







1 前言
在之前的基础介绍中我们已经从谱图理论过渡到图傅里叶变换再到图卷积,那么在这一小节中我们根据图卷积的定义介绍几种基础的图卷积的模型。
此文内容为自学内容的笔记,其中多有参考借鉴他人博客的地方,一并在参考文献中给出链接。
【图机器学习】图神经网络入门(一)谱图理论
【图机器学习】图神经网络入门(二)图上的傅里叶变换
【图机器学习】图神经网络入门(三)从图傅里叶变换到图卷积
【图机器学习入门】拉普拉斯算子与拉普拉斯矩阵的关系
2 GCN的演进
将CNNs推广到图需要三个基本步骤:
(i)设计图的局部卷积滤波器;
(ii)将相似的顶点和顶点组合在一起的图粗化过程
(iii)一种图形池操作,用空间分辨率换取更高的滤波器分辨率(filter resolution)
在之前图卷积模型的推导中已经得到了一般的图卷积公式:
x
⋆
G
g
θ
=
U
(
g
^
(
λ
1
)
⋱
g
^
(
λ
n
)
)
(
f
^
(
λ
1
)
f
^
(
λ
2
)
⋮
f
^
(
λ
n
)
)
=
U
(
g
^
(
λ
1
)
⋱
g
^
(
λ
n
)
)
U
T
f
\mathrm{x} \star_{\mathrm{G}} \mathrm{g}_{\theta}=\mathrm{U}\left(\begin{array}{ccc} \hat{\mathrm{g}}\left(\lambda_{1}\right) & & \\ & \ddots & \\ & & \hat{\mathrm{g}}\left(\lambda_{\mathrm{n}}\right) \end{array}\right)\left(\begin{array}{c} \hat{\mathrm{f}}\left(\lambda_{1}\right) \\ \hat{\mathrm{f}}\left(\lambda_{2}\right) \\ \vdots \\ \hat{\mathrm{f}}\left(\lambda_{\mathrm{n}}\right) \end{array}\right)\\[10mm] =\mathrm{U}\left(\begin{array}{ccc} \hat{\mathrm{g}}\left(\lambda_{1}\right) & & \\ & \ddots & \\ & & \hat{\mathrm{g}}\left(\lambda_{\mathrm{n}}\right) \end{array}\right) \mathrm{U}^{\mathrm{T}} \mathrm{f}
x⋆Ggθ=U
g^(λ1)⋱g^(λn)
f^(λ1)f^(λ2)⋮f^(λn)
=U
g^(λ1)⋱g^(λn)
UTf
上面公式推导的结果就是谱域图卷积最终的公式,所有的谱域图卷积的原理就是这个公式,只是对滤波器
g
^
\hat g
g^ 做了不同的处理。这个公式的意义是:卷积核信号(或者说滤波器信号
g
^
\hat g
g^ 是一个
n
n
n 维的向量,它的作用是将原信号的不同的分量进行一个放大或者缩小,这取决于卷积核信号在谱域上不同元素的值。
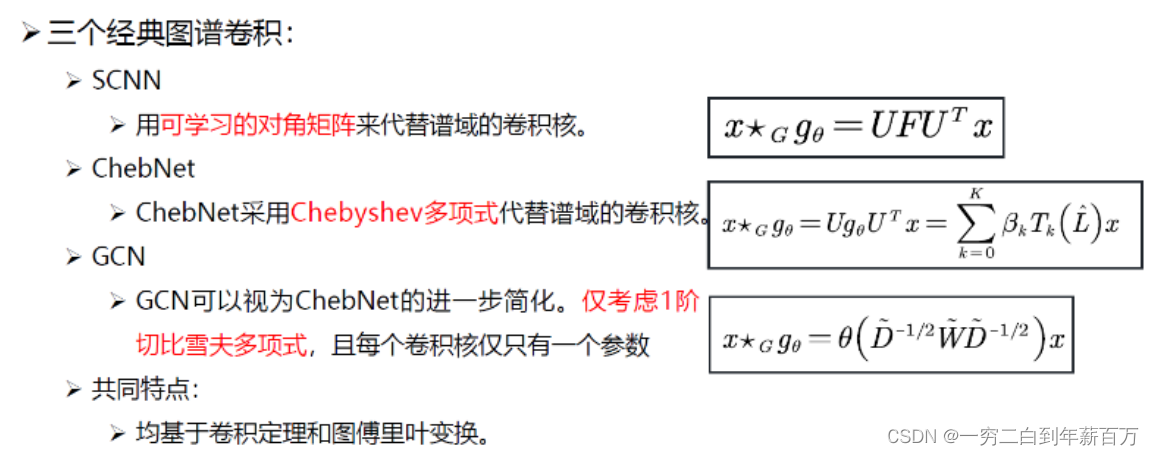
2.1 第一代SCNN模型
详细的论文解读可以看(Spectral Networks and Locally Connected Networks on Graphs)
理解的不太行,以后加更…
2.2 第二代ChebNet模型
核心思想:ChebNet采用Chebyshev(切比雪夫)多项式代替谱域的卷积核!
什么是切比雪夫多项式?如下所示:

上面这个公式就是切比雪夫多项式,公式就是在说,
0
0
0 阶的切比雪夫多项式是
1
1
1,一阶的是
x
x
x,依此类推,高阶的切比雪夫多项式有这样的规律:
T
N
+
1
(
x
)
=
2
x
T
n
(
x
)
−
T
n
−
1
(
x
)
T_{N+1}(x)=2xT_{n}(x)-T_{n-1}(x)
TN+1(x)=2xTn(x)−Tn−1(x),
(
n
=
1
,
2
,
.
.
.
)
( n = 1 , 2 , . . . )
(n=1,2,...)
当我们把
x
x
x 换成矩阵之后,就成了矩阵形式的切比雪夫多项式,如下面,我们把
x
x
x 换成了拉普拉斯矩阵
L
L
L:
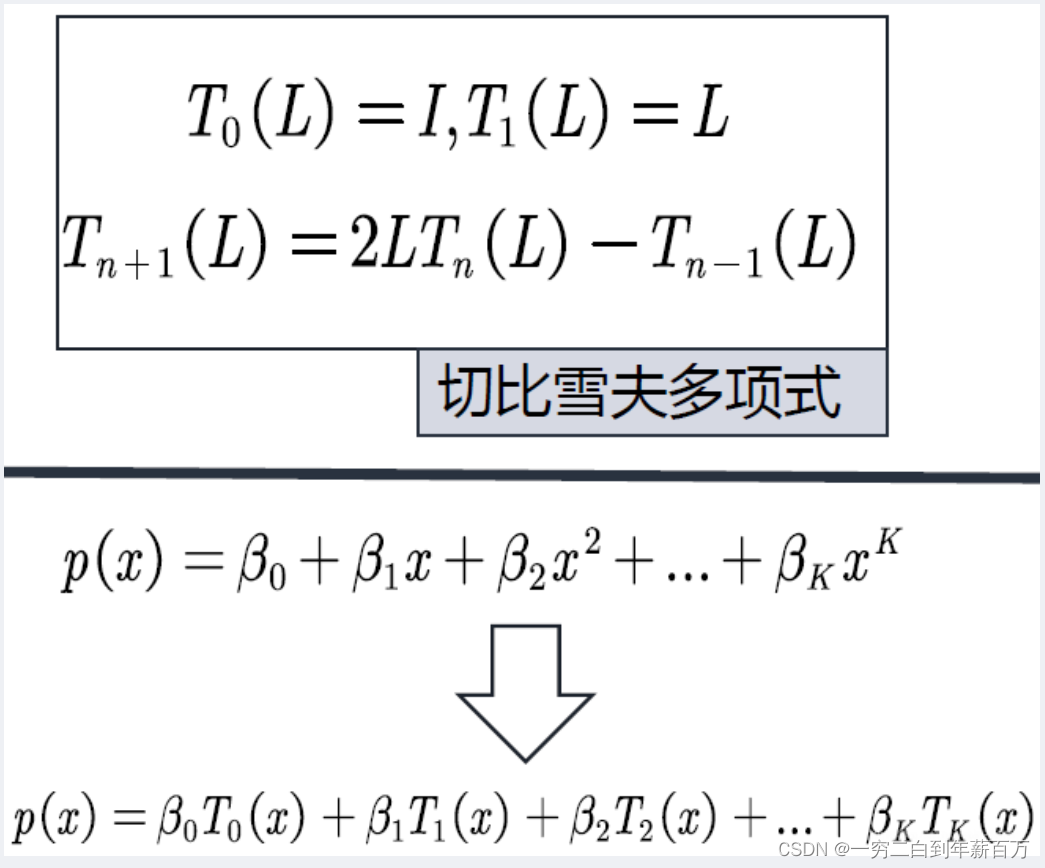
切比雪夫多项式在逼近理论中有重要的应用,因为切比雪夫多项式可以用于多项式插值,相应的插值多项式能最大限度地降低龙格现象,并且提供多项式在连续函数的最佳一致逼近,也就是说我们可以用切比雪夫多项式来逼近函数进行多项式插值。
定义卷积:ChebNet方法认为谱域的卷积核的取值是一个与特征值相关的函数,然后可以用切比雪夫多项式来逼近这个函数,具体来说如下:
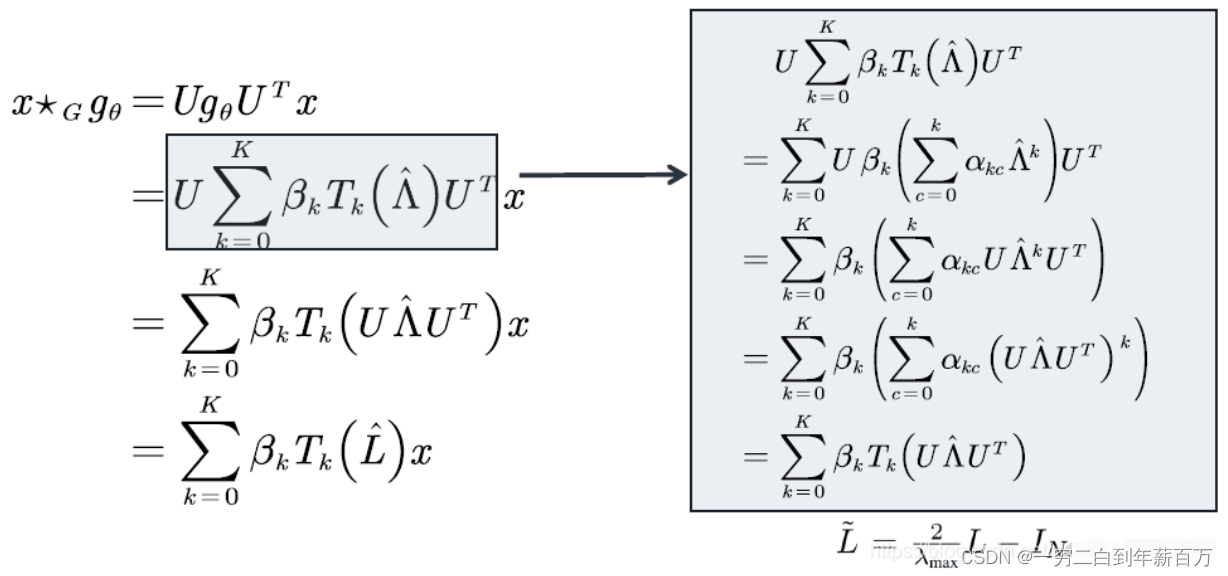
其中
g
θ
g_{\theta}
gθθ是谱域的卷积核,然后用一个切比雪夫多项式插值来逼近它,我们只需要学习前面的系数
β
k
\beta_k
βk 就可以了,然后就能推导出最下面的结果了,显然这样做的好处是:不需要求拉普拉斯矩阵的特征向量
U
U
U,直接使用拉普拉斯矩阵,时间复杂度大大降低。所以下面这个公式就是ChebNet方法的最终公式:
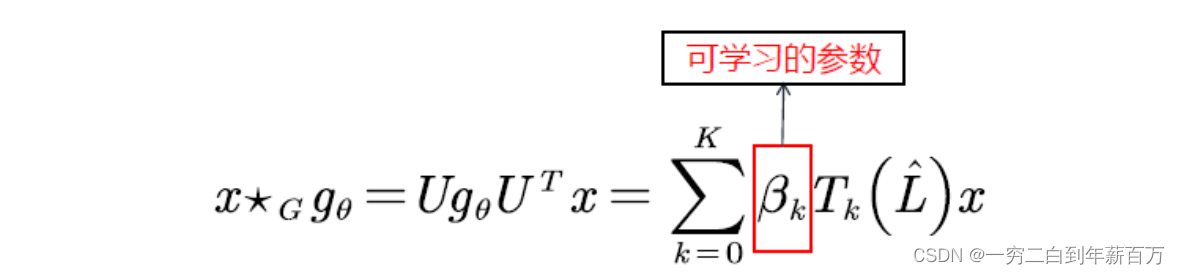
ChebNet 优点:
- 卷积核只有K+1个可学习的参数,一般K远小于n,参数的复杂度被大大降低;
- 采用Chebyshev多项式代替谱域的卷积核后,经过公示推导,ChebNet不需要对拉普拉斯矩阵做特征分解了。省略了最耗时的步骤;
- 卷积核具有严格的空间局部性。同时,K就是卷积核的“感受野半径”。即将中心顶点K阶近邻节点作为邻域节点。
2.3 第三代GCN模型
这就是著名的:SEMI-SUPERVISED CLASSIFICATION WITH GRAPH CONVOLUTIONAL NETWORKS. ICLR 2017论文中的方法。
核心思想:GCN可以视为对ChebNet的进一步简化。仅仅考虑1阶切比雪夫多项式,且每个卷积核仅仅只有一个参数。
定义卷积:因为只考虑了一阶的切比雪夫多项式,因此,可以按如下步骤来化简,具体来说如下:
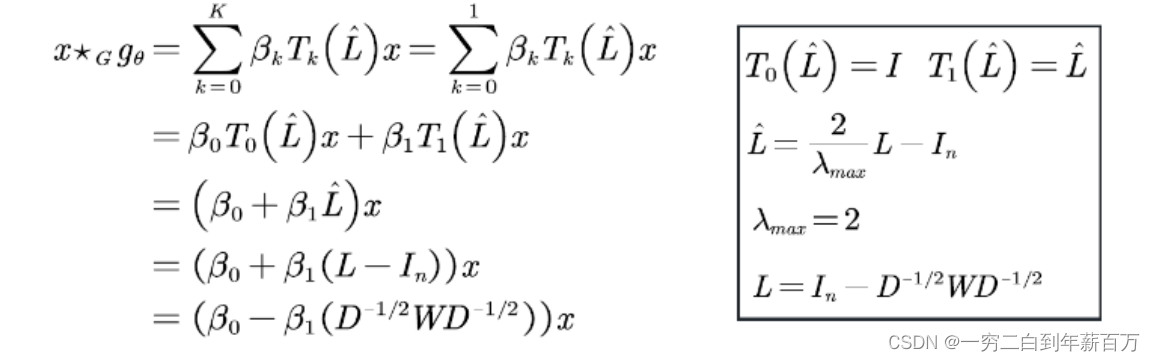
其中
W
W
W 是邻接矩阵;
D
D
D 是度矩阵。


当然,上述公式中是忽略input channel 和output channel,若考虑的话,每个卷积核的参数是input channel 数乘以output channel 数。


3 总结



4 参考文献
[1]如何理解 Graph Convolutional Network(GCN)?
[2]图卷积网络 GCN Graph Convolutional Network(谱域GCN)的理解和详细推导
[3]图卷积神经网络2-谱域卷积:SCNN/ChebNet/GCN的引入和介绍
[4]图卷积神经网络笔记——第二章:谱域图卷积介绍(2)好文!!!
[5]【图神经网络】GCN-2(ChebyNet)
[6]图网络:从谱域卷积到空域卷积

















 1140
1140

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









