






前言
码字不易,SD 保姆教程,从原理功能到案例输出展示,最后SD所有资源–请看结尾,图文约 1 万 5 千字左右,阅读时长约 20 分钟~
Stable Diffusion 的基本介绍
首先官方给出的解释是:

一、基础介绍
1. 提示词:
提示词分为两个部分
正向提示词:
生成图像时,我们可以使用正向提示词来指定想要生成的图像。正向提示词可以是脑子里想到的图片或一句话,将其拆分成不同的关键词,并用逗号隔开作为输入。
需要注意的是,相同的指令在不同的模型库和参数下,生成的输出图像可能会不一样。此外,提示词的顺序也非常重要,因为它们的顺序会影响到生成图像的权重。通常情况下,越靠前的提示词权重越大,越靠后的提示词权重越小。
排除词:
输入框内输入的标签内容就是你画面中不想要出现的东西,如:低质量的,缺手指,五官不齐等等




本次教程将使用AI绘画工具 Stable Diffusion 进行讲解,如还未安装SD的小伙伴可以扫描免费获取哦~
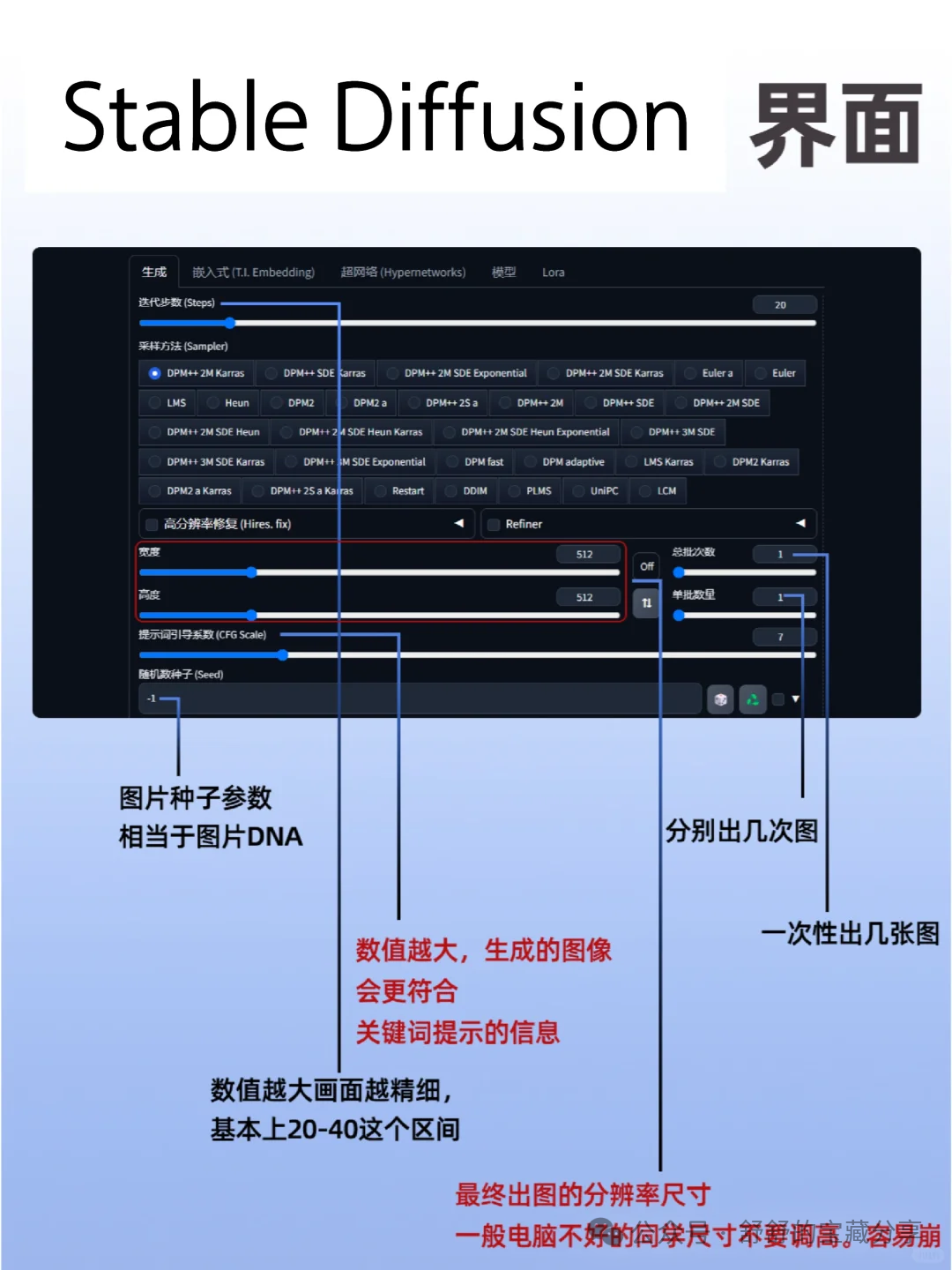
二、界面部分
1. 采样迭代步数
输出画面需要的步数,每一次采样步数都是在上一次的迭代步骤基础上绘制生成一个新的图片,一般来说采样迭代步数保持在 18-30 左右即可,低的采样步数会导致画面计算不完整,高的采样步数仅在细节处进行优化,对比输出速度得不偿失。
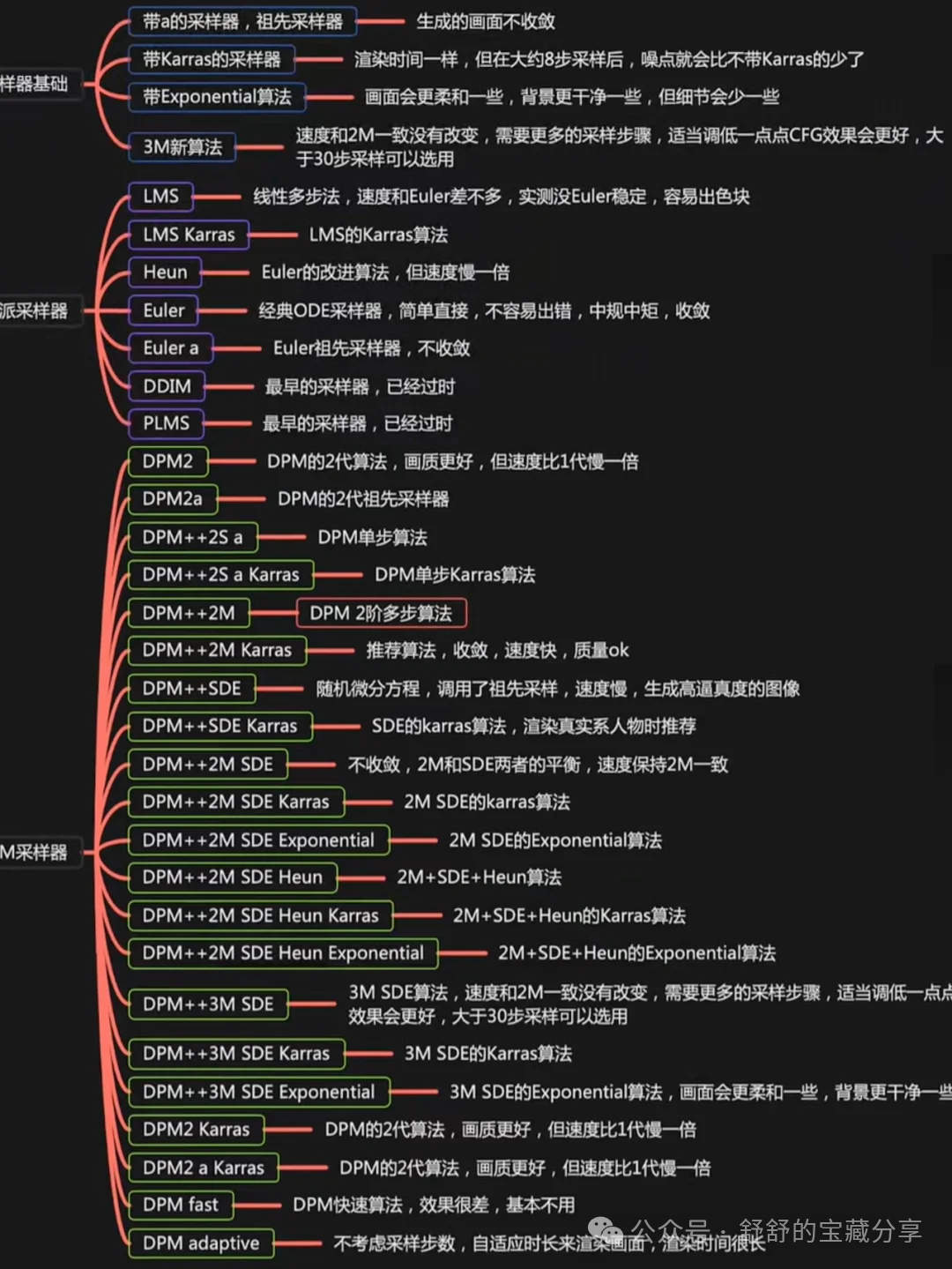
2. 采样方法的介绍
推荐10款SD-好用且高效的采样器:⬇️
DPM++ 2M Karras
DPM++ SDE Karras
PM++ 2M SDE Exponential
DPM++ 2M SDE Karras
Euler a
Euler
DPM++ 3M SDE Karras
PM++ 3M SDE Exponential
Restart
UniPC
————
⚠️码住以上采样器,SD出图质量有保证‼️




3. 提示词相关性
Stable Diffusion 中的提示词相关性指的是输入提示词对生成图像的影响程度。当我们提高提示词相关性时,生成的图像将更符合提示信息的样子;相反,如果提示词相关性较低,对应的权重也较小,则生成的图像会更加随机。因此,通过调整提示词相关性,可以引导模型生成更符合预期的样本,从而提高生成的样本质量。
①在具体应用中,对于人物类的提示词,一般将提示词相关性控制在 7-15 之间;
②而对于建筑等大场景类的提示词,一般控制在 3-7 左右。这样可以在一定程度上突出随机性,同时又不会影响生成图像的可视化效果。因此,提示词相关性可以帮助我们通过引导模型生成更符合预期的样本,从而提高生成的样本质量。
4. 随机种子
随机种子是一个可以锁定生成图像的初始状态的值。当使用相同的随机种子和其他参数,我们可以生成完全相同的图像。设置随机种子可以增加模型的可比性和可重复性,同时也可以用于调试和优化模型,以观察不同参数对图像的影响。
在 Stable Diffusion 中,常用的随机种子有-1 和其他数值。当输入-1 或点击旁边的骰子按钮时,生成的图像是完全随机的,没有任何规律可言。而当输入其他随机数值时,就相当于锁定了随机种子对画面的影响,这样每次生成的图像只会有微小的变化。因此,使用随机种子可以控制生成图像的变化程度,从而更好地探索模型的性能和参数的影响。
在工作产出中,如果细微调整,我们将会固定某个种子参数然后进行批量生成
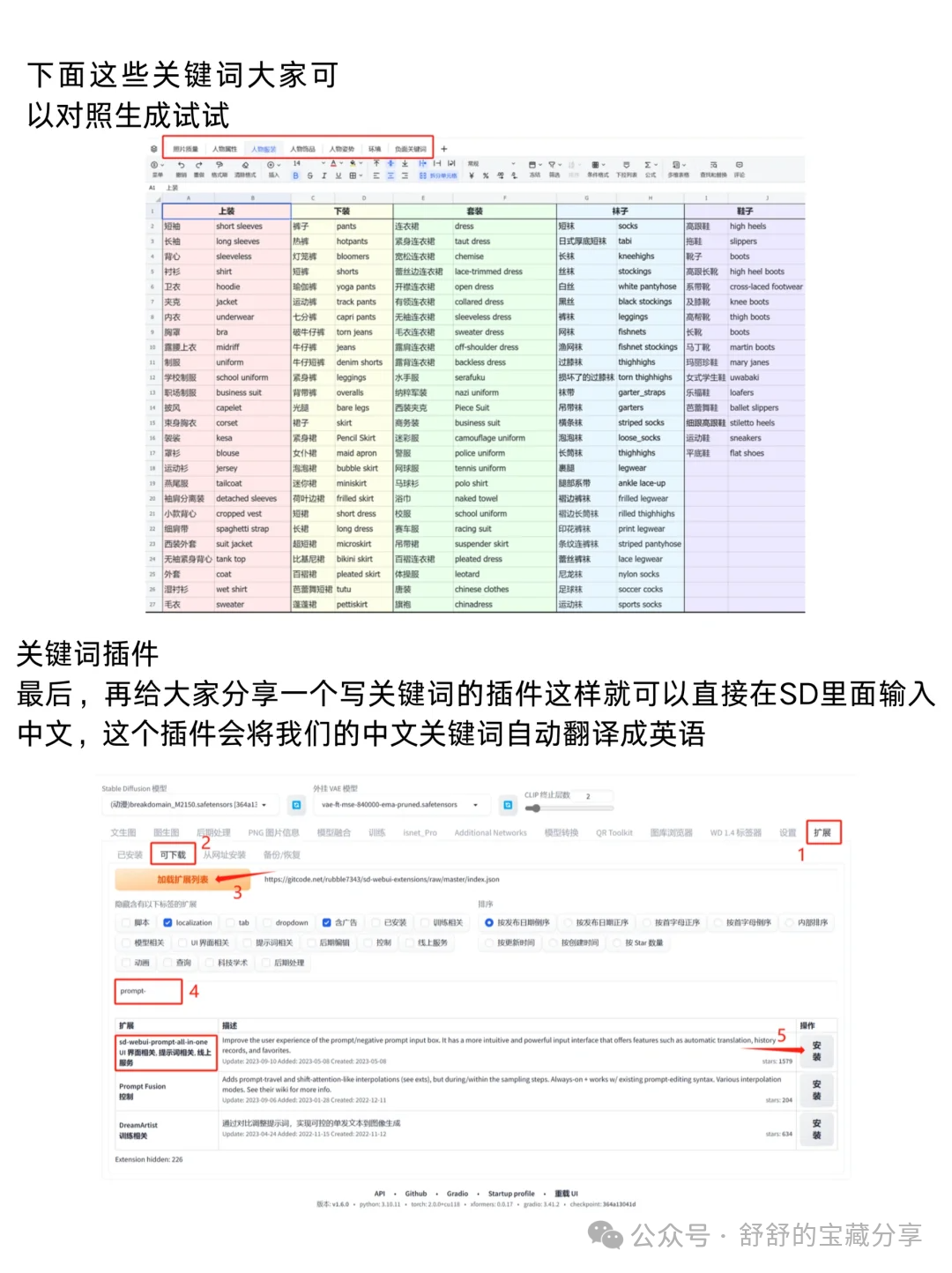
三、模型部分
Checkpoint,VAE,embedding 和 lora 的使用详解

这里分享给大家一份Adobe大神整理的《AIGC全家桶学习笔记》,相信大家会对AIGC有着更深入、更系统的理解。
有需要的朋友,可以点击下方免费领取!

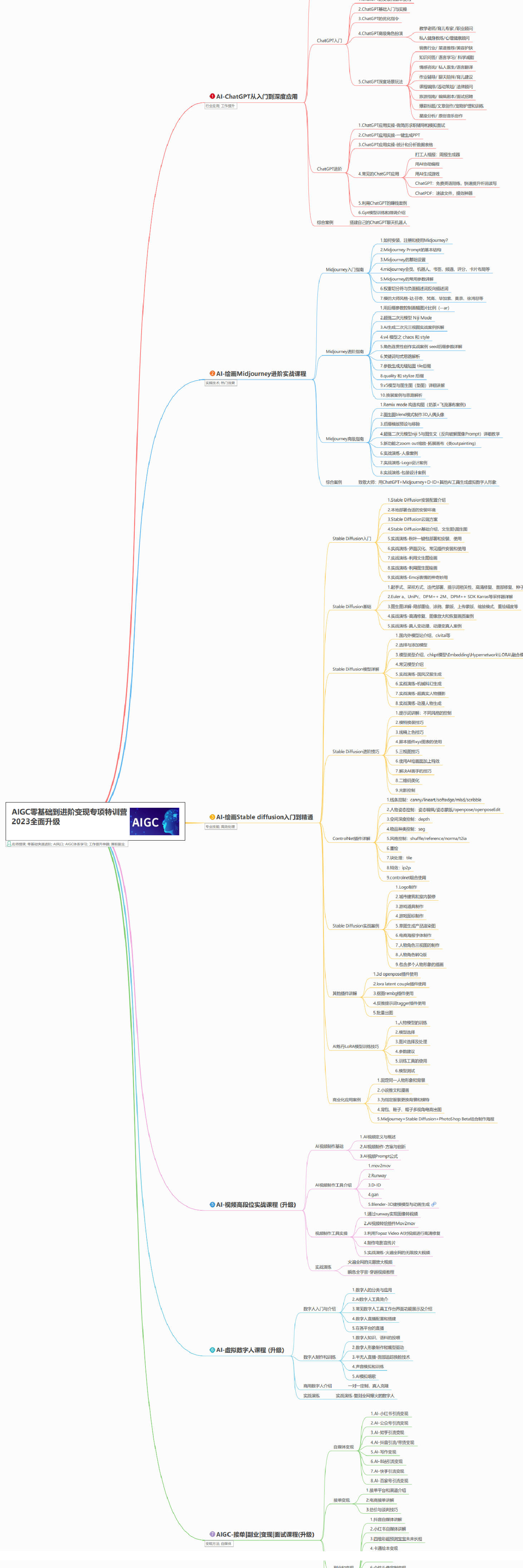
AIGC所有方向的学习路线思维导图
这里为大家提供了总的路线图。它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。如果下面这个学习路线能帮助大家将AI利用到自身工作上去,那么我的使命也就完成了:
AIGC工具库
AIGC工具库是一个利用人工智能技术来生成应用程序的代码和内容的工具集合,通过使用AIGC工具库,能更加快速,准确的辅助我们学习AIGC

有需要的朋友,可以点击下方卡片免费领取!

精品AIGC学习书籍手册
书籍阅读永不过时,阅读AIGC经典书籍可以帮助读者提高技术水平,开拓视野,掌握核心技术,提高解决问题的能力,同时也可以借鉴他人的经验,结合自身案例融会贯通。
AI绘画视频合集
我们在学习的时候,往往书籍源码难以理解,阅读困难,这时候视频教程教程是就很适合了,生动形象加上案例实战,科学有趣才能更方便的学习下去。
















 1304
1304

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









