







目录
Traditional ML Pipline
- 这里的features包括两种类型:结构(structural)特征、描述节点的属性(attribute)和properities特征
节点有一定附加属性,也想创造其他描述,例如节点怎么位于网络的其他部分,它的局部网络结构是什么,节点的邻域是什么,以及描述整个网络结构的features。可以之后将这些特征输入模型中做出预测。
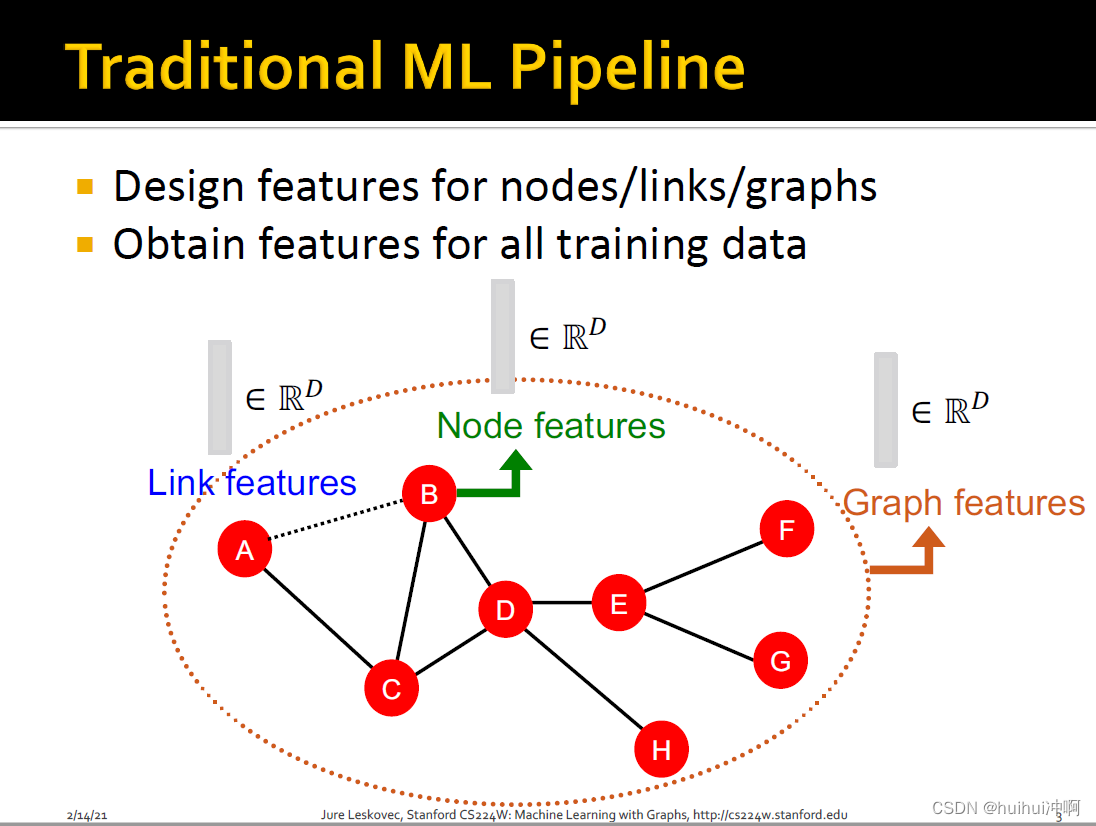
- Traditional ML Pipeline:首先获取nodes、links、graph的特征向量;然后训练一个ML model;最后在新的数据上(新的node link graph的特征向量)应用model,做出预测。Traditional ML Pipeline使用手工设计的特征。
在图上使用有效的特征是实现好性能的关键。在本节课中概述传统的特征为了:节点、边、图的预测。为了简单,只考虑无向图。
- 图中ML的goal:为一系列感兴趣的对象(nodes,edges,sets of nodes,graphs)做预测。
Node-level Tasks and Features
- 目标:描绘一个节点在网络中的结构和位置。
Node Degree
- 节点
的度数
是节点
- 缺陷:将所有邻居节点同等对待,无法捕捉邻居节点的重要性。(如果几个节点的度数相同,则特征向量相同,则模型对它们做出的预测相同。没办法区分它们)
Node centrality
1.节点中心性可以考虑图中节点的重要性。
Engienvector centrality
如果节点v被重要的nodes包围,则节点v是重要的(我的邻居都重要,那我应该也重要)。
由于左式是递归的,我们如何求解呢?
对应着
,即最大特征值对应的特征向量,
总是正值且是唯一的

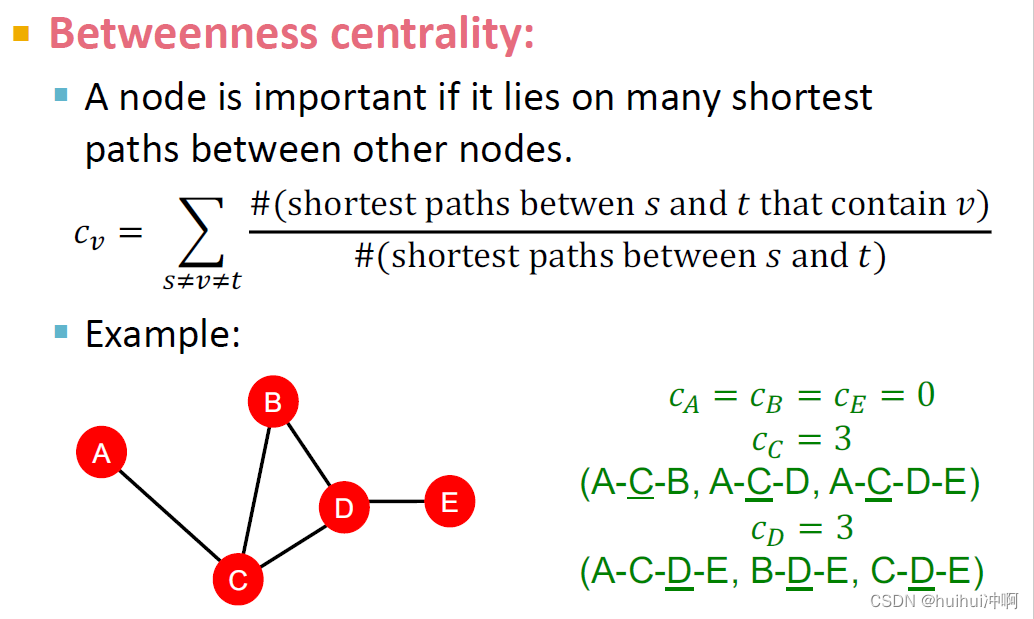
Betweenness centrality
如果一个节点在许多其他成对节点的最短路径上,那么节点重要。(如果一个节点是重要的连接器交通枢纽,那很重要)
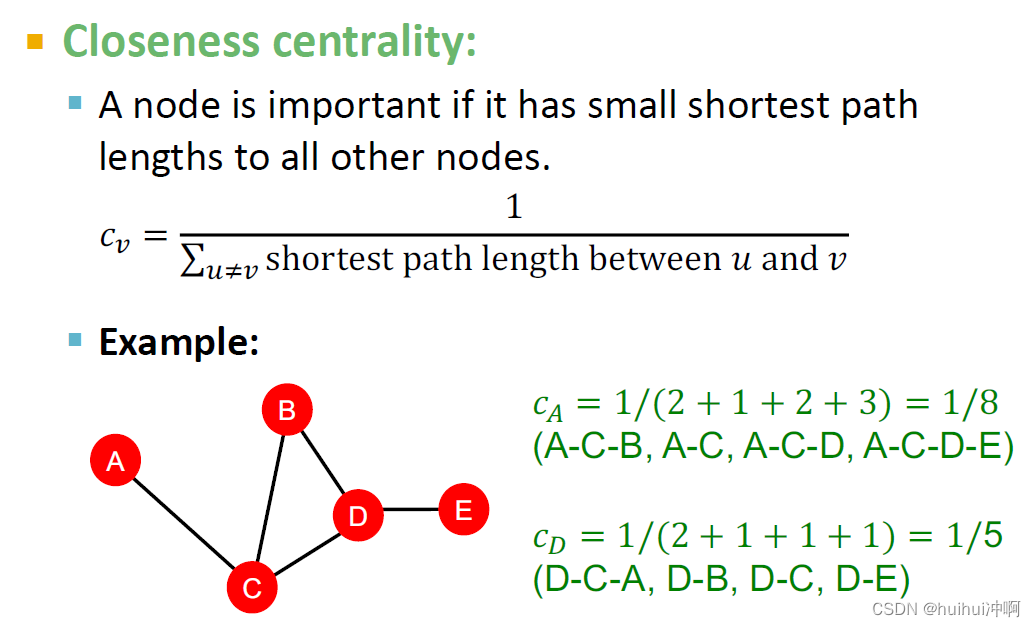
Closeness centrality
值越大越好
如果一个节点有到所有其他节点的最短路径,那么这个节点是重要的。
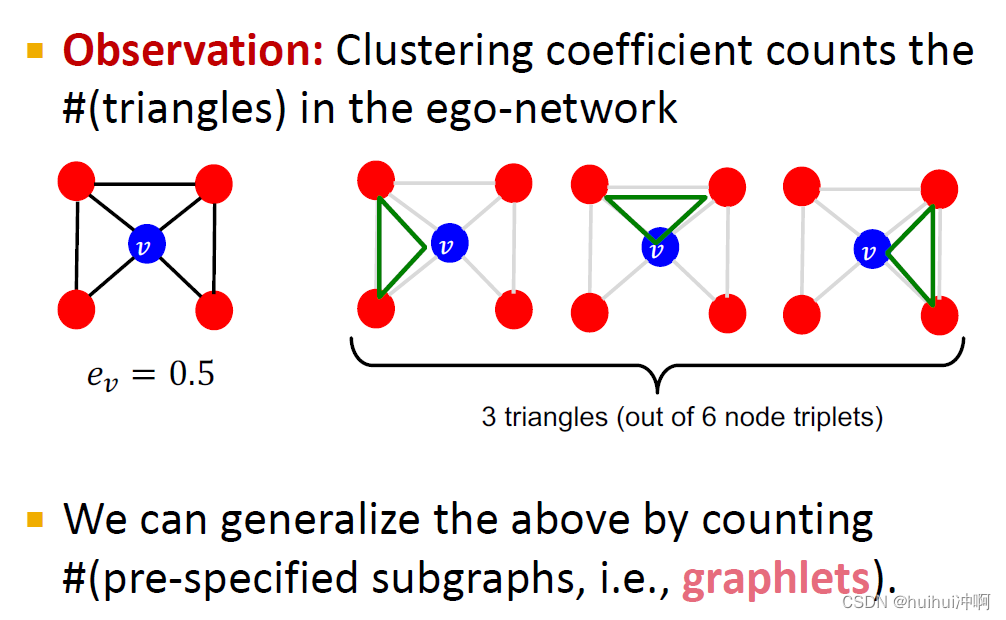
Clustering coefficient
聚类系数用来评价节点周围邻居节点的连接程度
=邻居节点真实存在边数➗最多可能存在边数

观察到聚类系数计算的是ego-network中三角形的数量(在社交网络中我的朋友的朋友也可能是我的朋友,社交网络会随着三角形的闭合而发展)
graphlets
那能否对三角形进行扩展,一般化为计算给定节点附近预先指定的子图的数量——graphlets,将仅仅对三角形的计数扩展到任意结构的子图。
graphlets:rooted(基于给定节点)连通的异构子图与motifs区分

引入GDV:计算一个节点参与的小图的数量
GDV——是一个根植于给定节点的子图的数量向量
因为graphlets是诱导子图( induced subgraph 节点的所有连接都要包含在内),所以节点在位置c不行,另两个节点必须要连接。
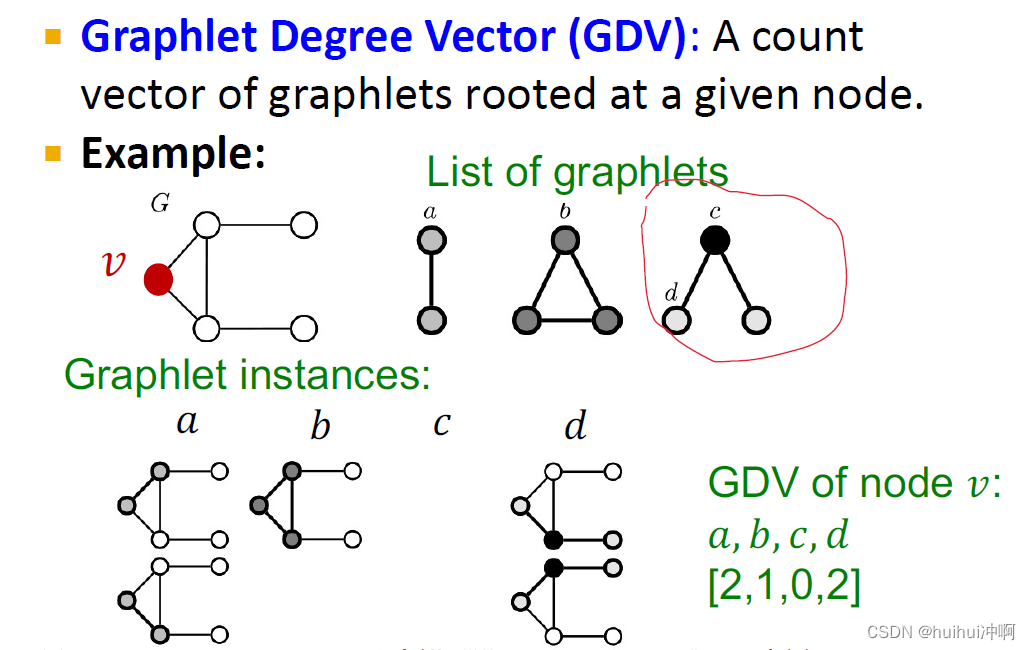
GDV提供了一种测量节点局部网络拓扑的方法,通过比较两个节点的GDV提供了一种比node degree和聚类系数更细节的测量局部拓扑相似性的方法。

总结
node features可以分为:
- Importance-based features:捕获节点在图中的重要性
- node degree:只计算了节点邻居节点的数量
- Node centrality:可以区别对待邻居节点Models importance of neighboring nodes
- Structure-based features:捕获节点局部邻域的拓扑结构
- node degree:只计算了节点邻居节点的数量
- 聚类系数:用来评价节点周围邻居节点的连接程度
- GDV:计数不同的graphlets的数量


















 4157
4157











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









