







本文是SLAM14讲中唯一的一个讲建图的章节,前面讲的前端后端都是重点在关注同时估计相机轨迹和特征点空间位置的问题。然而除了相机位置的定位外,还希望相机在运动的同时建立一张地图,用于定位,避障,导航,和交互等。单纯的特征点地图过于稀疏,信息也不够多,明显是不能满足这些需求的。
一,建图
1.1概述
在前面的前端后端中讲述的地图都是路标点在空间的位置,但是单纯的路标点地图对于上层应用往往是不够的。虽然在视觉slam中“建图”是服务于“定位”的;但是应用层面,“建图”模块的还有其他的重要需求:
- 定位:地图的基本功能,例如之前视觉里程计中提到的PnP就用到了地图信息;又或则是回环检测中的重定位。同时,对于同一个环境,还可以保存地图,在机器人下次开机时自动定位地图位置,这样就不需要再进行重新建图;
- 导航:导航是机器人能够在地图中进行路径规划,从任意两个地图点间寻找路径,然后走到目标点的过程。所以,在进行路径规划时,机器人需要从地图中得知那些地方不能通过,那些地方可以通过,这要求地图至少是一个稠密的形式;
- 避障:避障与导航类似,但是更关注局部动态障碍物的处理。所以仅仅是特征点,是无法判断他是障碍物不是的,所以同样要求是稠密地图;
- 重建:有时候需要利用SLAM技术恢复出某个环境的样子,这时候就需要重建得到机器人看到,经过的三维物体--例如三维的视频通话或则是网上购物。这同样需要稠密地图,不仅仅是稠密点云重建,更多是三维带纹理的平面;
- 交互:有时候会有利用地图,将人与地图进行互动。比如,增强现实中,与虚拟环境中的物体进行一系列的互动。另一方面,机器人中也有与人,与地图之间的交互。比如让机器人拿起桌子上的东西。而这需要另外一种形似的地图——语义地图。
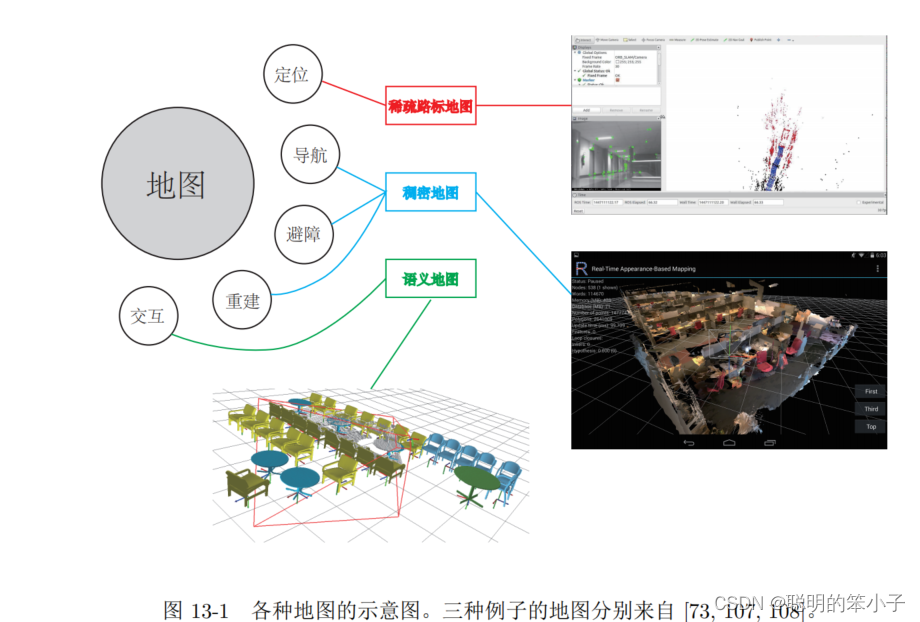
这时候就会发现,大部分的需求都要要求地图是稠密地图,但是前面的视觉SLAM只关注到了路标点。所以如何视觉SLAM建立稠密地图?
1.2 立体视觉和RGBD
想要稠密建图,就要知道图像中每一个像素的深度信息,那么就有以下的方案:
- 使用单目相机,在移动相机后进行三角化,测量像素的距离;
- 使用双目相机,利用左右相机的视差来计算像素的距离(多目相机同理);
- 使用RGB-D相机直接获取。
上面提到前两种方案都是根据相机与物体的集合关系来推算出像素深度信息,被称为立体视觉(View stereo),其中单目相机移动又称为移动视角的立体视觉(Moving View Stereo)。相较于直接使用RGB-D相机获取深度,利用几何信息的单目和双目对深度估计往往是计算复杂而且不准确的。而RGB-D相机也有一些量程,应用范围和光照的限制。使用立体视觉的好处是更适应室外环境,大场景场合。
二,单目相机稠密建图
考虑一段已知轨迹的视频序列,以第一张图像为参考帧,计算参考帧中每一像素的深度估计。在之前的特征点部分计算深度时,我们通过特征点匹配知道了某一空间点在各个图像中的位置,然后再通过三角测量的方法得到该空间点的深度信息。但是在稠密建图中,我们需要知道每一个像素点对应的空间点,而不是只有特征点。所以对于稠密深度估计问题,匹配就成为了很重要的一环。这就要用到极线搜索和块匹配技术[]。得到匹配结果后,就可以利用三角测量确定空间点的深度。不过,这里要使用多次三角测量来让深度结果收敛,随着测量次数的增加,结果逐渐收敛到一个稳定值,这个过程称为深度滤波技术。
2.1 极线搜索与块匹配
考虑空间中的某一点p,对应到前后两个图像中,左边的相机记为,右边的记为
。由于是单目相机,点p的深度是未知的,于是假设相机的深度在某个区域内
,那么这个范围对应到右边的相机图像中就是一条极线,当我们知道相机之间的运动时,这个极线在右边相机的位置就是一致的。我们需要确定是
在极线的哪个位置。
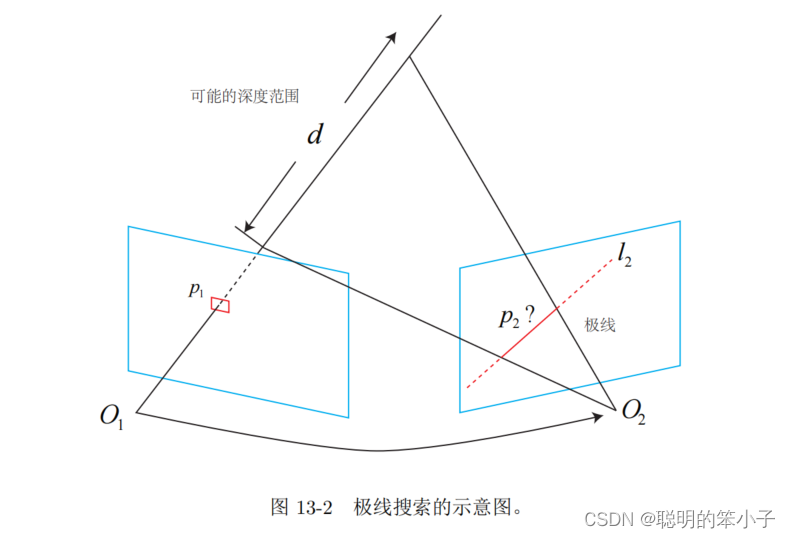
于是问题变成了在极线上找到一个与最相似的像素点,这个点就可以认为是
。比较像素点相似度可以使用之前直接法中的像素亮度,但这样的问题就是,只靠单个像素的亮度信息来判断相似程度是不可靠的,比如一条极线上可能有很多个相似的点,那这时候如何判断哪个才是真实的呢。
那既然单个像素是不可靠的,为什么不利用像素块来求相似度呢。就像之前直接法中,在周围去一个大小为
的块,然后同样的在极线上每个像素点取同样的块进行对比,得到最匹配块对应的像素。这个方法就是块匹配。这个方法同样是基于灰度不变原理来进行的,不过不仅仅是单个像素的灰度不变,而且是像素块的灰度不变。
计算像素块之间差异的方法有:
- SAD(Sum of Absolute Difference):两个小块差的绝对值之和:
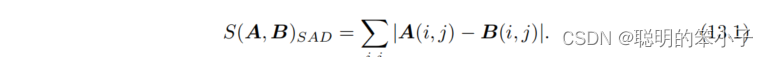
- SSD(Sum of Squared Distance):两个小块差的平方和:
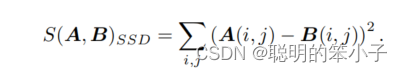
- NCC(Normalized Cross Correlation):归一化互相关,计算两个小块的相关性:
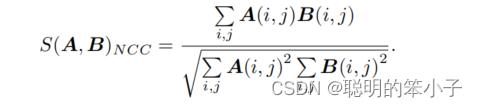
上面的算法,往往精度高的算法会更复杂,而简单的算法精度往往相对低一些,这就是精度—复杂度之间的矛盾。除了这些简单算法,还可以做一些预运算来提高算法精度,比如减去均值,称为取均值的SSD,去均值的NCC等。这样操作后,就算图像块A的整体亮度比图像B的整体亮度高一些也不会再影响算法的精度。参考文献[110][111]给出了更多的块匹配度量方法。
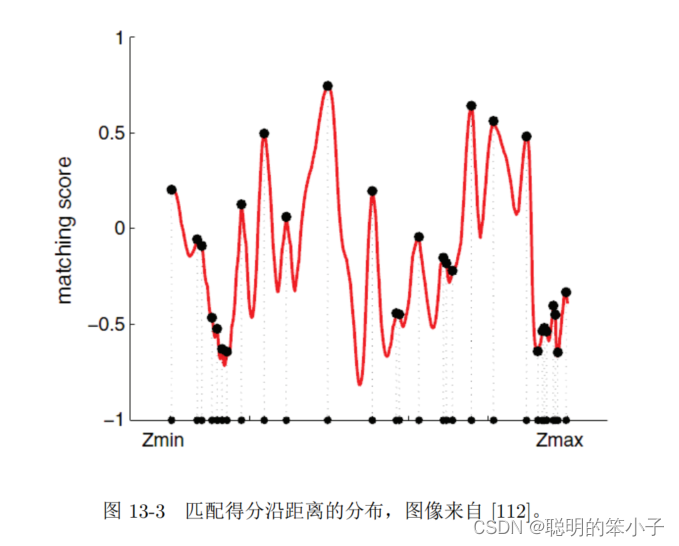
在完成块相似度计算后,就可以得到极线上每一个像素点与参考点之间相似度分布,如下图所示。可以发现这个分布中会存在很多个极值,但是肯定只有一个值是我们的真值。这时候我们更倾向于使用概率分布来描述深度值,而不是单一的数值。当我们不断对图像进行极线搜索时,我们估计的深度分布是怎么样变换的,这个就是深度滤波器。
2.2 高斯分布的深度滤波器
对像素深度的估计,本身是一个状态估计问题,可以使用滤波器和非线性优化两种思路来求解。但是考虑到实时性,建图还是会用滤波器的方法多一些。
假设深度值服从高斯分布,那么就得到一种类似于卡尔曼滤波的方式。而参考文献[112][56]则是采用了均匀-高斯混合分布的假设,推导了另一种形式更加复杂的深度滤波器。书中介绍了高斯分布下的深度滤波器:
设某个像素点的深度服从高斯分布:,当新的数据到来时,我们会观测到这个像素的深度,同样假设这个观测深度也服从高斯分布,
。那么问题就变成了将所有的观测信息融合,得到最可能的深度值。设融合后的深度d分布为
,那么就有:
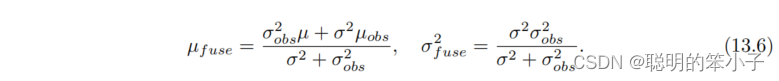
即当前的高斯分布乘以观测到的高斯分布,得到一个协方差更小的分布结果。这一点很像卡尔曼滤波的思想,只是没有运动方程,只有信息融合的部分。接下来要考虑的就是如何计算观测深度的分布。文献[59]考虑了几何不确定性和光度不确定性两个方面;文献[112]仅考虑了几何不确定性。书中给了仅考虑几何不确定性的推导。
以下图为例,当左边相机图像中的某一个点经过极线搜索和快匹配得到它在右边相机图像中对应点
,然后经过三角测量得到深度值,对用到3D空间为空间点P。记
为p,
为相机的平移t,
记为a。三角形下面的两个角分别记为
。当极线
存在误差时,使得
变成了
,而深度也由
变成了
。
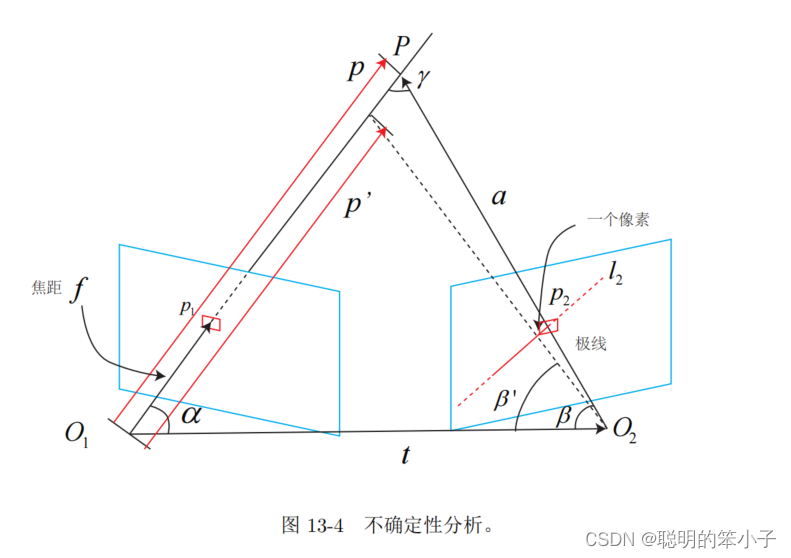
那么根据几何关系就有: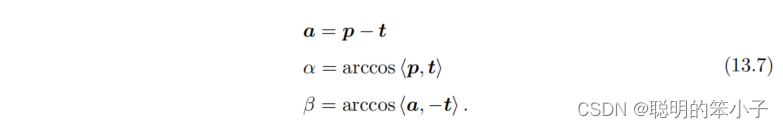
加入一个像素的扰动后,会使得产生一个偏移
,相机焦距为f的话,那么:
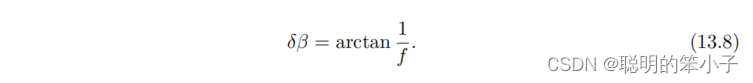
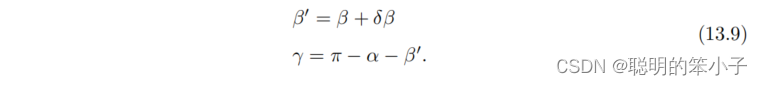
于是根据正弦定理,就可以求解出的大小:
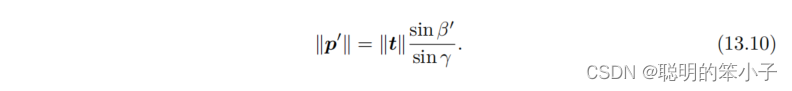
那么就可以定义一个像素误差引起的深度不确定性为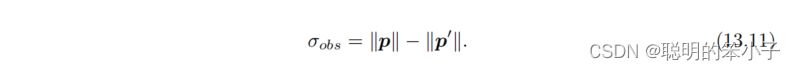
这是一个像素引起的不确定的差异,那么同样的方法也可以计算更多的像素一起的不确定性。当这个像素不确定度小于某个阈值时,我们认为算法收敛。深度滤波的流程如下:

2.3 单目稠密建图代码实践
#include <iostream>
#include <vector>
#include <fstream>
using namespace std;
#include <boost/timer.hpp>
// for sophus
#include <sophus/se3.h>
using Sophus::SE3;
// for eigen
#include <Eigen/Core>
#include <Eigen/Geometry>
using namespace Eigen;
#include <opencv2/core/core.hpp>
#include <opencv2/highgui/highgui.hpp>
#include <opencv2/imgproc/imgproc.hpp>
using namespace cv;
/**********************************************
* 本程序演示了单目相机在已知轨迹下的稠密深度估计
* 使用极线搜索 + NCC 匹配的方式,与书本的 13.2 节对应
* 请注意本程序并不完美,你完全可以改进它——我其实在故意暴露一些问题。
***********************************************/
// ------------------------------------------------------------------
// parameters
const int boarder = 20; // 边缘宽度
const int width = 640; // 宽度
const int height = 480; // 高度
const double fx = 481.2f; // 相机内参
const double fy = -480.0f;
const double cx = 319.5f;
const double cy = 239.5f;
const int ncc_window_size = 2; // NCC 取的窗口半宽度
const int ncc_area = (2*ncc_window_size+1)*(2*ncc_window_size+1); // NCC窗口面积
const double min_cov = 0.1; // 收敛判定:最小方差
const double max_cov = 10; // 发散判定:最大方差
// ------------------------------------------------------------------
// 重要的函数
// 从 REMODE 数据集读取数据
bool readDatasetFiles(
const string& path,
vector<string>& color_image_files,
vector<SE3>& poses
);
// 根据新的图像更新深度估计
bool update(
const Mat& ref,
const Mat& curr,
const SE3& T_C_R,
Mat& depth,
Mat& depth_cov
);
// 极线搜索
bool epipolarSearch(
const Mat& ref,
const Mat& curr,
const SE3& T_C_R,
const Vector2d& pt_ref,
const double& depth_mu,
const double& depth_cov,
Vector2d& pt_curr
);
// 更新深度滤波器
bool updateDepthFilter(
const Vector2d& pt_ref,
const Vector2d& pt_curr,
const SE3& T_C_R,
Mat& depth,
Mat& depth_cov
);
// 计算 NCC 评分
double NCC( const Mat& ref, const Mat& curr, const Vector2d& pt_ref, const Vector2d& pt_curr );
// 双线性灰度插值
inline double getBilinearInterpolatedValue( const Mat& img, const Vector2d& pt ) {
uchar* d = & img.data[ int(pt(1,0))*img.step+int(pt(0,0)) ];
double xx = pt(0,0) - floor(pt(0,0));
double yy = pt(1,0) - floor(pt(1,0));
return (( 1-xx ) * ( 1-yy ) * double(d[0]) +
xx* ( 1-yy ) * double(d[1]) +
( 1-xx ) *yy* double(d[img.step]) +
xx*yy*double(d[img.step+1]))/255.0;
}
// ------------------------------------------------------------------
// 一些小工具
// 显示估计的深度图
void plotDepth( const Mat& depth );
// 像素到相机坐标系
inline Vector3d px2cam ( const Vector2d px ) {
return Vector3d (
(px(0,0) - cx)/fx,
(px(1,0) - cy)/fy,
1
);
}
// 相机坐标系到像素
inline Vector2d cam2px ( const Vector3d p_cam ) {
return Vector2d (
p_cam(0,0)*fx/p_cam(2,0) + cx,
p_cam(1,0)*fy/p_cam(2,0) + cy
);
}
// 检测一个点是否在图像边框内
inline bool inside( const Vector2d& pt ) {
return pt(0,0) >= boarder && pt(1,0)>=boarder
&& pt(0,0)+boarder<width && pt(1,0)+boarder<=height;
}
// 显示极线匹配
void showEpipolarMatch( const Mat& ref, const Mat& curr, const Vector2d& px_ref, const Vector2d& px_curr );
// 显示极线
void showEpipolarLine( const Mat& ref, const Mat& curr, const Vector2d& px_ref, const Vector2d& px_min_curr, const Vector2d& px_max_curr );
// ------------------------------------------------------------------
int main( int argc, char** argv )
{
if ( argc != 2 )
{
cout<<"Usage: dense_mapping path_to_test_dataset"<<endl;
return -1;
}
// 从数据集读取数据
vector<string> color_image_files;
vector<SE3> poses_TWC;
bool ret = readDatasetFiles( argv[1], color_image_files, poses_TWC );
if ( ret==false )
{
cout<<"Reading image files failed!"<<endl;
return -1;
}
cout<<"read total "<<color_image_files.size()<<" files."<<endl;
// 第一张图
Mat ref = imread( color_image_files[0], 0 ); // gray-scale image
SE3 pose_ref_TWC = poses_TWC[0];
double init_depth = 3.0; // 深度初始值
double init_cov2 = 3.0; // 方差初始值
Mat depth( height, width, CV_64F, init_depth ); // 深度图
Mat depth_cov( height, width, CV_64F, init_cov2 ); // 深度图方差
for ( int index=1; index<color_image_files.size(); index++ )
{
cout<<"*** loop "<<index<<" ***"<<endl;
Mat curr = imread( color_image_files[index], 0 );
if (curr.data == nullptr) continue;
SE3 pose_curr_TWC = poses_TWC[index];
SE3 pose_T_C_R = pose_curr_TWC.inverse() * pose_ref_TWC; // 坐标转换关系: T_C_W * T_W_R = T_C_R
update( ref, curr, pose_T_C_R, depth, depth_cov );
plotDepth( depth );
imshow("image", curr);
waitKey(1);
}
cout<<"estimation returns, saving depth map ..."<<endl;
imwrite( "depth.png", depth );
cout<<"done."<<endl;
return 0;
}
bool readDatasetFiles(
const string& path,
vector< string >& color_image_files,
std::vector<SE3>& poses
)
{
ifstream fin( path+"/first_200_frames_traj_over_table_input_sequence.txt");
if ( !fin ) return false;
while ( !fin.eof() )
{
// 数据格式:图像文件名 tx, ty, tz, qx, qy, qz, qw ,注意是 TWC 而非 TCW
string image;
fin>>image;
double data[7];
for ( double& d:data ) fin>>d;
color_image_files.push_back( path+string("/images/")+image );
poses.push_back(
SE3( Quaterniond(data[6], data[3], data[4], data[5]),
Vector3d(data[0], data[1], data[2]))
);
if ( !fin.good() ) break;
}
return true;
}
// 对整个深度图进行更新
bool update(const Mat& ref, const Mat& curr, const SE3& T_C_R, Mat& depth, Mat& depth_cov )
{
#pragma omp parallel for
for ( int x=boarder; x<width-boarder; x++ )
#pragma omp parallel for
for ( int y=boarder; y<height-boarder; y++ )
{
// 遍历每个像素
if ( depth_cov.ptr<double>(y)[x] < min_cov || depth_cov.ptr<double>(y)[x] > max_cov ) // 深度已收敛或发散
continue;
// 在极线上搜索 (x,y) 的匹配
Vector2d pt_curr;
bool ret = epipolarSearch (
ref,
curr,
T_C_R,
Vector2d(x,y),
depth.ptr<double>(y)[x],
sqrt(depth_cov.ptr<double>(y)[x]),
pt_curr
);
if ( ret == false ) // 匹配失败
continue;
// 取消该注释以显示匹配
// showEpipolarMatch( ref, curr, Vector2d(x,y), pt_curr );
// 匹配成功,更新深度图
updateDepthFilter( Vector2d(x,y), pt_curr, T_C_R, depth, depth_cov );
}
}
// 极线搜索
// 方法见书 13.2 13.3 两节
bool epipolarSearch(
const Mat& ref, const Mat& curr,
const SE3& T_C_R, const Vector2d& pt_ref,
const double& depth_mu, const double& depth_cov,
Vector2d& pt_curr )
{
Vector3d f_ref = px2cam( pt_ref );
f_ref.normalize();
Vector3d P_ref = f_ref*depth_mu; // 参考帧的 P 向量
Vector2d px_mean_curr = cam2px( T_C_R*P_ref ); // 按深度均值投影的像素
double d_min = depth_mu-3*depth_cov, d_max = depth_mu+3*depth_cov;
if ( d_min<0.1 ) d_min = 0.1;
Vector2d px_min_curr = cam2px( T_C_R*(f_ref*d_min) ); // 按最小深度投影的像素
Vector2d px_max_curr = cam2px( T_C_R*(f_ref*d_max) ); // 按最大深度投影的像素
Vector2d epipolar_line = px_max_curr - px_min_curr; // 极线(线段形式)
Vector2d epipolar_direction = epipolar_line; // 极线方向
epipolar_direction.normalize();
double half_length = 0.5*epipolar_line.norm(); // 极线线段的半长度
if ( half_length>100 ) half_length = 100; // 我们不希望搜索太多东西
// 取消此句注释以显示极线(线段)
// showEpipolarLine( ref, curr, pt_ref, px_min_curr, px_max_curr );
// 在极线上搜索,以深度均值点为中心,左右各取半长度
double best_ncc = -1.0;
Vector2d best_px_curr;
for ( double l=-half_length; l<=half_length; l+=0.7 ) // l+=sqrt(2)
{
Vector2d px_curr = px_mean_curr + l*epipolar_direction; // 待匹配点
if ( !inside(px_curr) )
continue;
// 计算待匹配点与参考帧的 NCC
double ncc = NCC( ref, curr, pt_ref, px_curr );
if ( ncc>best_ncc )
{
best_ncc = ncc;
best_px_curr = px_curr;
}
}
if ( best_ncc < 0.85f ) // 只相信 NCC 很高的匹配
return false;
pt_curr = best_px_curr;
return true;
}
double NCC (
const Mat& ref, const Mat& curr,
const Vector2d& pt_ref, const Vector2d& pt_curr
)
{
// 零均值-归一化互相关
// 先算均值
double mean_ref = 0, mean_curr = 0;
vector<double> values_ref, values_curr; // 参考帧和当前帧的均值
for ( int x=-ncc_window_size; x<=ncc_window_size; x++ )
for ( int y=-ncc_window_size; y<=ncc_window_size; y++ )
{
double value_ref = double(ref.ptr<uchar>( int(y+pt_ref(1,0)) )[ int(x+pt_ref(0,0)) ])/255.0;
mean_ref += value_ref;
double value_curr = getBilinearInterpolatedValue( curr, pt_curr+Vector2d(x,y) );
mean_curr += value_curr;
values_ref.push_back(value_ref);
values_curr.push_back(value_curr);
}
mean_ref /= ncc_area;
mean_curr /= ncc_area;
// 计算 Zero mean NCC
double numerator = 0, demoniator1 = 0, demoniator2 = 0;
for ( int i=0; i<values_ref.size(); i++ )
{
double n = (values_ref[i]-mean_ref) * (values_curr[i]-mean_curr);
numerator += n;
demoniator1 += (values_ref[i]-mean_ref)*(values_ref[i]-mean_ref);
demoniator2 += (values_curr[i]-mean_curr)*(values_curr[i]-mean_curr);
}
return numerator / sqrt( demoniator1*demoniator2+1e-10 ); // 防止分母出现零
}
bool updateDepthFilter(
const Vector2d& pt_ref,
const Vector2d& pt_curr,
const SE3& T_C_R,
Mat& depth,
Mat& depth_cov
)
{
// 我是一只喵
// 不知道这段还有没有人看
// 用三角化计算深度
SE3 T_R_C = T_C_R.inverse();
Vector3d f_ref = px2cam( pt_ref );
f_ref.normalize();
Vector3d f_curr = px2cam( pt_curr );
f_curr.normalize();
// 方程
// d_ref * f_ref = d_cur * ( R_RC * f_cur ) + t_RC
// => [ f_ref^T f_ref, -f_ref^T f_cur ] [d_ref] = [f_ref^T t]
// [ f_cur^T f_ref, -f_cur^T f_cur ] [d_cur] = [f_cur^T t]
// 二阶方程用克莱默法则求解并解之
Vector3d t = T_R_C.translation();
Vector3d f2 = T_R_C.rotation_matrix() * f_curr;
Vector2d b = Vector2d ( t.dot ( f_ref ), t.dot ( f2 ) );
double A[4];
A[0] = f_ref.dot ( f_ref );
A[2] = f_ref.dot ( f2 );
A[1] = -A[2];
A[3] = - f2.dot ( f2 );
double d = A[0]*A[3]-A[1]*A[2];
Vector2d lambdavec =
Vector2d ( A[3] * b ( 0,0 ) - A[1] * b ( 1,0 ),
-A[2] * b ( 0,0 ) + A[0] * b ( 1,0 )) /d;
Vector3d xm = lambdavec ( 0,0 ) * f_ref;
Vector3d xn = t + lambdavec ( 1,0 ) * f2;
Vector3d d_esti = ( xm+xn ) / 2.0; // 三角化算得的深度向量
double depth_estimation = d_esti.norm(); // 深度值
// 计算不确定性(以一个像素为误差)
Vector3d p = f_ref*depth_estimation;
Vector3d a = p - t;
double t_norm = t.norm();
double a_norm = a.norm();
double alpha = acos( f_ref.dot(t)/t_norm );
double beta = acos( -a.dot(t)/(a_norm*t_norm));
double beta_prime = beta + atan(1/fx);
double gamma = M_PI - alpha - beta_prime;
double p_prime = t_norm * sin(beta_prime) / sin(gamma);
double d_cov = p_prime - depth_estimation;
double d_cov2 = d_cov*d_cov;
// 高斯融合
double mu = depth.ptr<double>( int(pt_ref(1,0)) )[ int(pt_ref(0,0)) ];
double sigma2 = depth_cov.ptr<double>( int(pt_ref(1,0)) )[ int(pt_ref(0,0)) ];
double mu_fuse = (d_cov2*mu+sigma2*depth_estimation) / ( sigma2+d_cov2);
double sigma_fuse2 = ( sigma2 * d_cov2 ) / ( sigma2 + d_cov2 );
depth.ptr<double>( int(pt_ref(1,0)) )[ int(pt_ref(0,0)) ] = mu_fuse;
depth_cov.ptr<double>( int(pt_ref(1,0)) )[ int(pt_ref(0,0)) ] = sigma_fuse2;
return true;
}
// 后面这些太简单我就不注释了(其实是因为懒)
void plotDepth(const Mat& depth)
{
imshow( "depth", depth*0.4 );
waitKey(1);
}
void showEpipolarMatch(const Mat& ref, const Mat& curr, const Vector2d& px_ref, const Vector2d& px_curr)
{
Mat ref_show, curr_show;
cv::cvtColor( ref, ref_show, CV_GRAY2BGR );
cv::cvtColor( curr, curr_show, CV_GRAY2BGR );
cv::circle( ref_show, cv::Point2f(px_ref(0,0), px_ref(1,0)), 5, cv::Scalar(0,0,250), 2);
cv::circle( curr_show, cv::Point2f(px_curr(0,0), px_curr(1,0)), 5, cv::Scalar(0,0,250), 2);
imshow("ref", ref_show );
imshow("curr", curr_show );
waitKey(1);
}
void showEpipolarLine(const Mat& ref, const Mat& curr, const Vector2d& px_ref, const Vector2d& px_min_curr, const Vector2d& px_max_curr)
{
Mat ref_show, curr_show;
cv::cvtColor( ref, ref_show, CV_GRAY2BGR );
cv::cvtColor( curr, curr_show, CV_GRAY2BGR );
cv::circle( ref_show, cv::Point2f(px_ref(0,0), px_ref(1,0)), 5, cv::Scalar(0,255,0), 2);
cv::circle( curr_show, cv::Point2f(px_min_curr(0,0), px_min_curr(1,0)), 5, cv::Scalar(0,255,0), 2);
cv::circle( curr_show, cv::Point2f(px_max_curr(0,0), px_max_curr(1,0)), 5, cv::Scalar(0,255,0), 2);
cv::line( curr_show, Point2f(px_min_curr(0,0), px_min_curr(1,0)), Point2f(px_max_curr(0,0), px_max_curr(1,0)), Scalar(0,255,0), 1);
imshow("ref", ref_show );
imshow("curr", curr_show );
waitKey(1);
}
2.4 单目相机稠密建图的问题
2.4.1 像素梯度问题
根据实验结果发现块匹配的正确度与像素块的区分度有着直接的关系。比如当整张图像存在大量的纯色像素时,很容易就会发生误匹配的问题。这个问题在之前的直接法中也有涉及到,当我们假设像素块的灰度是不变进行匹配时,有明显梯度的小块将拥有良好的区分度,不容易出现误匹配;但是对于梯度不明显的像素,就会很容易出错。因此,单目相机稠密建图对物体纹理的依赖性很强。这个问题同样出现在双目相机中,十分依赖于环境的纹理度。
参考文献[59]还详细讨论了像素梯度与极线之间的关系,以下图为例:
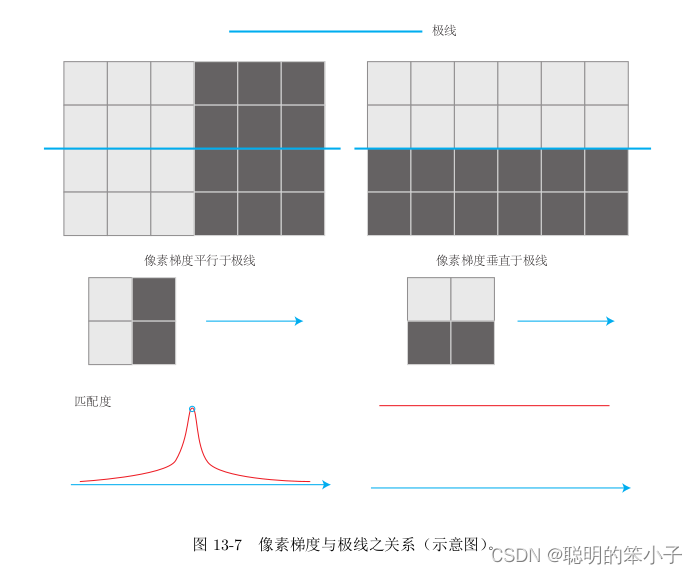
当像素梯度垂直于极线方向时,可以精确的发现匹配最高点在何处,但是对于平行的情况,像素块的匹配几乎是一样的,这时候的匹配结果肯定是不一样的。在实际情况中,梯度和极线的情况可能位于两者之间。总结为,当像素梯度与极线夹角较小时,极线匹配的不确定性大;反之夹角较大时,匹配的不确定性变小。
2.4.2 逆深度
深度滤波器默认像素点对应的空间点的深度是服从高斯分布的,其他的两维x和y是固定的。那么这样就存在一些问题:
- 首先深度值是从相机焦距到无限远处,所以他并不会像高斯分布那样是对称分布的,尾部稍长,而负数域则是零;
- 在室外的应用中,可能存在一些距离特别远的点,这时候的就很难估计到正确的深度。
于是,参考[115]发现假设深度的倒数符合高斯分布是更有效的,就是所谓的逆深度。具体的SLAM应用可以参考[56][57]][73]。
2.4.3 图像间的旋转变换
当相机发生明显的旋转时,在块匹配中假设的图像块在运动过程保持不变就很难继续保持了。比如最特殊的情况,一个上黑下白的图像块可能在经过相机的运动后变成一个上白下黑的图像块,这直接导致在计算相关性的时候会得到负值。
为了解决这个问题,可以在进行块匹配的时候将相机的运动考虑进来,具体的做法是:参考帧上的某一个像素与真实的三维点世界坐标系
之间的关系如下:
而对于当前帧上的像素点有:
两个式子联立消去可得:
根据上面的等式,参考帧的像素位置和深度
是已知的,那么就可以计算出来
大概的投影位置。对于
两个分量上的增量
和
,同样可以根据公式计算出
上的增量
和
。这样的话,在局部范围内参考帧和当前帧会存在一个线性变换关系:
这样就可以将当前帧进行旋转变换后,在进行块匹配,来消除旋转对块匹配结果的影响。
2.4.4 并行化:效率问题
三,RGB-D稠密建图
不同于单目或则双目相机利用算法来计算像素深度信息,RGB-D相机直接利用硬件测量得到深度信息。这使得我们不需要浪费大量的资源来计算深度,同时RGB-D相机的结构光或飞时原理,保证了深度数据对纹理的无关性。
利用RGB-D相机,稠密建图会变得容易很多。只是对于不同地图的形式,有若干种不同的主流建图方式。最直接的方法就是利用估算的相机位姿,将像素点转化为点云(Point Cloud),然后进行拼接,最后得到一个由离散点组成的点云地图。在此基础上,如果我们希望估计物体的表面,可以使用三角网格(Mesh),面片(Surfel)进行建图。或则当我们需要保存障碍物信息的时候,可以通过体素(Voxel)建立占据网格地图(Occupancy Map)。
3.1 点云地图代码实践
RGB-D相机提供了彩色图和深度图,这样就很容易根据相机内参计算RGB-D点云。配合相机的位姿,就可以将点云拼接起来,获得全局点云地图。同时,为了使点云地图的外观更好看,往往在建图完成后会加一步滤波的操作。常用的滤波算法有外点去除滤波以及降采样滤波器。代码如下:
#include <iostream>
#include <fstream>
using namespace std;
#include <opencv2/core/core.hpp>
#include <opencv2/highgui/highgui.hpp>
#include <Eigen/Geometry>
#include <boost/format.hpp> // for formating strings
#include <pcl/point_types.h>
#include <pcl/io/pcd_io.h>
#include <pcl/filters/voxel_grid.h>
#include <pcl/visualization/pcl_visualizer.h>
#include <pcl/filters/statistical_outlier_removal.h>
int main( int argc, char** argv )
{
vector<cv::Mat> colorImgs, depthImgs; // 彩色图和深度图
vector<Eigen::Isometry3d> poses; // 相机位姿
ifstream fin("./data/pose.txt");
if (!fin)
{
cerr<<"cannot find pose file"<<endl;
return 1;
}
for ( int i=0; i<5; i++ )
{
boost::format fmt( "./data/%s/%d.%s" ); //图像文件格式
colorImgs.push_back( cv::imread( (fmt%"color"%(i+1)%"png").str() ));
depthImgs.push_back( cv::imread( (fmt%"depth"%(i+1)%"pgm").str(), -1 )); // 使用-1读取原始图像
double data[7] = {0};
for ( int i=0; i<7; i++ )
{
fin>>data[i];
}
Eigen::Quaterniond q( data[6], data[3], data[4], data[5] );
Eigen::Isometry3d T(q);
T.pretranslate( Eigen::Vector3d( data[0], data[1], data[2] ));
poses.push_back( T );
}
// 计算点云并拼接
// 相机内参
double cx = 325.5;
double cy = 253.5;
double fx = 518.0;
double fy = 519.0;
double depthScale = 1000.0;
cout<<"正在将图像转换为点云..."<<endl;
// 定义点云使用的格式:这里用的是XYZRGB
typedef pcl::PointXYZRGB PointT;
typedef pcl::PointCloud<PointT> PointCloud;
// 新建一个点云
PointCloud::Ptr pointCloud( new PointCloud );
for ( int i=0; i<5; i++ )
{
PointCloud::Ptr current( new PointCloud );
cout<<"转换图像中: "<<i+1<<endl;
cv::Mat color = colorImgs[i];
cv::Mat depth = depthImgs[i];
Eigen::Isometry3d T = poses[i];
for ( int v=0; v<color.rows; v++ )
for ( int u=0; u<color.cols; u++ )
{
unsigned int d = depth.ptr<unsigned short> ( v )[u]; // 深度值
if ( d==0 ) continue; // 为0表示没有测量到
if ( d >= 7000 ) continue; // 深度太大时不稳定,去掉
Eigen::Vector3d point;
point[2] = double(d)/depthScale;
point[0] = (u-cx)*point[2]/fx;
point[1] = (v-cy)*point[2]/fy;
Eigen::Vector3d pointWorld = T*point;
PointT p ;
p.x = pointWorld[0];
p.y = pointWorld[1];
p.z = pointWorld[2];
p.b = color.data[ v*color.step+u*color.channels() ];
p.g = color.data[ v*color.step+u*color.channels()+1 ];
p.r = color.data[ v*color.step+u*color.channels()+2 ];
current->points.push_back( p );
}
// depth filter and statistical removal
//从一个点云数据集中移除测量噪声点(也就是离群点)
PointCloud::Ptr tmp ( new PointCloud );
pcl::StatisticalOutlierRemoval<PointT> statistical_filter;
statistical_filter.setMeanK(50); //设置在进行统计时考虑查询点邻居点数
statistical_filter.setStddevMulThresh(1.0); //设置判断是否为离群点的阈值
statistical_filter.setInputCloud(current); //设置待滤波的点云
statistical_filter.filter( *tmp ); //设置output
(*pointCloud) += *tmp;
}
pointCloud->is_dense = false;
cout<<"点云共有"<<pointCloud->size()<<"个点."<<endl;
// voxel filter
pcl::VoxelGrid<PointT> voxel_filter;
voxel_filter.setLeafSize( 0.01, 0.01, 0.01 ); // resolution
PointCloud::Ptr tmp ( new PointCloud );
voxel_filter.setInputCloud( pointCloud );
voxel_filter.filter( *tmp );
tmp->swap( *pointCloud );
cout<<"滤波之后,点云共有"<<pointCloud->size()<<"个点."<<endl;
pcl::io::savePCDFileBinary("map.pcd", *pointCloud );
return 0;
}3.2 八叉树地图
普通的点云地图以下明显的缺点:
- 规模过大,会占用大量的存储空间,即使经过滤波算法,还是很大。例如一张640*480的地图会生成30万个空间点,但实际上很多点都是不必要的;
- 另外一方面,点云地图无法处理运动物体,因为只能不断添加点,而没有删除点。比如空间中的一些动态物体,往往是需要实时的删除的。
所以引入另外一种在导航种比较常用的地图格式——八叉树地图(Octo-map)[118]。
3.2.1 八叉树地图介绍
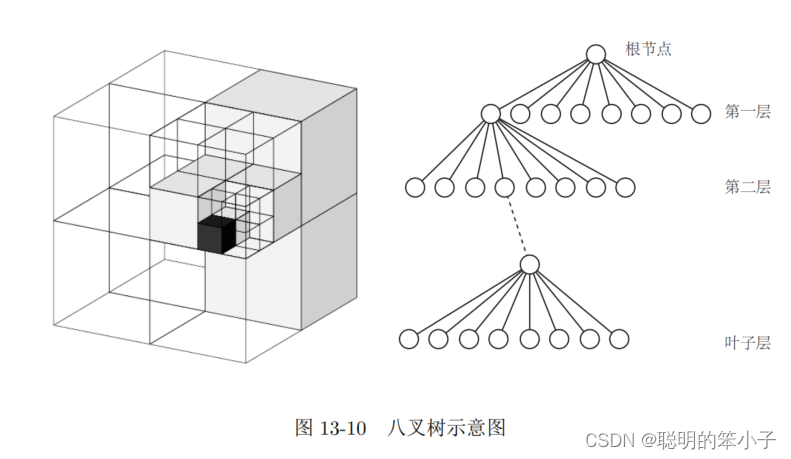
把三维空间建模为许多个小方块(体素),然后如果再对每一个小方块的每一个面平均切成两片,那么这个小方块就变成了同样大小的八个小方块。不断重复这个步骤直到达到建模的最高精度。可以”把一个小方块切成八个更小的方块“这件事,看作“从一个节点展开成八个节点”。那这个过程就可以看成是八叉树(Octo-tree)的生成过程。如下图所示,整个大方块可以看成是八叉树的根节点,而最小块则是叶子节点
对于一个十层的八叉树,如果每个叶子方块的边长为1,那么这个八叉树对应的地图体积就是
,可以看到这很大。体积跟树的深度是成指数关系的,当深度增加一层时,体积的变化是巨大的。但是八叉树存储地图时会在节点种存储他是否占据的信息。当某个方块的所有子节点都被占据或则都不被占据时,就没有必要展开这个节点。在地图最开始建立阶段,可能就需要一个根节点,这时候不需要把节点都完全展开。
下图是在知乎上的一个解释,我感觉这个解释更直观一些。给了一个2D的例子,所以实际上是一个四叉树,不过生成原理是一样的。可以看到,对每一个节点不断展开直到每个方格中只有一个点。下面两个方格比较稀疏,每个都只有一个点,所以只在根节点展开了一次,后面再不再展开。游戏场景管理的八叉树算法是怎样的? - 知乎 (zhihu.com)

对于节点中存储的是否被占用的信息,可以对点云类中定义0或1表示占用与否。但是这样的表示过于简单了,因为采集的点云本身就具备噪声或则动态点云,可能一会儿是0,一会儿又是1。那么这时候使用概率的方式来描述这个状态更合适。例如用区间[0,1]表示被占用的概率,所有的初始值都为0.5,随着观测次数的不断增加,每次被观测到占用这个值就增加;观测到空白则减小。这样就动态地建立了地图中的障碍物信息。
不过对占用概率值不断增加或则减小时,很容易让它跑出[0,1]这个范围外,所以这里不直接使用概率x来描述,而是概率对数值y(Log-odds)来描述。
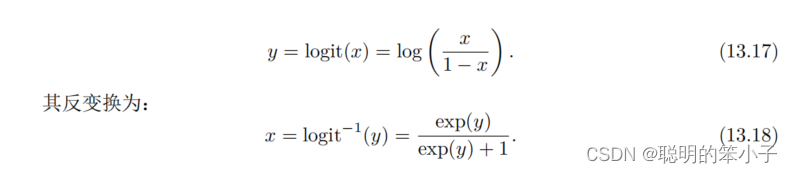
当y从变到
时,x从0变到了1,当y取0时,x取0.5。当不断观测到被“占据”时,就增加y;反之则减小y。而需要确定节点的占用情况时,就使用逆logit变换,将y转化为概率x。例如某个节点n的观测数据为z,那么从开始到t时刻这个节点的概率对数为
,那么t+1时刻就是:
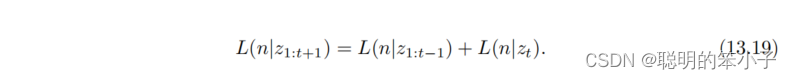
如果将上面的概率对数形式写成概率对数形式,就是:
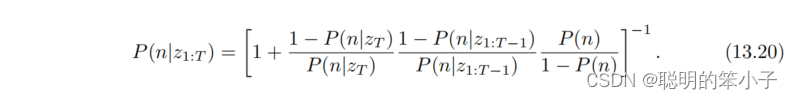
到此,八叉树的节点占用就用概率表示出来了。根据这个概率,就可以对新加入的3D点进行更新八叉树。当RGB-D相机观测到空间中一个点后,这时候我们就可以知道深度值对应的空间点会占据一个数据,并且在相机光心和这个点的连线上是没有物体的。利用这点就可以对八叉树地图进行更细,并且处理运动物体。
3.2.2 八叉树地图代码实践
根上面的RGB-D稠密建图的实现方法类似,直接调用函数将点云放到函数中就可以生成对应的树,保存下来后使用 octovis octopmap.bt 来将结果可视化。代码如下:
#include <iostream>
#include <fstream>
using namespace std;
#include <opencv2/core/core.hpp>
#include <opencv2/highgui/highgui.hpp>
#include <octomap/octomap.h> // for octomap
#include <Eigen/Geometry>
#include <boost/format.hpp> // for formating strings
int main( int argc, char** argv )
{
vector<cv::Mat> colorImgs, depthImgs; // 彩色图和深度图
vector<Eigen::Isometry3d> poses; // 相机位姿
ifstream fin("./data/pose.txt");
if (!fin)
{
cerr<<"cannot find pose file"<<endl;
return 1;
}
for ( int i=0; i<5; i++ )
{
boost::format fmt( "./data/%s/%d.%s" ); //图像文件格式
colorImgs.push_back( cv::imread( (fmt%"color"%(i+1)%"png").str() ));
depthImgs.push_back( cv::imread( (fmt%"depth"%(i+1)%"pgm").str(), -1 )); // 使用-1读取原始图像
double data[7] = {0};
for ( int i=0; i<7; i++ )
{
fin>>data[i];
}
Eigen::Quaterniond q( data[6], data[3], data[4], data[5] );
Eigen::Isometry3d T(q);
T.pretranslate( Eigen::Vector3d( data[0], data[1], data[2] ));
poses.push_back( T );
}
// 计算点云并拼接
// 相机内参
double cx = 325.5;
double cy = 253.5;
double fx = 518.0;
double fy = 519.0;
double depthScale = 1000.0;
cout<<"正在将图像转换为 Octomap ..."<<endl;
// octomap tree
octomap::OcTree tree( 0.05 ); // 参数为分辨率
for ( int i=0; i<5; i++ )
{
cout<<"转换图像中: "<<i+1<<endl;
cv::Mat color = colorImgs[i];
cv::Mat depth = depthImgs[i];
Eigen::Isometry3d T = poses[i];
octomap::Pointcloud cloud; // the point cloud in octomap
for ( int v=0; v<color.rows; v++ )
for ( int u=0; u<color.cols; u++ )
{
unsigned int d = depth.ptr<unsigned short> ( v )[u]; // 深度值
if ( d==0 ) continue; // 为0表示没有测量到
if ( d >= 7000 ) continue; // 深度太大时不稳定,去掉
Eigen::Vector3d point;
point[2] = double(d)/depthScale;
point[0] = (u-cx)*point[2]/fx;
point[1] = (v-cy)*point[2]/fy;
Eigen::Vector3d pointWorld = T*point;
// 将世界坐标系的点放入点云
cloud.push_back( pointWorld[0], pointWorld[1], pointWorld[2] );
}
// 将点云存入八叉树地图,给定原点,这样可以计算投射线
tree.insertPointCloud( cloud, octomap::point3d( T(0,3), T(1,3), T(2,3) ) );
}
// 更新中间节点的占据信息并写入磁盘
tree.updateInnerOccupancy();
cout<<"saving octomap ... "<<endl;
tree.writeBinary( "octomap.bt" );
return 0;
}
3.3 TSDF 地图和Fusion系列
这章节介绍三维重建,这个方向与SLAM相似但也有不同。在SLAM建图中,往往以定位为主体,而地图拼接则是放在后续过程中进行。之所以这么做是因为定位算法可以满足实时性的需求,而地图的加工可以在关键帧进行处理,无需实时响应。同时,定位算法的运算往往是轻量的,特别是稀疏特征或则稀疏直接法的时候。而地图的表达与存储则是重量级的,他的规模和计算需求大,不利于实时计算,特别是稠密地图的构建,往往只能在关键帧层进行计算。
而定位为主体的建图,并没有对稠密地图进行优化,往往存在“鬼影”的问题。比如当两帧同时观测到一个椅子时,由于定位结果的误差,导致拼接结果往往不够好,即使是同一个椅子也无法重叠在一起。这种现象明显是我们想要避免的,理想的重建结果是光滑的,完整的。
所以这就引出了三维重建这个以”建图“为主体的方向,而定位居于次要的位置。因为是建图为主体,所以需要GPU加速运算,甚至需要多个高级GPU进行并行加速。实时重建往往向着大规模,大型动态场景的重建方向发展。而SLAM往往是轻量级,小型化的方向发展。
此从有了RGB-D传感器后,实时三维重建也成了一个重要的发展方向,书中列出的工作有:Kinect Fusion[120], Dynamic Fusion[121],Elastic Fusion[122],Fusion4D[123],Volumn Deform [124]。其中Kinect Fusion完成了基本的模型重建,但仅限于小型场景;后面的工作则是往大型的,运动的甚至变形的场景下拓展。下图展示了一些重建结果。
TSDF地图(Truncated Signed Distance Function)是一种网格形式(方块式)的地图,如下图所示。先选定要建模的三维空间,比如这么大的地图,按照一定的分辨率,将这个空间分为许多小块,存储小块的信息。不过TSDF地图是存储在GPU显存中而不是内存中,利用GPU的并行特性,可以对每个方格进行计算和更新,而不像CPU那用串行进行。
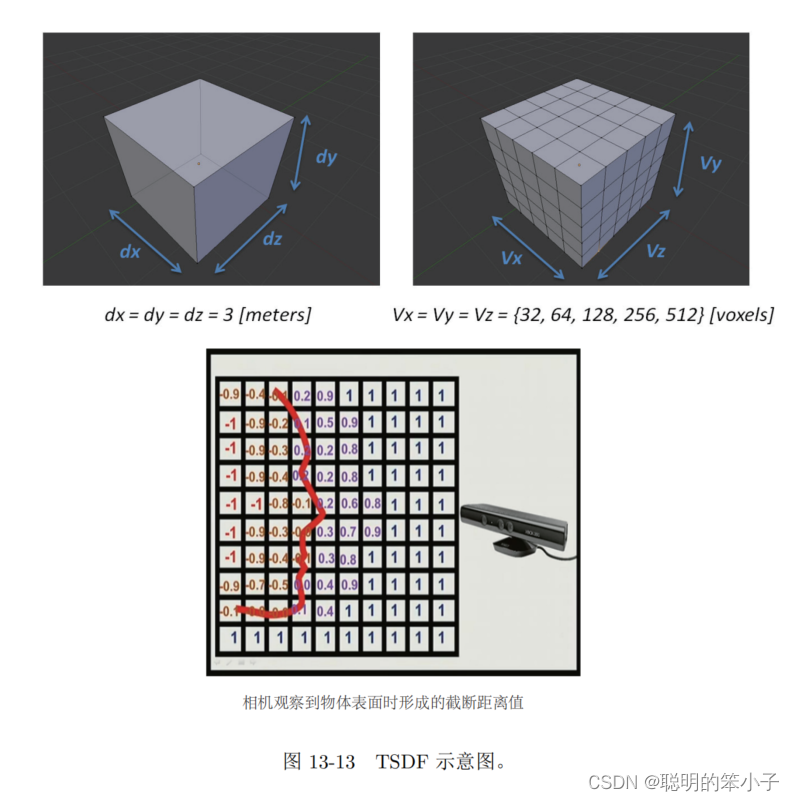
每个TSDF格中,存储了这个小块与最近的物体表面的距离。如果小块在物体表面的前面,他就是一个正值;反之则是负值。由于物体表面通常是薄薄的一层,所以把最大和最小的都取值为1和-1。如果体素中存储的是0,代表这个体素就是物体表面——或则当TSDF由符号号变成正号的地方就是表面本身。上图中给出了一个人脸的TSDF,可以看到人脸表面出现在TSDF符号变化的地方。
而对于次要的“定位”问题,TSDF将当前RGB-D图像与GPU中的TSDF进行匹配对比,估计相机位姿。而建图问题则是根据则个位姿对TSDF地图进行更新。一般还会对RGB-D图像进行一次双边贝叶斯滤波来去除深度图中的噪声。估计相机位姿的算法类似于ICP,不过不同的是TSDF使用GPU并行加速使得可以对整张深度图和TSDF图进行ICP。需要注意的是,TSDF地图并没有保存颜色信息,所以进行匹配时只能利用深度信息来进行匹配,这在一定程度上摆脱了视觉里程计点对光照和纹理的依赖性;同时建图部分亦是对TSDF中的数值进行更新的过程,使得估计的表面更加平滑可靠。















 2951
2951











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









