







 本文利用强化学习和神经网络建立了一个股票交易系统,以2012~2015年的数据作为训练集,2015年为测试集。结果显示,该模型在测试期跑赢基准40个百分点,但在多次尝试优化和调整后,未能重现稳定的投资回报效果。这表明股市可能存在的可盈利模式难以捕捉,或者收益存在偶然性。
本文利用强化学习和神经网络建立了一个股票交易系统,以2012~2015年的数据作为训练集,2015年为测试集。结果显示,该模型在测试期跑赢基准40个百分点,但在多次尝试优化和调整后,未能重现稳定的投资回报效果。这表明股市可能存在的可盈利模式难以捕捉,或者收益存在偶然性。
简介:
本文采用强化学习+神经网络的框架,训练一个股票交易系统,并在个股上进行了测试。
下面为详细记录:
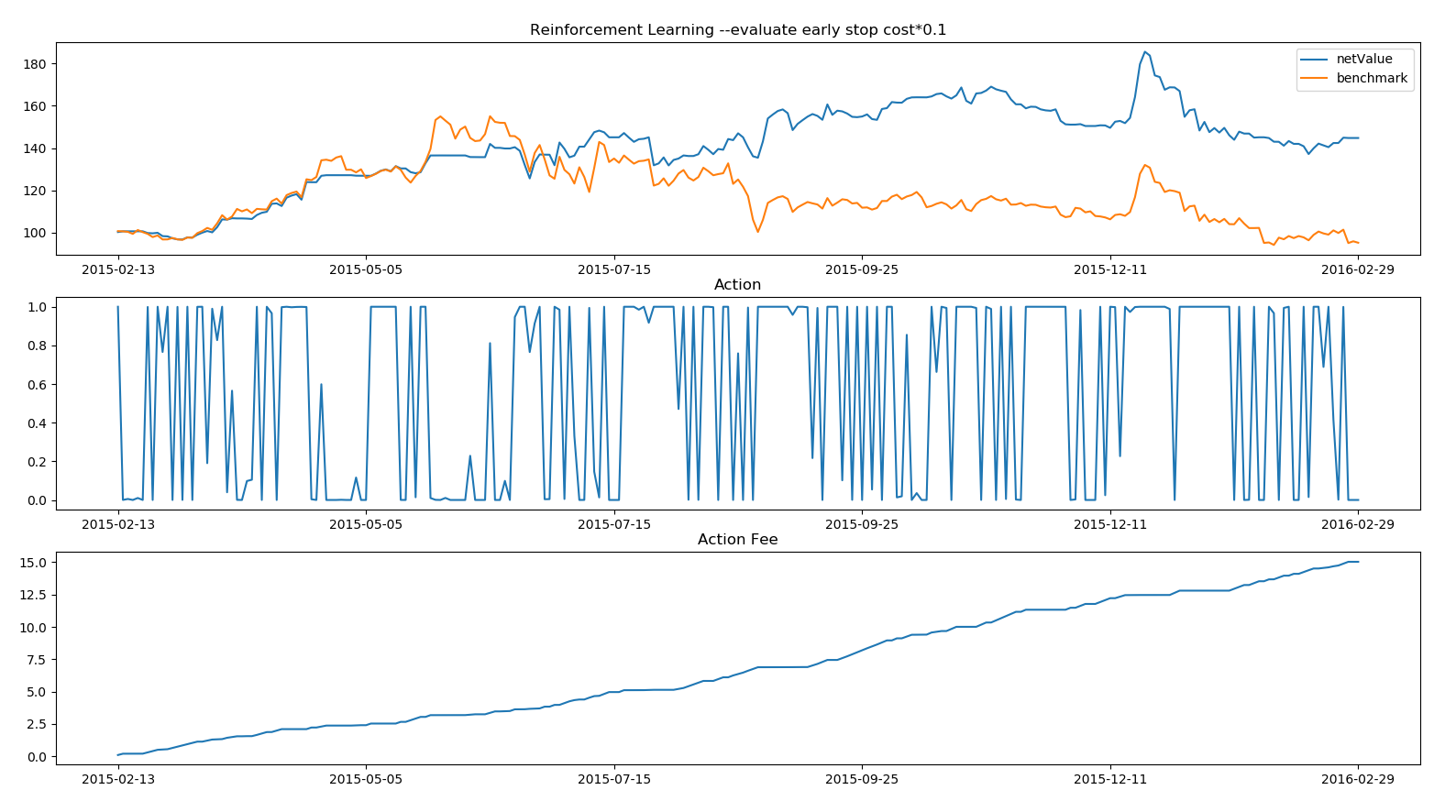
上面这个图是一个强化学习的交易模型。这个图是out sample的交易结果。2012~2015年的数据为训练数据,2015为out sample测试。
红线为伊利股份的股价,蓝线为交易净值。跑赢基准40个百分点。
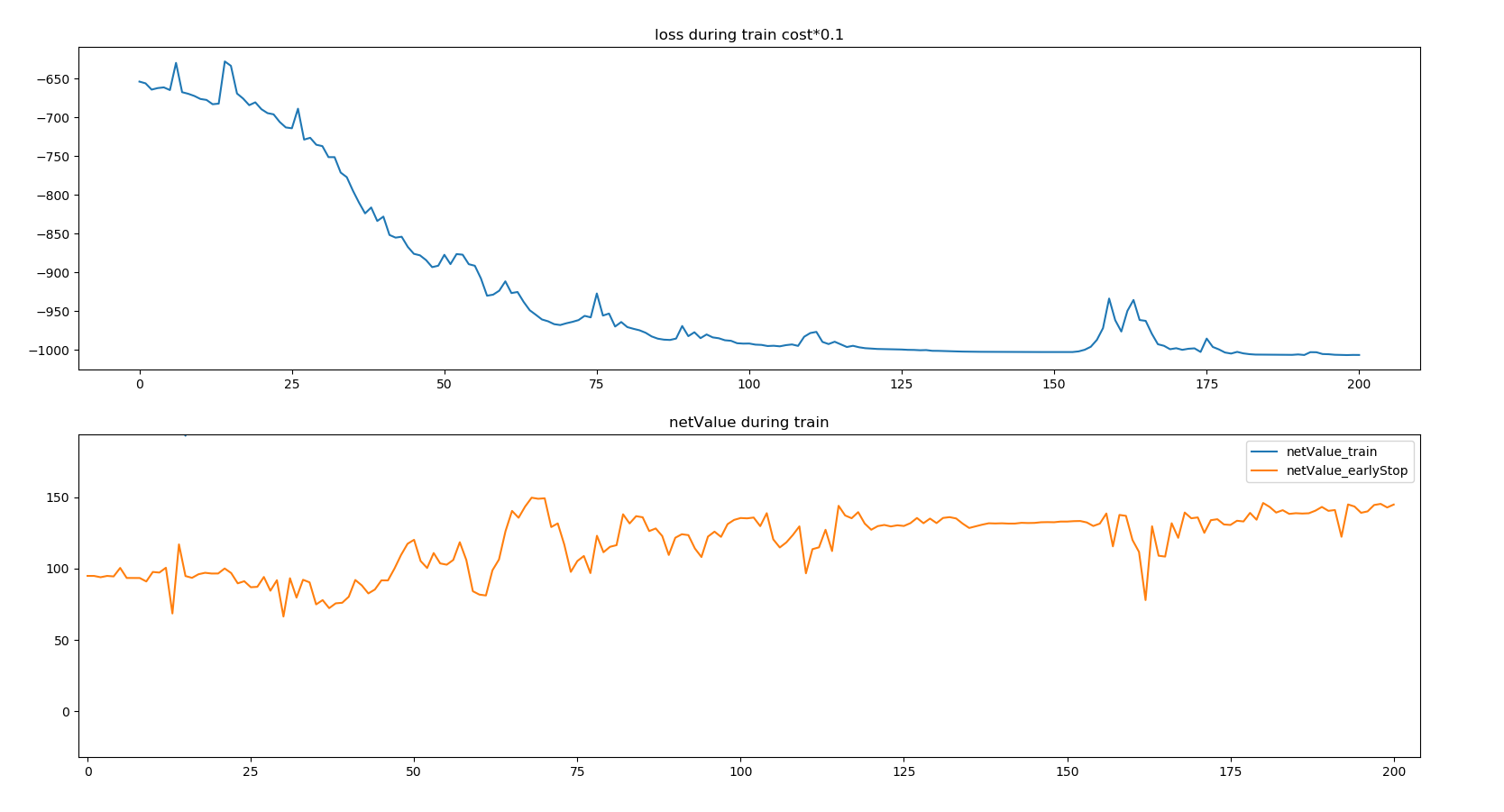
上面这个图显示的是模型在训练过程中的表现,在125个训练周期之后,模型能稳定的跑赢基准约40个百分点。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1526
1526

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









