







安装Ollama
下载安装程序。
https://ollama.com/download
下载后,得到如下安装文件。
OllamaSetup.exe
运行安装程序。
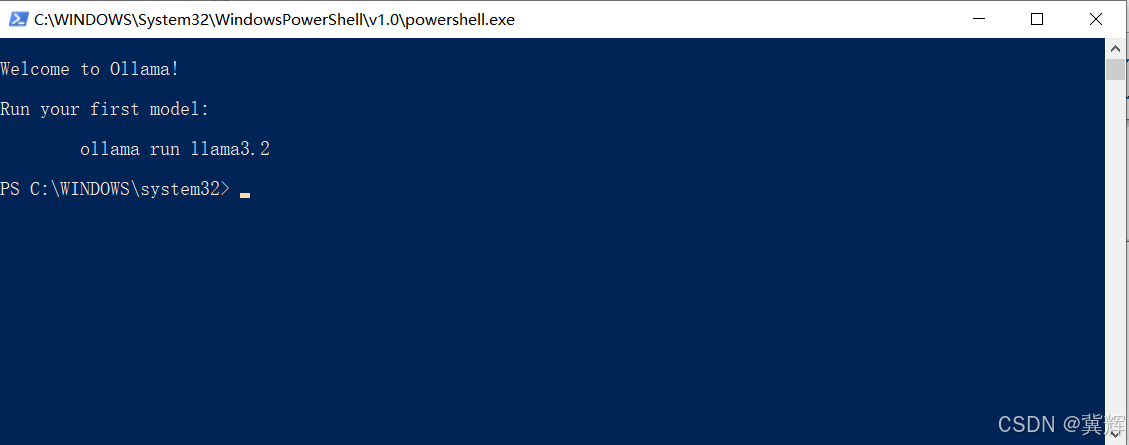
安装的一些信息,可以从下面的路径查找。
C:\Users\jihui\AppData\Local\Programs\Ollama
这是安装时,使用的主机信息,使用了11434端口。
OLLAMA_HOST:http://127.0.0.1:11434
安装QWen2.5
ollama run qwen2.5:1.5b
大约10分钟后
我们可以直接输入信息,大模型进行回复。
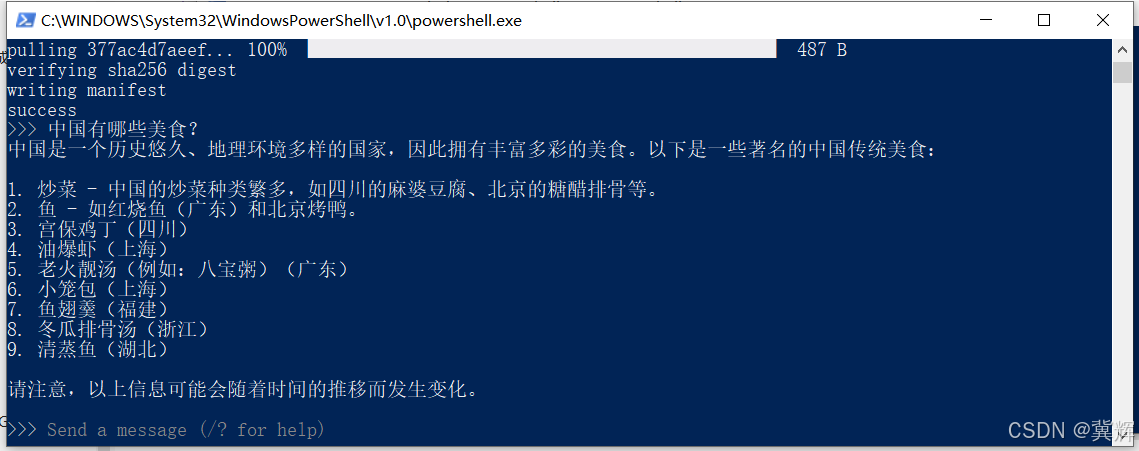
至此,大模型已经安装完成。
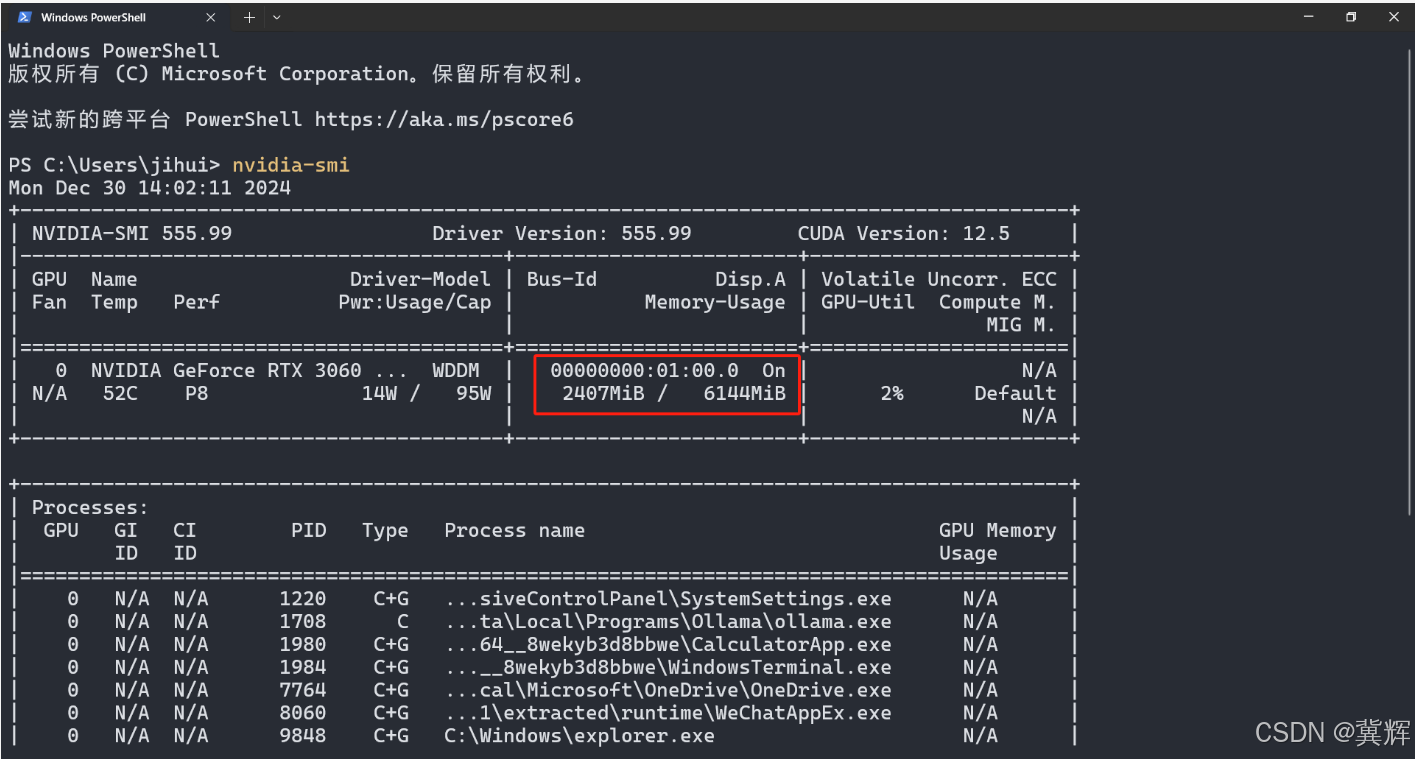
安装使用的为6G显存的3090,安装后,只使用了2.4G。使用游戏笔记本电脑,完全可以部署一个大模型,供本地学习。
如何进行代码访问
准备虚拟环境
(ollama) C:\Users\jihui>pip list
Package Version
----------------- -----------
annotated-types 0.7.0
anyio 4.6.2.post1
certifi 2024.8.30
colorama 0.4.6
distro 1.9.0
exceptiongroup 1.2.2
h11 0.14.0
httpcore 1.0.7
httpx 0.27.2
idna 3.10
jiter 0.8.2
ollama 0.4.2
openai 1.58.1
pip 24.2
pydantic 2.10.3
pydantic_core 2.27.1
setuptools 75.1.0
sniffio 1.3.1
tqdm 4.67.1
typing_extensions 4.12.2
wheel 0.44.0
(ollama) C:\Users\jihui>
编写代码
from openai import OpenAI
openai_api_key = "EMPTY"
openai_api_base = "http://127.0.0.1:11434/v1"
client = OpenAI(api_key=openai_api_key,
base_url=openai_api_base)
models = client.models.list()
print(models)
# C:\anaconda3\envs\ollama\python.exe C:/Code/ollama/demo_qwen_with_ollama.py
# SyncPage[Model](data=[Model(id='qwen2.5:1.5b', created=1735538296, object='model', owned_by='library')], object='list')
#
# Process finished with exit code 0
model = "qwen2.5:1.5b"
role = "You are a helpful assistant"
query = "234加上567的和是多少?"
temperature = 0.7
chat_completion = client.chat.completions.create(
model=model,
messages=[
{
"role": "system", "content": role
},
{
"role": "user", "content": query
}
],
temperature=temperature
)
content = chat_completion.choices[0].message.content
print(content)
# C:\anaconda3\envs\ollama\python.exe C:/Code/ollama/demo_qwen_with_ollama.py
# SyncPage[Model](data=[Model(id='qwen2.5:1.5b', created=1735538296, object='model', owned_by='library')], object='list')
# 234加上567的和是801。
#
# Process finished with exit code 0
关于模型名称
可以使用ollama list获取。
(ollama) C:\Users\jihui>ollama list
NAME ID SIZE MODIFIED
qwen2.5:1.5b 65ec06548149 986 MB 39 minutes ago
(ollama) C:\Users\jihui>
或者使用openai的客户端
models = client.models.list()
print(models)
输出的模型信息中,包含可用的模型名称。
C:\anaconda3\envs\ollama\python.exe C:/Code/ollama/demo_qwen_with_ollama.py
SyncPage[Model](data=[Model(id='qwen2.5:1.5b', created=1735538296, object='model', owned_by='library')], object='list')
Process finished with exit code 0
好了,可以开启你的大模型开发之旅了。
ollama常用命令
PS C:\Users\jihui> ollama
Usage:
ollama [flags]
ollama [command]
Available Commands:
serve Start ollama
create Create a model from a Modelfile
show Show information for a model
run Run a model
stop Stop a running model
pull Pull a model from a registry
push Push a model to a registry
list List models
ps List running models
cp Copy a model
rm Remove a model
help Help about any command
Flags:
-h, --help help for ollama
-v, --version Show version information
Use "ollama [command] --help" for more information about a command.
PS C:\Users\jihui> ollama ps
NAME ID SIZE PROCESSOR UNTIL
PS C:\Users\jihui> ollama list
NAME ID SIZE MODIFIED
qwen2.5:1.5b 65ec06548149 986 MB 10 minutes ago
PS C:\Users\jihui>

















 13万+
13万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









