







一、PCA简介
1. 相关背景
主成分分析(Principal Component Analysis,PCA), 是一种统计方法。通过正交变换将一组可能存在相关性的变量转换为一组线性不相关的变量,转换后的这组变量叫主成分。
上完陈恩红老师的《机器学习与知识发现》和季海波老师的《矩阵代数》两门课之后,颇有体会。最近在做主成分分析和奇异值分解方面的项目,所以记录一下心得体会。
在许多领域的研究与应用中,往往需要对反映事物的多个变量进行大量的观测,收集大量数据以便进行分析寻找规律。多变量大样本无疑会为研究和应用提供了丰富的信息,但也在一定程度上增加了数据采集的工作量,更重要的是在多数情况下,许多变量之间可能存在相关性,从而增加了问题分析的复杂性,同时对分析带来不便。如果分别对每个指标进行分析,分析往往是孤立的,而不是综合的。盲目减少指标会损失很多信息,容易产生错误的结论。
因此需要找到一个合理的方法,在减少需要分析的指标同时,尽量减少原指标包含信息的损失,以达到对所收集数据进行全面分析的目的。由于各变量间存在一定的相关关系,因此有可能用较少的综合指标分别综合存在于各变量中的各类信息。主成分分析与因子分析就属于这类降维的方法。
2. 问题描述
下表1是某些学生的语文、数学、物理、化学成绩统计:
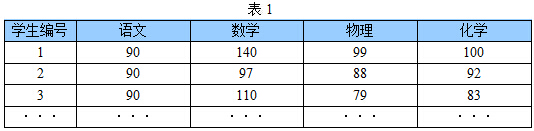
首先,假设这些科目成绩不相关,也就是说某一科目考多少分与其他科目没有关系。那么一眼就能看出来,数学、物理、化学这三门课的成绩构成了这组数据的主成分(很显然,数学作为第一主成分,因为数学成绩拉的最开)。为什么一眼能看出来?因为坐标轴选对了!下面再看一组学生的数学、物理、化学、语文、历史、英语成绩统计,见表2,还能不能一眼看出来:
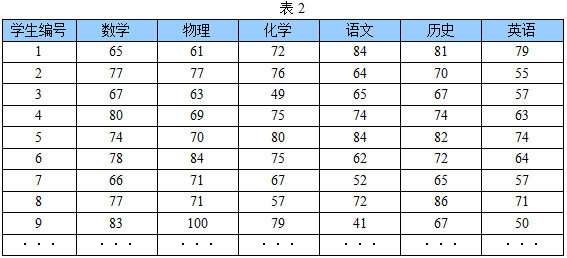
数据太多了,以至于看起来有些凌乱!也就是说,无法直接看出这组数据的主成分,因为在坐标系下这组数据分布的很散乱。究其原因,是因为无法拨开遮住肉眼的迷雾~如果把这些数据在相应的空间中表示出来,也许你就能换一个观察角度找出主成分。如下图1所示:
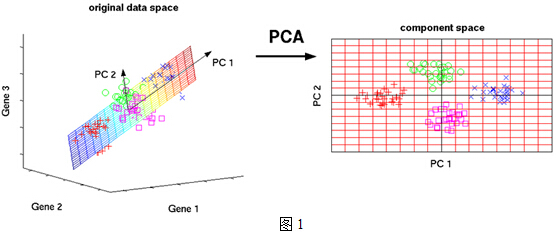
但是,对于更高维的数据,能想象其分布吗?就算能描述分布,如何精确地找到这些主成分的轴?如何衡量你提取的主成分到底占了整个数据的多少信息?所以,我们就要用到主成分分析的处理方法。
3. 数据降维
为了说明什么是数据的主成分,先从数据降维说起。数据降维是怎么回事儿?假设三维空间中有一系列点,这些点分布在一个过原点的斜面上,如果你用自然坐标系x,y,z这三个轴来表示这组数据的话,需要使用三个维度,而事实上,这些点的分布仅仅是在一个二维的平面上,那么,问题出在哪里?如果你再仔细想想,能不能把x,y,z坐标系旋转一下,使数据所在平面与x,y平面重合?这就对了!如果把旋转后的坐标系记为x’,y’,z’,那么这组数据的表示只用x’和y’两个维度表示即可!当然了,如果想恢复原来的表示方式,那就得把这两个坐标之间的变换矩阵存下来。这样就能把数据维度降下来了!但是,我们要看到这个过程的本质,如果把这些数据按行或者按列排成一个矩阵,那么这个矩阵的秩就是2!这些数据之间是有相关性的,这些数据构成的过原点的向量的最大线性无关组包含2个向量,这就是为什么一开始就假设平面过原点的原因!那么如果平面不过原点呢?这就是数据中心化的缘故!将坐标原点平移到数据中心,这样原本不相关的数据在这个新坐标系中就有相关性了!有趣的是,三点一定共面,也就是说三维空间中任意三点中心化后都是线性相关的,一般来讲n维空间中的n个点一定能在一个n-1维子空间中分析!
上一段文字中,认为把数据降维后并没有丢弃任何东西,因为这些数据在平面以外的第三个维度的分量都为0。现在,假设这些数据在z’轴有一个很小的抖动,那么我们仍然用上述的二维表示这些数据,理由是我们可以认为这两个轴的信息是数据的主成分,而这些信息对于我们的分析已经足够了,z’轴上的抖动很有可能是噪声,也就是说本来这组数据是有相关性的,噪声的引入,导致了数据不完全相关,但是,这些数据在z’轴上的分布与原点构成的夹角非常小,也就是说在z’轴上有很大的相关性,综合这些考虑,就可以认为数据在x’,y’ 轴上的投影构成了数据的主成分!
课堂上老师谈到的特征选择的问题,其实就是要剔除的特征主要是和类标签无关的特征。而这里的特征很多是和类标签有关的,但里面存在噪声或者冗余。在这种情况下,需要一种特征降维的方法来减少特征数,减少噪音和冗余,减少过度拟合的可能性。
PCA的思想是将n维特征映射到k维上(k<n),这k维是全新的正交特征。这k维特征称为主成分,是重新构造出来的k维特征,而不是简单地从n维特征中去除其余n-k维特征。
基本步骤:
- 对数据进行归一化处理(代码中并非这么做的,而是直接减去均值)
- 计算归一化后的数据集的协方差矩阵
- 计算协方差矩阵的特征值和特征向量
- 保留最重要的k个特征(通常k要小于n),也可以自己制定,也可以选择一个阈值,然后通过前k个特征值之和减去后面n-k个特征值之和大于这个阈值,则选择这个k
- 找出k个特征值对应的特征向量
- 将m * n的数据集乘以k个n维的特征向量的特征向量(n * k),得到最后降维的数据。
二、PCA实例
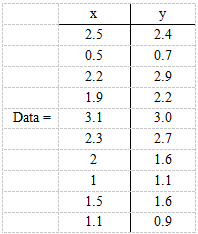
现在假设有一组数据如下:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1219
1219











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









