









MapReduce之简单K-mer计数
什么是K-mer计数
K-mer是一个长度为 K ( K > 0 ) K(K>0) K(K>0)的子串,K-mer计数是指整个序列中K-mer出现的频度
K-mer计数应用
DNA序列中的K-mer计数在和多生物信息中都是一个非常重要的步骤,主要如下:
- 确定序列读取之间的偏差是测序错误还是序列的基因差异
- 修正短读组装错误
- 计算亲缘度和特异度等参数
MapReduce解决方案
输入数据
@EAS54_6_R1_2_1_413_324
CCCTTCTTGTCCCCAGCGTTTCTCC
+
;;3;;;;;;;;;;;;7;;;;;;;88
@EAS54_6_R1_2_1_540_792
TTGGCAGGCCAAGGCCGATGGATCA
+
;;;;;;;;;;;7;;;;;-;;;3;83
@EAS54_6_R1_2_1_443_348
GTTGCTTCTGGCGTGGGTGGGGGGG
+EAS54_6_R1_2_1_443_348
;;;;;;;;;;;9;;;;.7;393333
@EAS54_6_R1_2_1_413_324
CCCCCCTTGTCTTCAGCCCTTCTCC
+
;;3;;;;;;;;;;;;7;;;;;;;88
@EAS54_6_R1_2_1_540_792
TTTTCAGGCCAAGGCCGATGGATCA
+
;;;;;;;;;;;7;;;;;-;;;3;83
@EAS54_6_R1_2_1_443_348
GTTGTTTCTGGCGTGGGTGGGGGGG
+EAS54_6_R1_2_1_443_348
;;;;;;;;;;;9;7;;.7;393333
@EAS54_6_R1_2_1_443_348
GTTGTTTCTGGCGTGGGTGGCCCCC
+EAS54_6_R1_2_1_443_348
;;;;;;;;;;;9;7;;.7;393333
map阶段任务
假如输入序列为CACACACAGT,且K=3,要统计3-mers个数,则会生成如下键-值对:
CAC 1
ACA 1
CAC 1
ACA 1
CAC 1
ACA 1
CAG 1
AGT 1
map阶段编码
package com.deng.Kmer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
public class KmerCountMapper extends Mapper<LongWritable,Text, Text, IntWritable> {
private final static IntWritable ONE=new IntWritable(1);
private int k;
private final Text kmerKey=new Text();
public void setup(Context context){
Configuration conf=context.getConfiguration();
this.k=conf.getInt("k.mer",3);
}
public void map(LongWritable key,Text value,Context context) throws IOException, InterruptedException {
String sequence=value.toString();
for(int i=0;i<sequence.length()-k+1;i++){
//如果这一行不存在DNA,跳过
if(!Character.isLetter(sequence.charAt(0))) continue;
String kmer=sequence.substring(i,k+i);
kmerKey.set(kmer);
context.write(kmerKey,ONE);
}
}
}
reducer阶段任务
对相同的键求和,如下
reducer输入
CAC 1
ACA 1
CAC 1
ACA 1
CAC 1
ACA 1
CAG 1
AGT 1
reducer输出
ACA 3
CAC 3
CAG 1
AGT 1
reducer阶段编码
package com.deng.Kmer;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
public class KmerCountReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
public void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
int sum = 0;
for(IntWritable value:values){
sum+=value.get();
}
context.write(key,new IntWritable(sum));
}
}
驱动程序如下
package com.deng.Kmer;
import com.deng.util.FileUtil;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
public class KmerCountDriver {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
FileUtil.deleteDirs("output");
Configuration conf=new Configuration();
String[] otherArgs=new String[]{"input/k_mer.txt","output"};
Job job=new Job(conf,"Kmer");
job.setJarByClass(KmerCountDriver.class);
job.setJobName("KmerCount");
job.setMapperClass(KmerCountMapper.class);
job.setReducerClass(KmerCountReducer.class);
job.setMapOutputValueClass(IntWritable.class);
job.setMapOutputKeyClass(Text.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.setInputPaths(job,new Path(otherArgs[0]));
FileOutputFormat.setOutputPath(job,new Path(otherArgs[1]));
System.exit(job.waitForCompletion(true)?0:1);
}
}
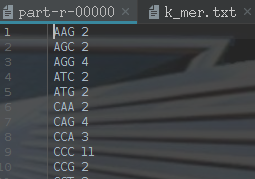
运行结果如下















 1745
1745











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









