要求的情况下,需要进行微调以提高其在特定医疗任务中的准确性和可靠性。
标注数据的差异:
医疗图像的标注通常由专业的医学专家完成,标注标准和细节要求更高。
SAM需要适应这些高标准的标注,以提供符合医疗诊断需求的分割结果。
特定病症的检测:
不同的疾病在图像上的表现形式各异,需要针对特定病症的分割能力。例如,肿瘤、病变区域、器官边界等的分割任务都有其独特的挑战。
通过微调,可以使SAM在特定病症的检测和分割上表现更好。
二、如何对SAM进行微调
SAM在医疗领域进行微调的操作并非是一个开创性的工作,我们目前是有很多论文可以参考借鉴的。
比较好的方法就是有adapter,PEFT,阶梯型优化的方法。
我们先来看看现有的一些方法是如何对SAM进行微调的。
《基于SAM的医学图像分割--阶梯式微调》
SAM由三个部分组成,这些部分包括图像编码器、提示编码器和遮罩解码器。图像编码器采用经过MAE预训练的ViT网络来提取图像特征。提示编码器支持四种类型的提示输入:点、框、文本和遮罩。点和框使用位置编码进行嵌入,而文本则使用CLIP中的文本编码器进行嵌入。遮罩使用卷积操作进行嵌入。遮罩解码器旨在以轻量级方式映射图像嵌入和提示嵌入。这两种类型的嵌入通过交叉关注模块进行交互,使用一个嵌入作为查询,另一个嵌入作为键和值向量。最终,使用转置卷积对特征进行上采样。遮罩解码器具有生成多个结果的能力,因为提供的提示可能存在歧义。默认的输出数量设置为三个。值得一提的是,图像编码器对每个输入图像只提取一次图像特征。之后,轻量级的提示编码器和遮罩解码器可以根据不同的输入提示与用户实时在网页浏览器中进行交互。
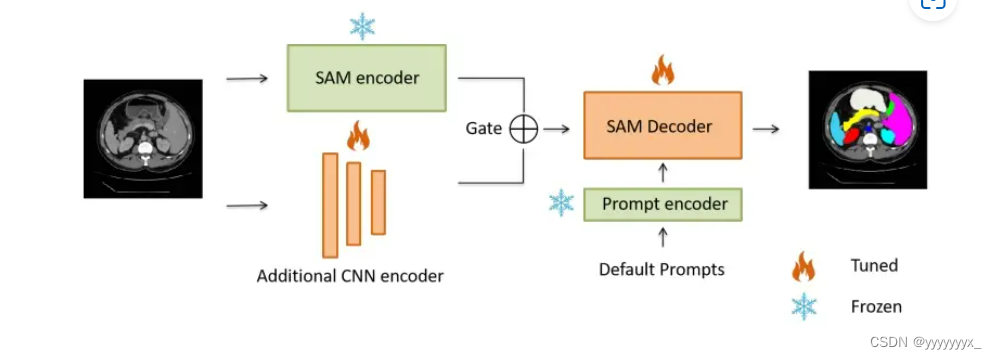
《使用adapter微调SAM应用于医学图像(2023+Medical SAM Adapter: Adapting SegmentAnything Model for Medical Image)》
方法主要是在ViT块中嵌入Asapter块,模型冻结其他参数,只对adaper块进行更新。
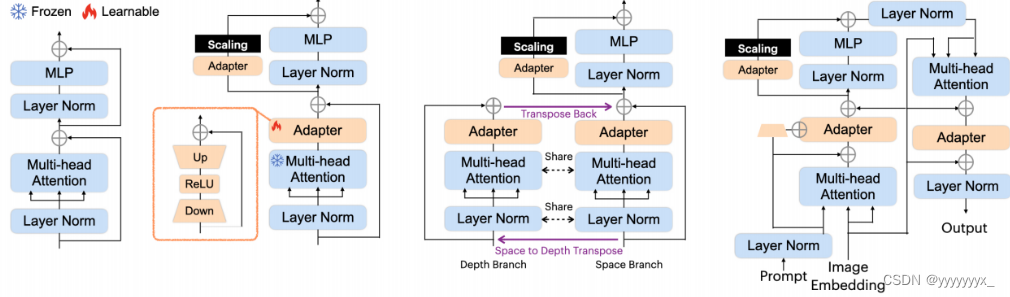
如图b中所示,adapter有down、relu、up三部分构成 。down使用简单的MLP层将给定的嵌入压缩到更小的维度;up使用另一个MLP层将压缩的嵌入扩展回其原始维度,relu是指的relu函数。
图a是原始SAM中的Vit块。
图b表示应用2D医学图像的修改,在多头注意力机制和残差块之后分别插入adapter,并在adater之后进行缩放。
图c表示应用3D医学图像的修改,主要考虑深度相关的影响。将一个VIT块分成两个分支,depth branch 和 space branch,对于给定深度为D的3D样本,我们将D x N x L发送到空间分支中的多头注意力,其中N为嵌入的数量,L为嵌入的长度。在这里,D是操作的数量,并且在N x L上应用交互来学习和抽象空间相关性作为嵌入。在深度分支中,我们首先对输入矩阵进行转置,得到N x D x L,然后将其发送到相同的多头注意。虽然我们使用相同的注意机制,但交互作用应用于D x l。通过这种方式,深度相关性被学习和抽象。最后,我们将深度分支的结果转回其原始形状,并将其添加到空间分支的结果中。
图d表示用于提示的修改。如图加入三个adapter。
训练策略:
图像编码器:与SAM中使用的MAE预训练不同,我们使用了几种自监督学习方法的组合进行预训练。前两种分别是对比嵌入-混合预测(e-Mix)和洗牌嵌入预测(ShED)[32]。e-Mix是一种对比目标,它将一批原始输入嵌入进行加性混合,并用不同的系数对它们进行加权。然后,它训练编码器为混合嵌入生成一个向量,该向量与原始输入的嵌入按混合系数的比例接近。ShED对一小部分嵌入进行洗刷,并用分类器训练编码器来预测哪些嵌入受到了干扰。在SAM的原始实现之后,我们还使用了掩码自编码器(MAE),它掩码给定部分的输入嵌入并训练模型来重建它们。
提示编码器:对于单击提示,正数单击表示前景区域,负数单击表示背景区域。我们使用随机和迭代点击抽样策略的组合来训练这个提示。具体来说,我们首先使用随机抽样进行初始化,然后使用迭代抽样过程添加一些点击。迭代采样策略类似于与真实用户的交互,因为在实践中,每次新的点击都被放置在由网络使用先前点击集产生的预测的错误区域中。我们生成随机抽样,模拟迭代抽样。我们在SAM中使用了不同的文本提示训练策略。在SAM中,作者使用CLIP生成的目标对象作物的图像嵌入作为接近其在CLIP中对应的文本描述或定义的图像嵌入。然而,由于CLIP几乎没有在医学图像数据集上进行训练,因此它很难将图像上的器官/病变与相应的文本定义联系起来。相反,我们首先从ChatGPT中随机生成几个包含目标(即视盘,脑肿瘤)定义作为关键字的自由文本,然后使用CLIP作为训练提示提取文本的嵌入。一个自由文本可以包含多个目标,在这种情况下,我们用所有相应的掩码来监督模型。

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









