






1、Python与Anaconda
在想使用Python之前需先安装Python,以及Python IDE和Python的库,而用Anaconda就可以一键安装。
Anaconda包含了 Python,常用的python库以及IDE,还具有强大的环境和python包的管理能力。
Python IDE(Integrated Development Environment,集成开发环境)是一个为开发者提供了编程所需的各种工具的软件应用。一个Python IDE通常包括代码编辑器、调试器和构建工具,有时还会集成版本控制、代码分析和图形用户界面(GUI)编辑器等工具。使用IDE可以帮助开发者提高编程效率,更有效地编写、测试和调试代码。
在Python语言的库中,分为Python标准库和Python的第三方库
● 标准库:会随着Python安装自动安装(Scrapy,Numpy,matplatlib)
● 第三方库:需要单独下载再安装
2、Anaconda的下载和安装
方法一:
https://mirrors.tuna.tsinghua.edu.cn/(清华镜像站)
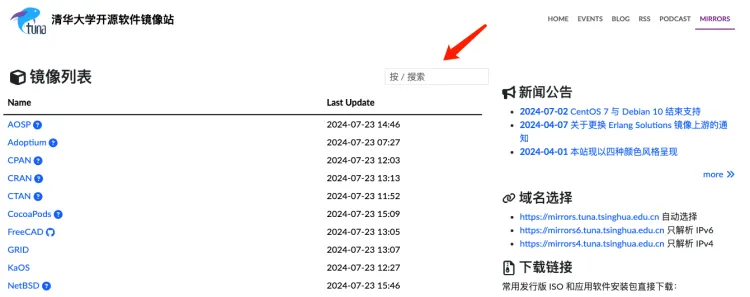
在搜索框中输入anaconda
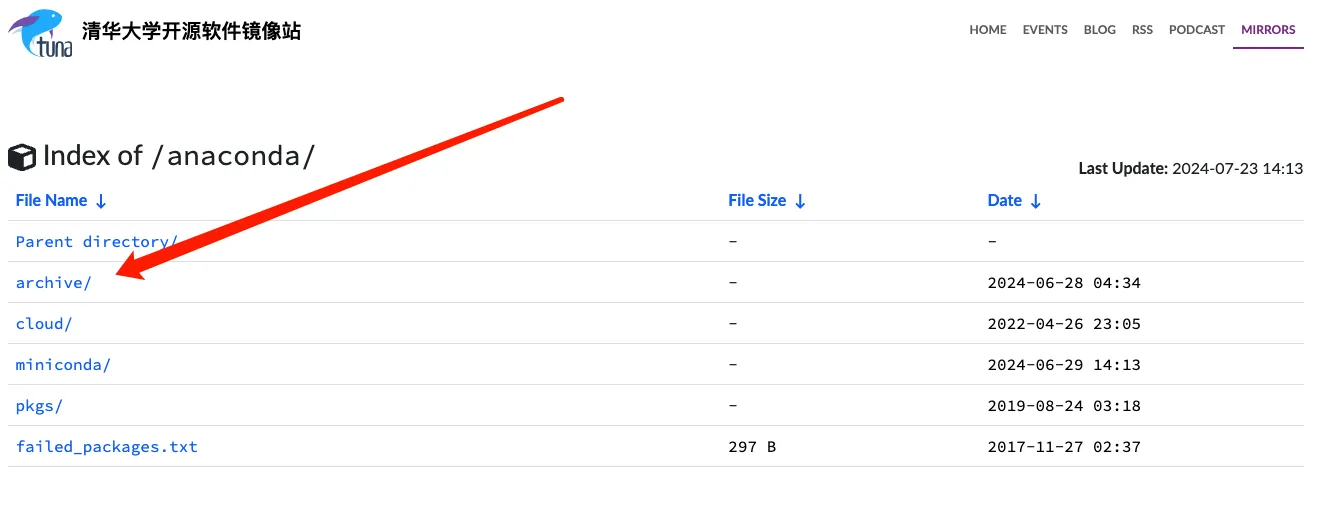
点击archive
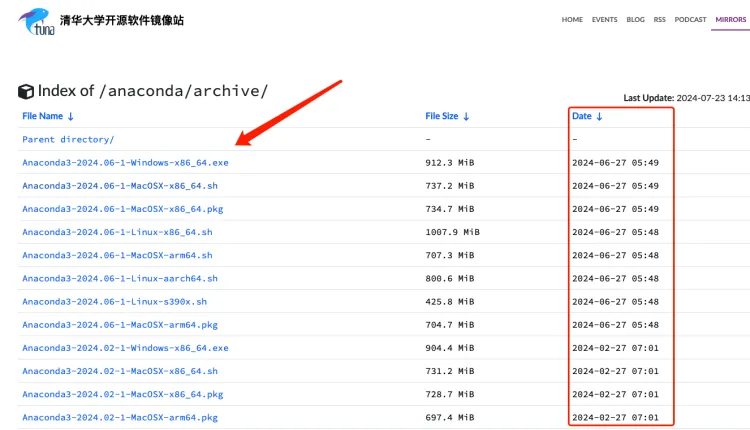
点击Date进行排序,安装适配电脑系统的最新版本的anaconda
方法二:
Anaconda官网下载: https://www.anaconda.com/download
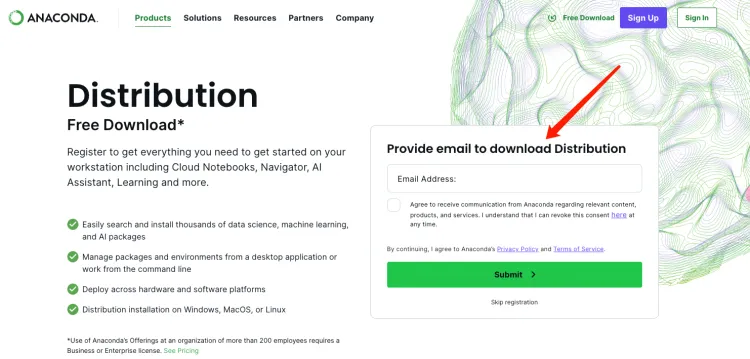
输入邮箱之后点击邮箱中的链接进去下载页面
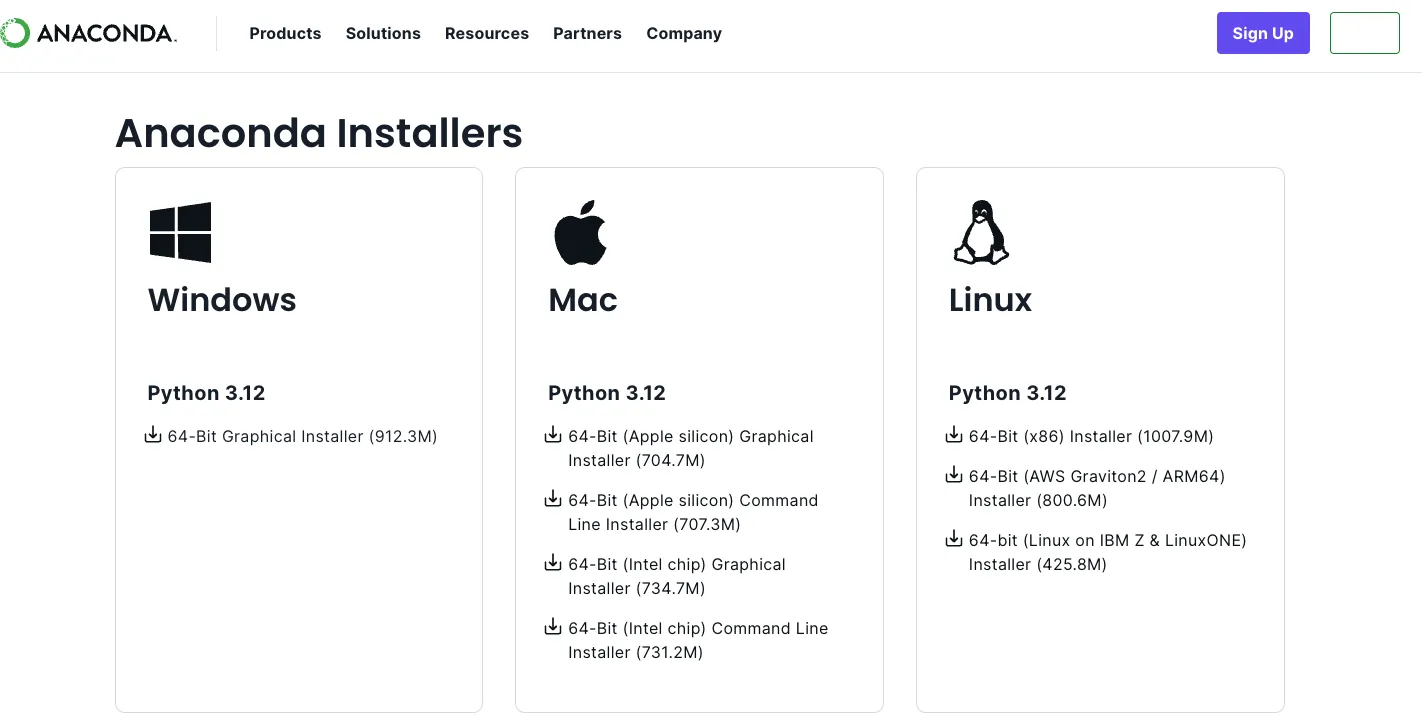
安装适配电脑系统的anaconda

在终端中确认是否安装了python,若没有需安装python(不展示了)。
3、Spyder的使用

Spyder是用于科学计算的集成开发环境(IDE),用Python编程语言编写并用于Python编程语言。它附带了一个编辑器来编写代码,一个控制台来评估它并随时查看结果,一个变量资源管理器来检查在评估过程中定义的变量(这个软件就类似于R studio了)。

运行Anaconda——点击Spyder
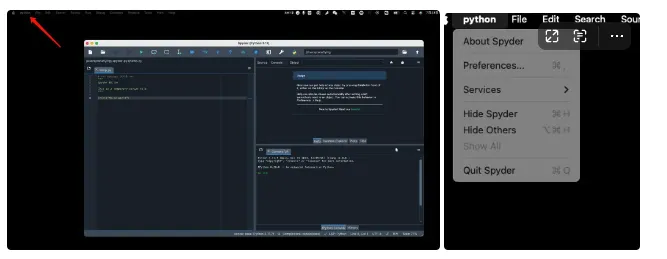
先修改Spyder中的默认语言,从左上角的python中的preference进去
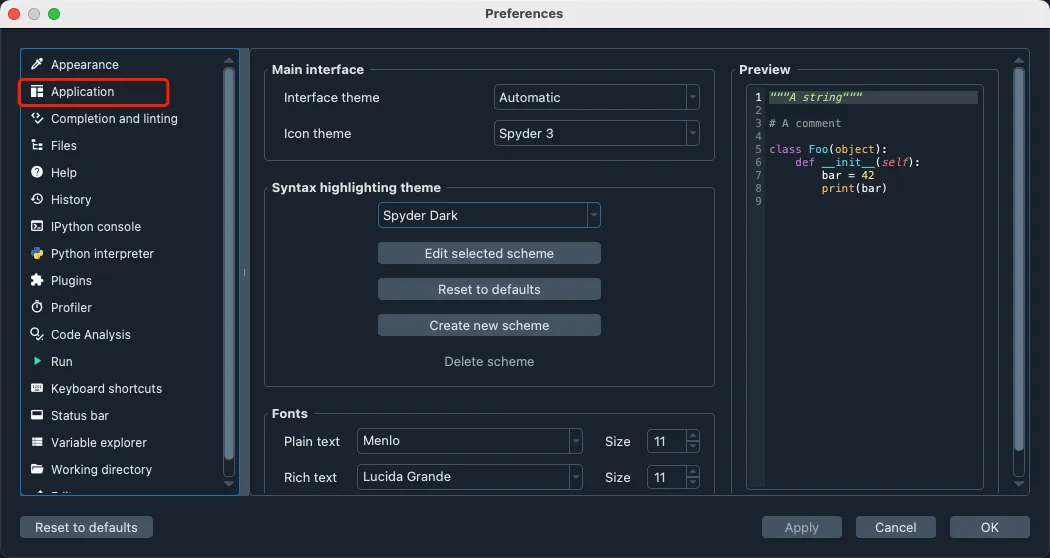
点击Application

点击Adcanced settings 修改语言
建议再修改一下背景颜色、字体大小
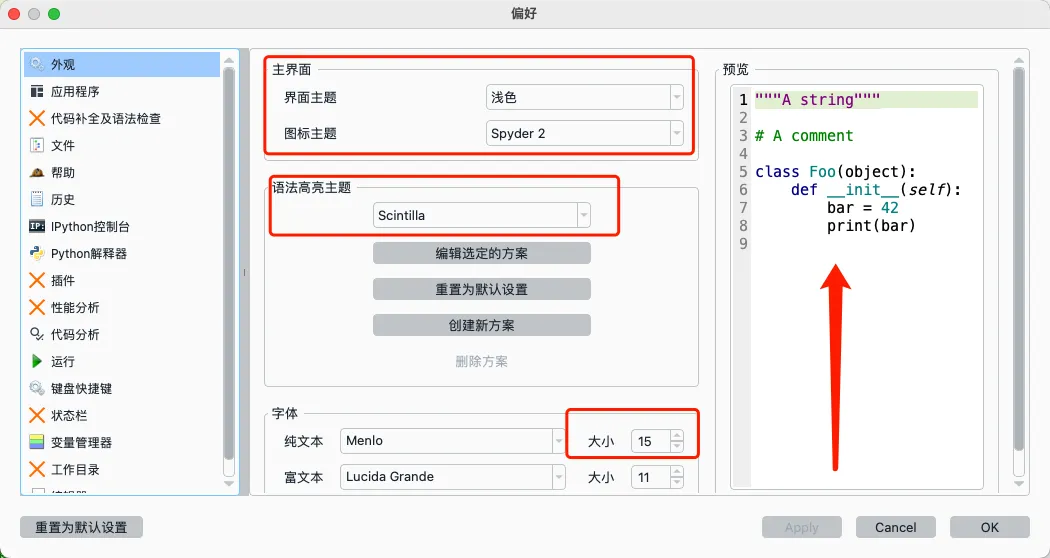
进入外观模块修改参数。
4、Python中的数据类型
在正式演示之前还需了解一些必备的小知识。
首先是 #%%,这个用于分割代码,划分之后的代码变成代码单元格,这样就可以以单独的单元格模式运行。
快捷键"control+enter"用于运行代码单元格/全部代码。
快捷键"cmd+1"用于对python多行代码全部进行“#”注释
1)数字 :分为整型int,浮点型float和布尔型bool
整型int,没有小数点的正负整数,比如年龄、心跳等。
浮点型float,由整数和小数部分组成,比如体温,基因表达量等。
布尔型bool,布尔类型在python中是当做整数对待。 True相当于整数1,False相当于整数0。
#%%
########################
# 数字
# 1、整型
print(6666666)
print(-666)
print(0)
# 2、浮点型
print(3.1415926)
print(-3.5e-14)
# 3、布尔类型
print(True,False)
print(3>6)
该代码单元格运行之后会在控制台中出现如下结果(后续将简化展示)。

2)字符串string
这个跟R语言中的很相似都是单引号或者双引号括起来的任意文本。
如果字符串内容中出现了引号,比如单引号那么外边的引号必须是双引号。
其中有几个特殊的组合,\n 代表换行符号,\r 代表光标移动到一行的开始, \ 代表反斜杠。
python还允许用r放在字符串前面防止字符转义。
三引号还允许一个字符串跨多行。
#%%
######################
# 字符串
# 1、含有引号的字符串
print("Hello world")
print("I'm jack")
# Hello world
# I'm jack
# 2、不转义字符串
print("I\'m \"OK\"")
print(r"I\'m \"OK\"")
#I'm "OK"
#I\'m \"OK\"
# 跨行符号
print("aaa\nbbb")
print('''aaa
bbb''')
# aaa
# bbb
# aaa
# bbb
3)变量赋值
这一块内容与R语言中的赋值十分相似。 python中用等号(=)来给变量赋值。
变量赋值不需要类型声明,它的类型由值决定,可以用type(name)查看数据类型。 每个变量在使用前均需赋值,变量赋值以后该变量才会被创建。
不同的赋值方法: 变量1 = 变量2 = 变量3 = 值 变量1,变量2,变量3 = 值1,值2,值3
变量名:不能以数字开头,变量名要区分大小写,建议变量名需要有一定含义,变量名中若含有多个单词,建议使用小写下划线命名,不能与一些特殊名字重名。
#%%
#######################
# 变量赋值
age = 28
age1 = 23
print(age,age1)
# 28 23
# 查看变量类型
print(type(age))
# <class 'int'>
# 多个变量赋值
name1 = name2 = name3 = "Alice"
print(name1,name2,name3)
# Alice Alice Alice
name4,name5,name6 = "Alice","Bob","Jack"
print(name4,name5,name6)
#Alice Bob Jack
4)运算符
算术运算符:
+,-,*,/ , 加减乘除。其中除法(/)的计算结果总是浮点数,不管能否除尽,也不管参与运算的是整数还是浮点数。 其他运算符号当有浮点数参与运算时,结果才为浮点数,否则为整数。 // 双斜杠代表整除。 % 取余,即返回除法的余数 ** 幂运算/次方运算,即返回x的y次方
赋值运算符:
+=,-=,*=,/=,%=,**=,//= ,这些符号代表先进行左边的运算,再进行赋值。
#%%
#######################
# 运算符
data1 = 10
data2 = 2
data3 = 7.0
print(data1+data2)
print(data1/data2)
print(data1//data2)
print(data1 % data3)
print(data1**data3)
# 赋值运算符
data2 += data1
print(data2)
data2 /= data1
print(data2)
data2 %= data1
print(data2)
data2 **= data1
print(data2)
data2 //= data1
print(data2)
# 比较运算符
print(data1 == data2)
print(data1 != data2)
# 12
# 5.0
# 5
# 3.0
# 10000000.0
# 12
# 1.2
# 1.2
# 6.191736422399997
# 0.0
# False
# True
赋值过程中需要变量本身参与运算,如果变量没有提前定义,它的值就是未知的,无法参与运算就会报错。
5)列表list
创建及赋值变量:
列表采用[]标识,相邻元素间用逗号分隔。列表中的元素个数没有限制。
元素数据类型只要Python支持的数据类型就可以,可以将列表赋值给变量。
列表的位置索引:
列表中单个元素的访问也与R语言中类似,但是索引位置是从0开始,而R语言中是从1开始。
索引从0开始,最大取n-1,比如TCGA[2:5],这就代表提取TCGA这个列表中的第3至第5个数据(这里要仔细捋一捋,跟R语言不一样)。
如果使用冒号的话,结果会不一样,比如 TCGA[:5],从列表的首元素开始至列表的第6个元素。比如 TCGA[5:], 从列表的第6个元素开始至列表最后的元素,这里就不会是n-1了。
替换列表中元素:
TCGA[2] = "CD6666", 对第三位的元素内容进行替换。
添加新元素进列表:
TCGA.append("CD6666888"), 直接添加元素至末尾。TCGA.insert(2,"CD99"), 将元素插入指定索引位置,比如将元素插入列表的第三个位置。
删除列表元素:
TCGA.pop(), 不添加元素就是直接删除末尾元素。TCGA.pop(1), 删除索引位置元素。
# %%
####################
# 列表
# 1、列表创建
TCGA_HNSC = ["TP53",53,"CDK4",23,"CD168",201]
# 2、数据访问
print(TCGA_HNSC[0])
# 3、截取列表
print(TCGA_HNSC[1:3]) #请注意这里的终止位置的值不会包含在输入的结果里面
print(TCGA_HNSC[2:]) #由于采用了冒号,这里后面没有加位置值时代表把后面所有的结果展示出来
# 4、替换列表内容
TCGA_HNSC[3] = "2024"
print(TCGA_HNSC)
# 5、添加列表元素
TCGA_HNSC.append("CD44")
print(TCGA_HNSC)
# 6、删除列表元素
TCGA_HNSC.pop() #如果括号中都不写,默认删除最后一个元素
print(TCGA_HNSC)
TCGA_HNSC.pop(1)
print(TCGA_HNSC)
# TP53
# [53, 'CDK4']
# ['CDK4', 23, 'CD168', 201]
# ['TP53', 53, 'CDK4', '2024', 'CD168', 201]
# ['TP53', 53, 'CDK4', '2024', 'CD168', 201, 'CD44']
# ['TP53', 53, 'CDK4', '2024', 'CD168', 201]
# ['TP53', 'CDK4', '2024', 'CD168', 201]
6)元组tuple
元组采用()标识,与列表类似,但不可修改。一旦使用就不能修改了,没有append(),insert()这样的方法,不能赋值成另外的元素。索引位置的使用方式是与列表一样。
#%%
#################
# 元组
# 1、创建元组
TCGA = ("TP53",53,"CDK4",23,"CD168",201)
print(TCGA)
# 2、访问元组中元素
print(TCGA[0])
# 3、截取元组
print(TCGA[2:5])
print(TCGA[2:])
print(TCGA[:4])
# 4、修改元组元素
TCGA[0] = "P53"
# ('TP53', 53, 'CDK4', 23, 'CD168', 201)
# TP53
# ('CDK4', 23, 'CD168')
# ('CDK4', 23, 'CD168', 201)
# ('TP53', 53, 'CDK4', 23)
# Traceback (most recent call last):
# File /opt/anaconda3/lib/python3.11/site-packages/spyder_kernels/py3compat.py:356 in compat_exec
# exec(code, globals, locals)
# File ~/.spyder-py3/temp.py:142
# TCGA[0] = "P53"
# TypeError: 'tuple' object does not support item assignment
如果需要修改元组中的元素,那么就会报错。
7)字典dict
字典dict使用{}标识,可以存在具有映射关系的数据。比如 {"key" : "value1", "key2" : "value2", "key3" : "value3"}。
key不允许重复,value可以重复,如果用字典里不存在的key名称去访问数据,就会出现报错。
添加修改字典数据:
如果key已经存在则修改它的值;如果key不存在,则新增数据。
删除字典数据:
如果key不存在,则程序报错;dic.clear()删除字典内所有元素。
#%%
#####################
# 字典
# 1、创建字典
dict = {"TP53":"239","CDK4":"228","CD168":"89"}
# 2、访问字典的值
print(dict["TP53"])
# 3、修改字典数据
dict["TP53"] = "23"
print(dict)
# 4、添加字典内容
dict["PTEN"] = "888"
print(dict)
# 5、删除数据
dict.pop("PTEN")
print(dict)
dict.clear()
print(dict)
# 239
# {'TP53': '23', 'CDK4': '228', 'CD168': '89'}
# {'TP53': '23', 'CDK4': '228', 'CD168': '89', 'PTEN': '888'}
# {'TP53': '23', 'CDK4': '228', 'CD168': '89'}
# {}
8)集合set
集合是一组无序且不重复元素的集合。可以用大括号{}或set()函数创建集合,如果创建空集合,则必须用set()函数。
集合是一个无序且不重复的元素序列,所以要使用in或者not in判断某个元素是否存在于集合中,返回True或者False。
添加删除元素:
添加为集合后面增加.add(“key”),如果元素已经存在,则不进行任何操作;删除为集合后面增加.remove(“key”);全部删除中所有元素为集合后增加.clear()
集合运算:
并集运算 c1 | c2, 交集运算 c1 & c2,补集运算 c1 - c2。 判断集合是否相等: c1 == c2;判断集合是否不同: c1 != c2;判断集合是否为子集 c1 < c2; 判断集合是否为超集 c1 > c2。
#%%
##################
# 集合
# 1、创建集合
c1 = {1,2,3,4,5,6,7,8}
c2 = set([2,2,2,4,5,6]) # seth函数能够让数据不重复
print(c2)
# 2、集合元素的判断
print( 1 in c1)
print( 2 not in c2)
# 3、添加和删除元素
c1.add(2)
print(c1)
c1.add(10)
print(c1)
c1.remove(7)
print(c1)
c1.clear()
print(c1)
# 4、集合运算
c3 = c1 & c2 # 交集
print(c3,c2,c1)
c4 = c1 | c2 # 并集
print(c4,c2,c1)
c5 = c1 - c2 # 左边集合去重右边集合之后剩下的相同元素
print(c5,c2,c1)
c6 = c2 - c1 # 左边集合去重右边集合之后剩下的相同元素
print(c6,c2,c1)
print(c2 == c1) # 双等号判断集合是否相等
print(c1 < c2) # 判断c1是否是c2的子集
print(c1 > c2) # 判断c1是否是c2的超集
# {2, 4, 5, 6}
# True
# False
# {1, 2, 3, 4, 5, 6, 7, 8}
# {1, 2, 3, 4, 5, 6, 7, 8, 10}
# {1, 2, 3, 4, 5, 6, 8, 10}
# set()
# set() {2, 4, 5, 6} set()
# {2, 4, 5, 6} {2, 4, 5, 6} set()
# set() {2, 4, 5, 6} set()
# {2, 4, 5, 6} {2, 4, 5, 6} set()
# False
# True
# False
注:若对内容有疑惑或者有发现明确错误的朋友,请联系后台(欢迎交流)。更多内容可关注公众号:生信方舟
- END -















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









