







线程与协程的区别:
线程可以同时运行多个,而协程同时只能运行一个并且在要求被挂起时才挂起
c#接口:
1 不能包含成员变量,成员不能有public、protected、internal、private等修饰符。原因很简单,接口里面的方法都需要由外面接口实现去实现方法体,那么其修饰符必然是public。C#接口中的成员默认是public的,java中是可以加public的。因此定义函数的时候直接写返回这和方法名
2 接口可以多实现,而抽象类不行,只能单继承
3 定义接口时候,包含方法,但是方法里面不写代码
4 Java 接口中可以定义静态常量和方法, C#接口中不允许包含任何静态成员变量,所以c#中接口如果要放成员变量,那么就得用抽象类而不是接口
接口和抽象类的区别:
接口是对动作的抽象,抽象类是对根源的抽象
男人,女人,这两个类,他们的抽象类是人。人可以吃东西,狗也可以吃东西,你可以把“吃东西”定义成一个接口,然后让这些类去实现它
一个类只能继承一个类(抽象类)),但是可以实现多个接口(吃饭接口、走路接口)。
当你关注一个事物的本质的时候,用抽象类;当你关注一个操作的时候,用接口。
针对一个动作的描述。可以在一个类中同时实现多个接口
object GetValue(); //object方式
T GetValue<T>(); //泛型方式
在使用的时候
int a=(int)GetValue(); //这个编译的时候没问题的,但是如果GetValue返回的是其他类型,运行的时候就会出错
int a=GetValue<int>(); //这样无论如何都不会出错的,因为泛型被指定为int,它就一定会返回int,如果是其他类型,编译过程就会报错c#委托:
相当于c++中的函数指针,用来执行一个函数
ArrayList和List的区别:
ArrayList:它是命名空间System.Collections下的一部分,大小也是动态的,也可以进行.add .remove .insert等操作,但是会把插入的数据都当object来处理,这样是不安全的,就算我们很小心,插入的数据全是相同类型的,但是还需要把它转成原类型处理,存在装箱和拆箱问题,非常损耗性能

List:大部分和ArrayList相似最大区别是声明list也要匹配上其类型
ArrayList list = new ArrayList();
List<int> list = new List<int>();
这样就避免了装箱和拆箱的问题
c#隐式转换和显式转换:
隐式转换不需要在代码中指定转换类型:这里由于int4字节转成8字节double所以自动隐式转换int intNumber = 10; double doubleNumber = intNumber;但是大的字节类型转成小的字节类型的必须显式转换(加括号转换)对于类和类之间的转换,子类转父类可以隐式转换,父类转子类必须显式double doubleNumber = 10.1; int intNumber = (int)doubleNumber;string str1 = "abc";object obj = str1; //子类转换成父类,隐式转换 string str2 = (string)obj; //父类转换成子类,显式转换
如果两个类之间没有继承关系,则不能进行隐式转换或显式转换
int intType = (int)objType; //错误,能通过编译 int intType = Convert.ToInt32(objType); //正确, 强制转换 int intType = int.Parse(strType); //正确, 强制转换 int intType = int.Parse(objType); //错误,不能通过编译
在 C# 中,(int),Int32.Parse() 和 Convert.toInt32() 三种方法有何区别?
(int)表示使用显式强制转换,从 int 类型到 long、float、double 或decimal 类型,可以使用隐式转换,但是当我们从 long 类型到 int 类型转换就需要使用显式强制转换,否则会产生编译错误。Int32.Parse()表示将数字的字符串转换为32 位有符号整数
Convert.ToInt32() 则可以将多种类型(包括 object 引用类型)的值转换为 int 类型,因为它有许多重载版本[2]:
public static int ToInt32(object);
public static int ToInt32(bool);
public static int ToInt32(byte);
public static int ToInt32(char); .......
c#中is关键字:
格式:
class Base
{}
class Derived : Base
{ }Base b = d as Base;
继承类之间,允许把子类转换成父类,但是不可以把父类转换成子类,不同类之间,值类型不可转换
C#中virtual和abstract区别:
父类使用virtual修饰的函数在子类中可以重写或者不重写,如果重写子类函数要加上override,但是父类中abstract修饰的函数必须重写并且父类也要改成abstract修饰的类,同时该函数在父类中不能写函数体,就一空函数
int[] data = {62,58,88,47,73,99,35,51,93,37 };
BsTree tree = new BsTree();
foreach (int i in data) //注意這裡的i是data裡面的數據,不是data裡面的第i個元素
//在写数据结构的二叉树算法时发现当node==null的时候,node=newNode但是无法访问到node.Parent,那么我们把递归的顺序改下把递归中先判断节点是否为空再判断放到左右节点改成先判断放到左右节点,再判断是否为空,
下面一段代码:
static public int GetResult(int[] m,int n)
{
if (n==0)
{
return 0;
}
int tempMax=0;
int max=0;
for (int i=1;i<n+1;i++)
{
n = n - i;
tempMax = m[i] + GetResult(m,n);
if (tempMax > max)
{
max = tempMax;
}
}
return max;
}tempMax=m[i]+GetResult(m,n-i)
在for循环遍历中切记对for括号里面的变量赋值,这样会影响下次遍历的值
对于c#里面的对象一般是要new出来的,但是如果不new的话,那个类的方法或者变量必须是静态的的,才可以不new,类名.方法名();调用
c#中param关键字:
放在函数的参数中使用,后面跟一维数组,当传实参时,直接放多个相同类型的参数会自动把它们转变成数组传给形参中
比如函数这样定义:

实参这样传:

参数可以传任意多个
如果父类的覆写了构造函数那么子类要重写构造函数,后面加上:base(参数)
这句话的意思是不仅执行了父类的构造函数,同时还加了自己的一句话

list和数组的区别:
数组长度是固定的在new的时候就设置好了但是list长度是不固定的new的时候可以不设定,数组存入元素是存放到一段内存中,list是放入是不连续的
VS断点调试:
在某一行按F9,下断点

按F5程序执行时,会执行到该行停下来,你可以查看该行之前所有变量的值
比如我要查看上面代码st1的值,可以看到下面出现这个
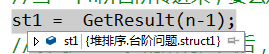
鼠标移动到三角上面,可以看到st1中保存了变量m和数组n,继续点开n可以看到数组里面的值

2 在运行过程中改变变量值
调试器不仅仅是分析程序崩溃和诡异行为的工具,还可以通过逐步调试检查数据和行为是否符合程序预期的方法解决许多bug。有时,你会想是否设置某些条件为真,程序就能正确运行了。其实你只要把鼠标移动到变量上,双击值,然后输入你需要的值。这样就不需要修改代码,重启程序了。
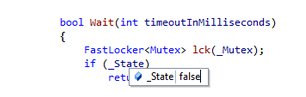
3 设置下一个运行位置
一个典型的调试案例是我们经常会用逐步调试的方法去分析为什么函数出错了。这时你遇到这个函数调用其他函数返回错误,而这个错误不是你想要的,你该怎么办?重启调试器?这里有个更好的方法,直接把黄色的运行位置箭头拖到你想要的运行位置。其实就是跳过中间运行代码,直接到想要的位置。很简单吧。

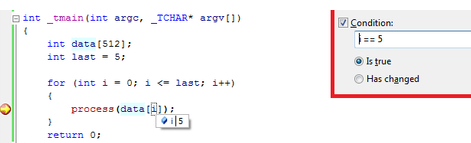
4 条件断点
如果你想重现一个小概率事件,但是断点在大量不需要的条件下也会触发。你可以很简单的设置条件断点。在断点窗口设置该断点条件,Visual studio 会自动忽略不符合条件的断点。
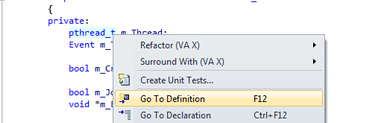
5 跳转到定义
如果你在解决别人写的代码一个bug,会遇到“这个类型是什么”“这个函数做什么的”之类的问题,你可以使用visual studio的跳转到定义的命令来查看类型或函数的定义。
6 命令窗口
这个小技巧是由chaau建议的,它能节省你大量的时间。Visual studio支持一个命令窗口,你可以通过菜单View->Other Windows->Command Window 打开。你可以在窗口里输入不同命令使调试自动化。比如,可以通过很简单的命令去的测试MFC的COleDateTime变量。
Socket套接字总结:
localhost和127.0.0.1都是表示本机的ip地址
粘包产生的原因:
在socket网络程序中,TCP和UDP分别是面向连接和非面向连接的。因此TCP的socket编程,收发两端(客户端和服务器端)都要有成对的socket,因此,发送端为了将多个发往接收端的包,更有效的发到对方,使用了优化方法(Nagle算法),将多次间隔较小、数据量小的数据,合并成一个大的数据块,然后进行封包。这样,接收端,就难于分辨出来了,必须提供科学的拆包机制。
而upd不会产生粘包。
保护消息边界和流:
例如,我们连续发送三个数据包,大小分别是2k,4k ,8k,这三个数据包,都已经到达了接收端的网络堆栈中,如果使用UDP协议,不管我们使用多大的接收缓冲区去接收数据,我们必须有三次接收动作,才能够把所有的数据包接收完.而使用TCP协议,我们只要把接收的缓冲区大小设置在14k以上,我们就能够一次把所有的数据包接收下来,只需要有一次接收动作。
因此,当tcp接收到一个包,当缓冲区足够大时候,这一个包可能包含了多个包
分包:发送一段数据量很大的信息,那么会用好几个包分开来发送
粘包的解决方法:
在客户端发送数据的时候,在该数据前面加上数据的大小,在服务器端收到的包有个缓冲数据,该数据大小是固定的m,我们取包时最前面取出数据大小假如为n,如果n<m说明,该包包含多个包,那么取出n个数据后,那后面又是s个大小的数据,看s+n<m,说明没取完,继续循环。
在c#引入mysql数据库进行插入语句的时候

如图,将用户名和密码插入到一条sql语句中进行数据库的操作,但是这样会导致sql注入,也即在字符串组拼的时候,在一个字符串里面加了一条sql语句导致执行了2条语句

这样不仅插入了数据同时还删除了整个表
如何防止sql注入呢?

在传入参数的时候使用这样的方式,最后插入的密码是整个字符串而不仅仅是icker,这样就避免了sql注入















 601
601

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









