







目录
12.0 本章内容
1.理解单目SLAM中稠密深度估计的原理
2.了解几种RGB-D重建中的地图形式
本讲介绍建图部分的算法。在前端和后端中,我们重点关注同时估计相机运动轨迹与特征点空间位置的问题。然而,在实际使用SLAM时,除了对相机本体进行定位,还存在许多其他的需求。例如,考虑放在机器人上的SLAM,那么我们会希望地图能够用于定位、导航、避障和交互,特征点地图显然不能满足所有的需求。所以,本讲我们将更详细地讨论各种形式的地图,并指出目前视觉SLAM地图中存在的缺陷。
12.1 概述
建图,本应该是SLAM 的两大目标之一——因为SLAM被称为同时定位与建图。但是直到现在,我们讨论的都是定位问题,包括通过特征点的定位、直接法的定位,以及后端优化。那么,这是否暗示建图在SLAM里没有那么重要,所以直到本讲才开始讨论呢?
答案是否定的。事实上,在经典的SLAM模型中,我们所谓的地图,即所有路标点的集合。一旦确定了路标点的位置,就可以说我们完成了建图。于是,前面说的视觉里程计也好,BA也好,事实上都建模了路标点的位置,并对它们进行了优化。从这个角度上说,我们已经探讨了建图问题。那么为何还要单独介绍建图呢?
这是因为人们对建图的需求不同。SLAM作为一种底层技术,往往是用来为上层应用提供信息的。如果上层是机器人,那么应用层的开发者可能希望使用SLAM做全局的定位,并且让机器人在地图中导航——例如扫地机需要完成扫地工作,希望计算一条能够覆盖整张地图的路径。或者,如果上层是一个增强现实设备,那么开发者可能希望将虚拟物体叠加在现实物体之中,特别地,还可能需要处理虚拟物体和真实物体的遮挡关系。
我们发现,应用层面对于“定位”的需求是相似的,希望SLAM提供相机或搭载相机的主体的空间位姿信息。而对于地图,则存在着许多不同的需求。从视觉SLAM的角度看,“建图”
是服务于“定位”的;但是从应用层面看,“建图”明显带有许多其他的需求。关于地图的用处
我们大致归纳如下:1.定位。定位是地图的一项基本功能。在前面的视觉里程计部分,我们讨论了如何利用局
部地图实现定位。在回环检测部分,我们也看到,只要有全局的描述子信息,我们也能通过回环检测确定机器人的位置。我们还希望能够把地图保存下来,让机器人在下次开机后依然能在地图中定位,这样只需对地图进行一次建模,而不是每次启动机器人都重新做一次完整的SLAM
2.导航。导航是指机器人能够在地图中进行路径规划,在任意两个地图点间寻找路径,然
后控制自己运动到目标点的过程。在该过程中,我们至少需要知道地图中哪些地方不可通过,而哪些地方是可以通过的。这就超出了稀疏特征点地图的能力范围,必须有另外的地图形式。稍后我们会说,这至少得是一种稠密的地图。
3.避障。避障也是机器人经常碰到的一个问题。它与导航类似,但更注重局部的、动态的
障碍物的处理。同样,仅有特征点,我们无法判断某个特征点是否为障碍物,所以需要稠密地图。
4.重建。有时,我们希望利用SLAM获得周围环境的重建效果。这种地图主要用于向人展
示,所以希望它看上去比较舒服、美观。或者,我们也可以把该地图用于通信,使其他人能够远程观看我们重建得到的三维物体或场景——例如三维的视频通话或者网上购物等。这种地图亦是稠密的,并且还对它的外观有一些要求。我们可能不满足于稠密点云重建,更希望能够构建带纹理的平面,就像电子游戏中的三维场景那样。
5.交互。交互主要指人与地图之间的互动。例如,在增强现实中,我们会在房间里放置虚拟的物体,并与这些虚拟物体之间有一些互动——例如我们会点击墙面上放着的虚拟网页浏览器来观看视频,或者向墙面投掷物体,希望它们有(虚拟的)物理碰撞。另外,机器人应用中也会有与人、与地图之间的交互。例如,机器人可能会收到命令“取桌子上的报纸”,那么,除了有环境地图,机器人还需要知道哪一块地图是“桌子”,什么叫作“之上”,什么叫作“报纸”。这就需要机器人对地图有更高层面的认知——也称为语义地图。图12-1形象地解释了上面讨论的各种地图类型与用途之间的关系。我们之前的讨论,基本集中于“稀疏路标地图”部分,还没有探讨稠密地图。所谓稠密地图是相对于稀疏地图而言的。稀疏地图只建模感兴趣的部分,也就是前面说了很久的特征点(路标点)。而稠密地图是指建模所有看到过的部分。对于同一张桌子,稀疏地图可能只建模了桌子的四个角,而稠密地图则会建模整个桌面。虽然从定位角度看,只有四个角的地图也可以用于对相机进行定位,但由于我们无法从四个角推断这几个点之间的空间结构,所以无法仅用四个角完成导航、避障等需要稠密地图才能完成的操作。
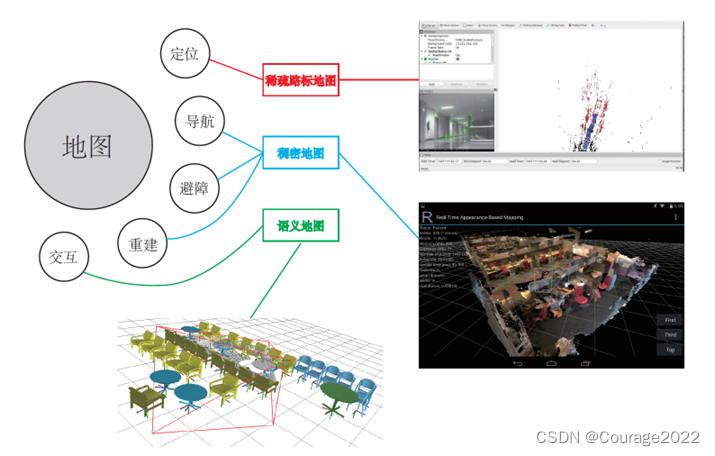
图12-1各种地图的示意图 从上面的讨论中可以看出,稠密地图占据着一个非常重要的位置。于是,剩下的问题是:通过视觉 SLAM能建立稠密地图吗?如果能,怎么建呢?
12.2 双目稠密重建
12.2.1 立体视觉
视觉SLAM的稠密重建问题是本讲的第一个重要话题。相机,被认为是只有角度的传感
器(Bearing only)。单幅图像中的像素,只能提供物体与相机成像平面的角度及物体采集到的亮度,而无法提供物体的距离(Range)。而在稠密重建中,我们需要知道每一个像素点(或大部分像素点)的距离,对此大致上有如下解决方案:1.使用单目相机,估计相机运动,并且三角化计算像素的距离
2.使用双目相机,利用左右目的视差计算像素的距离(多目原理相同)3.使用RGB-D相机直接获得像素距离
前两种方式称为立体视觉(Stereo Vision),其中移动单目相机的又称为移动视角的立体视觉(Moving View Stereo,MVS)。相比于RGB-D直接测量的深度,使用单目和双目的方式对深度获取往往是“费力不讨好”的——计算量巨大,最后得到一些不怎么可靠的R深度估计。当然,RGB-D也有一些量程、应用范围和光照的限制,不过相比于单目和双目的结果,使用RGB-D进行稠密重建往往是更常见的选择。而单目、双目的好处是,在目前RGB-D还无法被很好地应用的室外、大场景场合中,仍能通过立体视觉估计深度信息。
话虽如此,本节我们将带领读者实现一遍单目的稠密估计,体验为何说它是费力不讨好的。我们从最简单的情况讲起:在给定相机轨迹的基础上,如何根据一段时间的视频序列估计某幅图像的深度。换言之,我们不考虑SLAM,先来考虑略为简单的建图问题。
假定有一段视频序列,我们通过某种魔法得到了每一帧对应的轨迹(当然也很可能是由视觉里程计前端估计所得)。现在以第一幅图像为参考帧,计算参考帧中每个像素的深度(或者距离)。首先,请回忆在特征点部分我们是如何完成该过程的:1.对图像提取特征,并根据描述子计算特征之间的匹配。换言之,通过特征,我们对某一
个空间点进行了跟踪,知道了它在各个图像之间的位置。
2.由于无法仅用一幅图像确定特征点的位置,所以必须通过不同视角下的观测估计它的深
度,原理即前面讲过的三角测量。在稠密深度图估计中,不同之处在于,我们无法把每个像素都当作特征点计算描述子。因此,稠密深度估计问题中,匹配就成为很重要的一环:如何确定第一幅图的某像素出现在其他图里的位置呢?这需要用到极线搜索和块匹配技术。当我们知道了某个像素在各个图中的位置,就能像特征点那样,利用三角测量法确定它的深度。不过不同的是,在这里要使用很多次三角测量法让深度估计收敛,而不仅使用一次。我们希望深度估计能够随着测量的增加从一个非常不确定的量,逐渐收敛到一个稳定值。这就是深度滤波器技术。所以,下面的内容将主要围绕这个主题展开。
12.2.2 极线搜索与块匹配
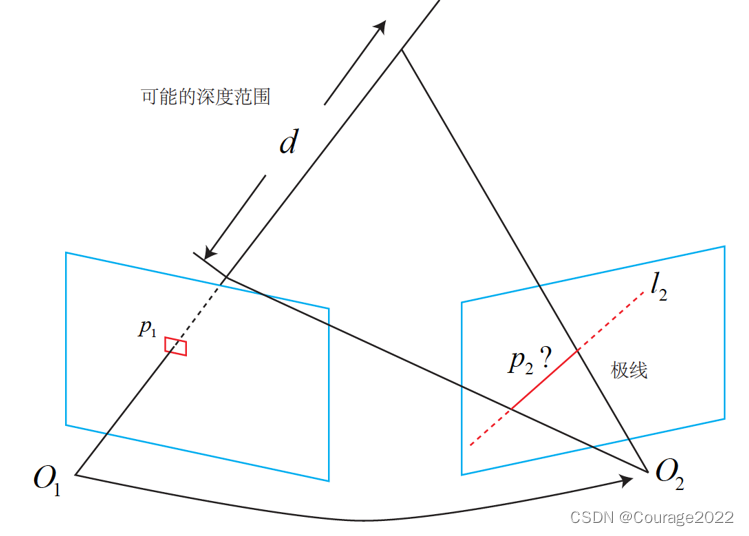
我们先来探讨不同视角下观察同一个点产生的几何关系。这非常像在7.3节讨论的对极几何关系。如图12-2所示,左边的相机观测到了某个像素p1。由于这是一个单目相机,无从知道它的深度,所以假设这个深度可能在某个区域之内,不妨说是某最小值到无穷远之间
。
因此,该像素对应的空间点就分布在某条线段(本例中是射线)上。从另一个视角(右侧相机)看,这条线段的投影也形成图像平面上的一条线,我们知道这称为极线。当知道两部相机间的运动时,这条极线也是能够确定的。那么问题就是:极线上的哪一个点是我们刚才看到的点呢?
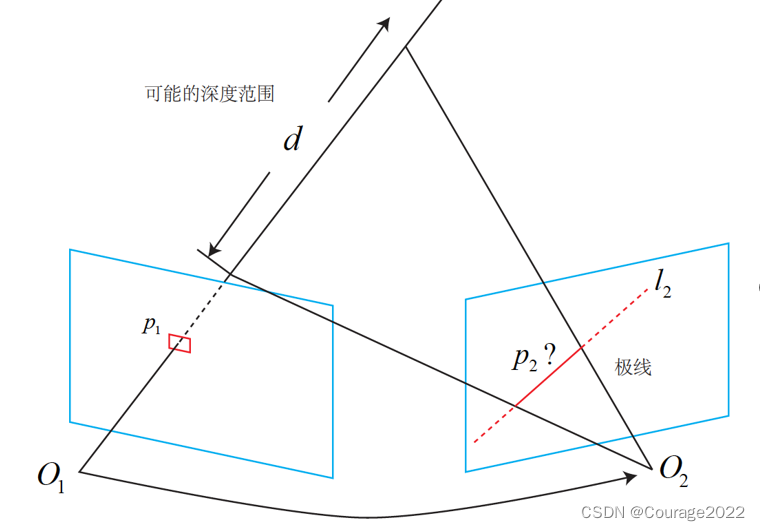
图12-2 极线搜索示意图 重复一遍,在特征点方法中,通过特征匹配找到了
的位置。然而现在我们没有描述子
所以只能在极线上搜索和在直接法的讨论中我们了解到,比较单个像素的亮度值并不一定稳定可靠。一件很明显的事情就是:万一极线上有很多和
一种直观的想法是:既然单个像素的亮度没有区分性,是否可以比较像素块呢?我们在的小块,然后在极线上也取很多同样大小的小块进行比较,就可以在一定程度上提高区分性。这就是所谓的块匹配。在这个过程中,只有假设在不同图像间整个小块的灰度值不变,这种比较才有意义。所以算法的假设,从像素的灰度不变性变成了图像块的灰度不变性——在一定程度上变得更强了。
现在我们取了
,把极线上的n个小块记成
,
。那么,如何计算小块与小块间的差异呢?有若干种的解决办法:
1.SAD(Sum of Absolute Difference)。顾名思义,即取两个小块的差的绝对值之和:
2.SSD。这里的SSD并不是指大家熟悉的固态硬盘,而是平方和(Sum of Squared Distance
)的意思:
3.NCC(Normalized Cross Correlation,归一化互相关)。这种方式比前两种要复杂,它计算的是两个小块的相关性:
请注意,由于这里用的是相关性,所以相关性接近0表示两幅图像不相似,接近1表示相似。前面两种距离则是反过来的,接近0表示相似,而大的数值表示不相似。
和我们遇到过的许多情形一样,这些计算方式往往存在一个精度——效率之间的矛盾。精度好的方法往往需要复杂的计算,而简单的快速算法又往往效果不佳。这需要我们在实际工程中进行取舍。另外,除了这些简单版本,我们可以先把每个小块的均值去掉,称为去均值的SSD、去均值的NCC,等等。去掉均值之后,允许像“小块B比A整体上亮一些,但仍然很相似”这样的情况,因此比之前的更可靠。
现在,我们在极线上计算了A与每一个
12.2.3 高斯分布的深度滤波器
对像素点深度的估计,本身也可建模为一个状态估计问题,于是就自然存在滤波器与非线性优化两种求解思路。虽然非线性优化效果较好,但是在SLAM这种实时性要求较强的场合,考虑到前端已经占据了不少的计算量,建图方面则通常采用计算量较少的滤波器方式。这也是本节讨论深度滤波器的目的。
对深度的分布假设存在若干种不同的做法。一方面,在比较简单的假设条件下,可以假设深度值服从高斯分布,得到一种类卡尔曼式的方法(但实际上只是归一化积,我们稍后会看到)。本着简单易用的原则,我们演示高斯分布假设下的深度滤波器,然后把均匀——高斯混合分布的滤波器作为习题。
设某个像素点的深度d服从:
每当新的数据到来,我们都会观测到它的深度。同样,假设这次观测也是一个高斯分布:
于是,我们的问题是,如何使用观测的信息更新原先d的分布。这正是一个信息融合问题。根据附录A,我们明白两个高斯分布的乘积依然是一个高斯分布。设融合后的d的分布为
,那么根据高斯分布的乘积,有:
由于我们仅有观测方程没有运动方程,所以这里深度仅用到了信息融合部分,而无须像完整的卡尔曼那样进行预测和更新(当然,可以把它看成“运动方程为深度值固定不动”的卡尔曼滤波器)。可以看到融合的方程确实浅显易懂,不过问题仍然存在:如何确定我们观测到深度的分布呢?即如何计算
,
呢?
以图12-4为例。考虑某次极线搜索,我们找到了
对应的
点,从而观测到了
。从而,可记
为
,
为相机的平移
,
记为
并且,把这个三角形的下面两个角记作
。现在,考虑极线
上存在一个像素大小的误差,
使得角变成了
,而
,并记上面那个角为
。我们要问的是,这个像素的误差会导致
与
这是一个典型的几何问题。我们来列写这些量之间的几何关系。显然有:
,
,
对
,
于是,由正弦定理,
由此,我们确定了由单个像素的不确定引起的深度不确定性。如果认为极线搜索的块匹配仅有一个像素的误差,那么就可以设:
当然,如果极线搜索的不确定性大于一个像素,则我们可按照此推导放大这个不确定性。接下来的深度数据融合已经在前面介绍过了。在实际工程中,当不确定性小于一定阈值时,就可以认为深度数据已经收敛了。
综上所述,我们给出了估计稠密深度的一个完整的过程:1.假设所有像素的深度满足某个初始的高斯分布
2.当新数据产生时,通过极线搜索和块匹配确定投影点位置3.根据几何关系计算三角化后的深度及不确定性
4.将当前观测融合进上一次的估计中。若收敛则停止计算,否则返回第2步这些步骤组成了一套可行的深度估计方式。请注意这里说的深度值是
的长度,它和我们在针孔相机模型里提到的“深度”有少许不同——针孔相机中的深度是指像素的
值。
12.2.4 像素梯度的问题
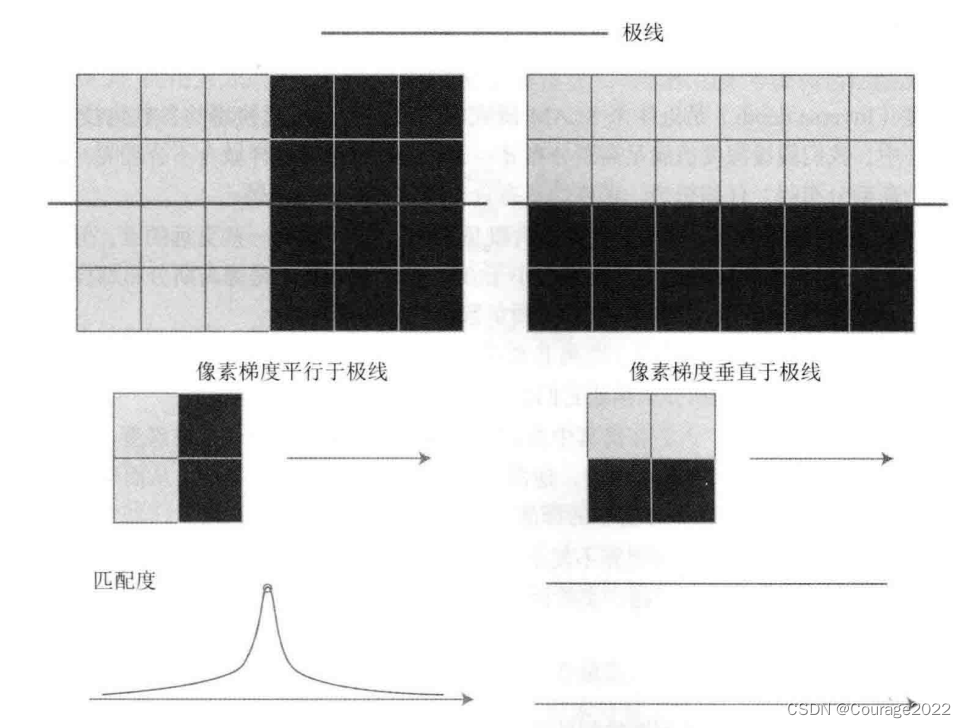
对深度图像进行观察,会发现一件明显的事实。块匹配的正确与否依赖于图像块是否具有区分度。显然,如果图像块仅是一片黑或者一片白,缺少有效的信息,那么在NCC计算中就很可能错误地将它与周围的某块像素匹配。若采样点打印机表面。它是均匀的白非常容易引起误匹配,因此打印机表面的深度信息多半是不正确的——示例程序的空间表面出现了明显不该有的条纹状深度估计,而根据我们的直观想象,打印机表面肯定是光滑的。
这里牵涉一个问题,该问题在直接法中已经见过一次。在进行块匹配(和NCC的计算)时,我们必须假设小块不变,然后将该小块与其他小块进行对比。这时,有明显梯度的小块将具有良好的区分度,不易引起误匹配。对于梯度不明显的像素,由于在块匹配时没有区分性,将难以有效地估计其深度。反之,像素梯度比较明显的地方,我们得到的深度信息也相对准确,例如桌面上的杂志、电话等具有明显纹理的物体。因此,演示程序反映了立体视觉中一个非常常见的问题:对物体纹理的依赖性。该问题在双目视觉中也极其常见,体现了立体视觉的重建质量十分依赖于环境纹理。
我们的演示程序刻意使用了纹理较好的环境,例如,像棋盘格一般的地板,带有木纹的桌面,等等,因此能得到一个看似不错的结果。然而在实际中,像墙面、光滑物体表面等亮度均匀的地方将经常出现,影响我们对它的深度估计。从某种角度来说,该问题是无法在现有的算法流程上加以改进并解决的——如果我们依然只关心某个像素周围的邻域(小块)的话。
以下图为例,我们举两种比较极端的情况:像素梯度平行于极线方向,以及垂直于极线方向。先来看垂直的情况。在垂直的例子里,即使小块有明显梯度,当我们沿着极线做块匹配时,会发现匹配程度都是一样的,因此得不到有效的匹配。反之,在平行的例子里,我们能够精确地确定匹配度最高点出现在何处。而实际中,梯度与极线的情况很可能介于二者之间:既不是完全垂直也不是完全平行。这时,我们说,当像素梯度与极线夹角较大时,极线匹配的不确定性大;而当夹角较小时,匹配的不确定性变小。而在演示程序中,我们把这些情况都当成一个像素的误差,实际是不够精细的。考虑到极线与像素梯度的关系,应该使用更精确的不确定性模型。
12.2.5 逆深度
从另一个角度看,我们不妨问:把像素深度假设成高斯分布是否合适呢?这里关系到一个参数化的问题。
在前面的内容中,我们经常用一个点的世界坐标
三个量来描述它,这是一种参数化形式。我们认为
和深度值
来描述某个空间点(即稠密建图)。我们认为
不同的参数化形式,实际都描述了同一个量,也就是某个三维空间点。考虑到当在相机中看到某个点时,它的图像坐标
参数化一个点,那么它的
逆深度(Inverse depth)是近年来SLAM研究中出现的一种广泛使用的参数化技巧。在我们假设深度值满足高斯分布
。然而这样做合不合理呢?深度真的近似于一个高斯分布吗?仔细想想,深度的正态分布确实存在一些问题:
1.我们实际想表达的是:这个场景深度大概是5~10米,可能有一些更远的点,但近处肯定不会小于相机焦距(或认为深度不会小于0)。这个分布并不是像高斯分布那样,形成一个对称的形状。它的尾部可能稍长,而负数区域则为零。
2.在一些室外应用中,可能存在距离非常远,乃至无穷远处的点。我们的初始值中难以涵盖这些点,并且用高斯分布描述它们会有一些数值计算上的困难。于是,逆深度应运而生。人们在仿真中发现,假设深度的倒数,也就是逆深度,为高斯分布是比较有效的。随后,在实际应用中,逆深度也具有更好的数值稳定性,从而逐渐成为一种通用的技巧,存在干现有SLAM方案中的标准做法中。
从正深度改成逆深度亦不复杂。只要在前面出现深度的推导中,将
即可。
12.2.6 图像间的变换
在块匹配之前,做一次图像到图像间的变换是一种常见的预处理方式。这是因为,我们假设了图像小块在相机运动时保持不变,而这个假设在相机平移时(示例数据集基本都是这样的例子)能够保持成立,但当相机发生明显的旋转时,就难以继续保持了。特别地,当相机绕光心旋转时,一块下黑上白的图像可能会变成一个上黑下白的图像块,导致相关性直接变成了负数(尽管仍然是同一个块)。
为了防止这种情况的出现,通常需要在块匹配之前,把参考帧与当前帧之间的运动考虑进来。根据相机模型,参考帧上的一个像素
与真实的三维点世界坐标
有以下关系:
类似地,对于当前帧,亦有
:
代入并消去
当知道
时,可以计算出
,就可以求得
的增量
。通过这种方式,算出在局部范围内参考帧和当前帧图像坐标变换的一个线性关系构成仿射变换:
根据仿射变换矩阵,我们可以将当前帧(或参考帧)的像素进行变换,再进行块匹配,以期获得对旋转更好的效果。
12.2.7 并行化:效率的问题
稠密深度图的估计非常费时,这是因为要估计的点从原先的数百个特征点一下子变成了几十万个像素点,即使现在主流的CPU也无法实时地计算那样庞大的数量。不过,该问题亦有另一个性质:这几十万个像素点的深度估计是彼此无关的!这使并行化有了用武之地。
在示例程序中,我们在一个二重循环里遍历了所有像素,并逐个对它们进行极线搜索。当使用CPU时,这个过程是串行进行的:必须是上一个像素计算完毕后,再计算下一个像素。然而实际上,下一个像素完全没有必要等待上一个像素计算结束,因为它们之间并没有明显的联系,所以可以用多个线程,分别计算每个像素,然后将结果统一起来。理论上,如果我们有30万个线程,那么该问题的计算时间和计算一个像素是一样的。
GPU的并行计算架构非常适合这样的问题,因此,在单双和双目的稠密重建中,经常看到利用GPU进行并行加速的方式。当然,本书不准备涉及GPU编程,所以我们在这里仅指出利用GPU加速的可能性,具体实践留给读者作为验证。根据一些类似的工作,利用GPU的稠密深度估计是可以在主流GPU上实时化的。
12.2.7 其他的改进
事实上,我们还能提出许多对本例程进行改进的方案,例如:
1.现在各像素完全是独立计算的,可能存在这个像素深度很小,边上一个又很大的情况。我
们可以假设深度图中相邻的深度变化不会太大,从而给深度估计加上了空间正则项。这种做法会使得到的深度图更加平滑。
2.我们没有显式地处理外点(Outlier)的情况。事实上,由于遮挡、光照、运动模糊等各种
因素的影响,不可能对每个像素都保持成功匹配。而只要NCC大于一定值,就认为出现了成功的匹配,没有考虑到错误匹配的情况。3.处理错误匹配亦有若干种方式。例如均匀-高斯混合分布下的深度滤波器,显式地将内点与外点进行区别并进行概率建模,能够较好地处理外点数据。
从上面的讨论可以看出,存在许多可能的改进方案。如果我们细致地改进每一步的做法,最后是有希望得到一·个良好的稠密建图的方案的。然而,正如我们所讨论的,有一些问题存在理论上的困难,例如对环境纹理的依赖,又如像素梯度与极线方向的关联(以及平行的情况)。这些问题很难通过调整代码实现来解决。所以,直到目前为止,虽然双目和移动单目相机能够建立稠密的地图,但是我们通常认为它们过于依赖环境纹理和光照,不够可靠。
12.3 RGB-D建图理论
除了使用单目和双目相机进行稠密重建,在适用范围内,RGB-D相机是一种更好的选择
在第11讲中详细讨论的深度估计问题,在RGB-D相机中可以完全通过传感器中硬件的测量得到,无须消耗大量的计算资源来估计。并且,RGB-D的结构光或飞时原理,保证了深度数据对纹理的无关性。即使面对纯色的物体,只要它能够反射光,我们就能测量到它的深度。这也是RGB-D传感器的一大优势。利用RGB-D进行稠密建图是相对容易的。不过,根据地图形式不同,也存在着若干种不同的主流建图方式。最直观、最简单的方法就是根据估算的相机位姿,将RGB-D数据转化为点云,然后进行拼接,最后得到一个由离散的点组成的点云地图(Point Cloud Map)。在此基础上,如果我们对外观有进一步的要求,希望估计物体的表面,则可以使用三角网格(Mesh)、面片(Surfel)进行建图。另外,如果希望知道地图的障碍物信息并在地图上导航,也可通过体素(Voxel)建立占据网格地图(Occupancy Map)。
12.3.1 点云地图示例代码
#include <iostream> #include <fstream> using namespace std; #include <opencv2/core/core.hpp> #include <opencv2/highgui/highgui.hpp> #include <Eigen/Geometry> #include <boost/format.hpp> // for formating strings #include <pcl/point_types.h> #include <pcl/io/pcd_io.h> #include <pcl/filters/voxel_grid.h> #include <pcl/visualization/pcl_visualizer.h> #include <pcl/filters/statistical_outlier_removal.h> int main(int argc, char **argv) { vector<cv::Mat> colorImgs, depthImgs; // 彩色图和深度图 vector<Eigen::Isometry3d> poses; // 相机位姿 ifstream fin("./data/pose.txt"); if (!fin) { cerr << "cannot find pose file" << endl; return 1; } for (int i = 0; i < 5; i++) { boost::format fmt("./data/%s/%d.%s"); //图像文件格式 colorImgs.push_back(cv::imread((fmt % "color" % (i + 1) % "png").str())); depthImgs.push_back(cv::imread((fmt % "depth" % (i + 1) % "png").str(), -1)); // 使用-1读取原始图像 double data[7] = {0}; for (int i = 0; i < 7; i++) { fin >> data[i]; } Eigen::Quaterniond q(data[6], data[3], data[4], data[5]); Eigen::Isometry3d T(q); T.pretranslate(Eigen::Vector3d(data[0], data[1], data[2])); poses.push_back(T); } // 计算点云并拼接 // 相机内参 double cx = 319.5; double cy = 239.5; double fx = 481.2; double fy = -480.0; double depthScale = 5000.0; cout << "正在将图像转换为点云..." << endl; // 定义点云使用的格式:这里用的是XYZRGB typedef pcl::PointXYZRGB PointT; typedef pcl::PointCloud<PointT> PointCloud; // 新建一个点云 PointCloud::Ptr pointCloud(new PointCloud); for (int i = 0; i < 5; i++) { PointCloud::Ptr current(new PointCloud); cout << "转换图像中: " << i + 1 << endl; cv::Mat color = colorImgs[i]; cv::Mat depth = depthImgs[i]; Eigen::Isometry3d T = poses[i]; for (int v = 0; v < color.rows; v++) for (int u = 0; u < color.cols; u++) { unsigned int d = depth.ptr<unsigned short>(v)[u]; // 深度值 if (d == 0) continue; // 为0表示没有测量到 Eigen::Vector3d point; point[2] = double(d) / depthScale; point[0] = (u - cx) * point[2] / fx; point[1] = (v - cy) * point[2] / fy; Eigen::Vector3d pointWorld = T * point; PointT p; p.x = pointWorld[0]; p.y = pointWorld[1]; p.z = pointWorld[2]; p.b = color.data[v * color.step + u * color.channels()]; p.g = color.data[v * color.step + u * color.channels() + 1]; p.r = color.data[v * color.step + u * color.channels() + 2]; current->points.push_back(p); } // depth filter and statistical removal PointCloud::Ptr tmp(new PointCloud); pcl::StatisticalOutlierRemoval<PointT> statistical_filter; statistical_filter.setMeanK(50); statistical_filter.setStddevMulThresh(1.0); statistical_filter.setInputCloud(current); statistical_filter.filter(*tmp); (*pointCloud) += *tmp; } pointCloud->is_dense = false; cout << "点云共有" << pointCloud->size() << "个点." << endl; // voxel filter pcl::VoxelGrid<PointT> voxel_filter; double resolution = 0.03; voxel_filter.setLeafSize(resolution, resolution, resolution); // resolution PointCloud::Ptr tmp(new PointCloud); voxel_filter.setInputCloud(pointCloud); voxel_filter.filter(*tmp); tmp->swap(*pointCloud); cout << "滤波之后,点云共有" << pointCloud->size() << "个点." << endl; pcl::io::savePCDFileBinary("map.pcd", *pointCloud); return 0; }点云地图提供了比较基本的可视化地图,让我们能够大致了解环境的样子。它以三维方式存储,使我们能够快速地浏览场景的各个角落,乃至在场景中进行漫游。点云的一大优势是可以直接由RGB-D图像高效地生成,不需要额外处理。它的滤波操作也非常直观,且处理效率尚能接受。不过,使用点云表达地图仍然是十分初级的,我们不妨按照之前提的对地图的需求,看看点云地图是否能满足这些需求。
1.定位需求:取决于前端视觉里程计的处理方式。如果是基于特征点的视觉里程计,由于点
云中没有存储特征点信息,则无法用于基于特征点的定位方法。如果前端是点云的ICP,那么可以考虑将局部点云对全局点云进行ICP以估计位姿。然而,这要求全局点云具有较好的精度。我们处理点云的方式并没有对点云本身进行优化,所以是不够的。
2.导航与避障的需求:无法直接用于导航和避障。纯粹的点云无法表示“是否有障碍物”的信息,我们也无法在点云中做“任意空间点是否被占据”这样的查询,而这是导航和避障的基本需要。不过,可以在点云基础上进行加工,得到更适合导航与避障的地图形式。3.可视化和交互:具有基本的可视化与交互能力。我们能够看到场景的外观,也能在场景里漫游。从可视化角度来说,由于点云只含有离散的点,没有物体表面信息(例如法线。所以不太符合人们的可视化习惯。例如,从正面和背面看点云地图的物体是一样的,而且还能透过物体看到它背后的东西:这些都不太符合我们日常的经验。
综上所述,我们说点云地图是“基础的”或“初级的”,是指它更接近传感器读取的原始数据。它具有一些基本的功能,但通常用于调试和基本的显示,不便直接用于应用程序。如果我们希望地图有更高级的功能,那么点云地图是一个不错的出发点。例如,针对导航功能,可以从点云出发,构建占据网格(Occupancy Grid)地图,以供导航算法查询某点是否可以通过。再如,SfM中常用的泊松重建方法,就能通过基本的点云重建物体网格地图,得到物体的表面信息。除了泊松重建,Surfel也是一种表达物体表面的方式,以面元作为地图的基本单位,能够建立漂亮的可视化地图。
12.3.2 八叉树地图
下面介绍一种在导航中比较常用的、本身有较好的压缩性能的地图形式:八叉树地图(Octo-map)。在点云地图中,我们虽然有了三维结构,也进行了体素滤波以调整分辨率,但是点云有几个明显的缺陷:
点云地图通常规模很大,所以ped文件也会很大。一幅640像素×480像素的图像,会产生30万个空间点,需要大量的存储空间。即使经过一些滤波后,pcd文件也是很大的。而且讨厌之处在于,它的“大”并不是必需的。点云地图提供了很多不必要的细节。我们并不特别关心地毯上的褶皱、阴暗处的影子这类东西,把它们放在地图里是在浪费空间。由于这些空间的占用,除非我们降低分辨率,否则在有限的内存中无法建模较大的环境,然而降低分辨率会导致地图质量下降。有没有什么方式对地图进行压缩存储,舍弃一些重复的信息呢?
点云地图无法处理运动物体。因为我们的做法里只有“添加点”,而没有“当点消失时把它移除”的做法。而在实际环境中,运动物体的普遍存在,使得点云地图变得不够实用。接下来我们要介绍的就是一种灵活的、压缩的、能随时更新的地图形式:八叉树(Octo-tree)。
我们知道,把三维空间建模为许多个小方块(或体素)是一种常见的做法。如果我们把
一个小方块的每个面平均切成两片,那么这个小方块就会变成同样大小的八个小方块。这个步骤可不断地重复,直到最后的方块大小达到建模的最高精度。在这个过程中,把“将一个小方块分成同样大小的八个”这件事,看成“从一个节点展开成八个子节点”,那么,整个从最大空间细分到最小空间的过程,就是一棵八叉树。如下图所示,左侧显示了一个大立方体不断地均匀分成八块,直到变成最小的方块为止。于是,整个大方块可以看作根节点,而最小的块可以看作“叶子节点”。于是,在八叉树中,当我们由下一层节点往上走一层时,地图的体积就能扩大为原来的八倍。我们不妨做一点简单的计算:如果叶子节点的方块大小为
,那么当我们限制八叉树为10层时,总共能建模的体积大约为
,这足够建模一间屋子了。由于体积与深度呈指数关系,所以当我们用更大的深度时,建模的体积会增长得非常快。
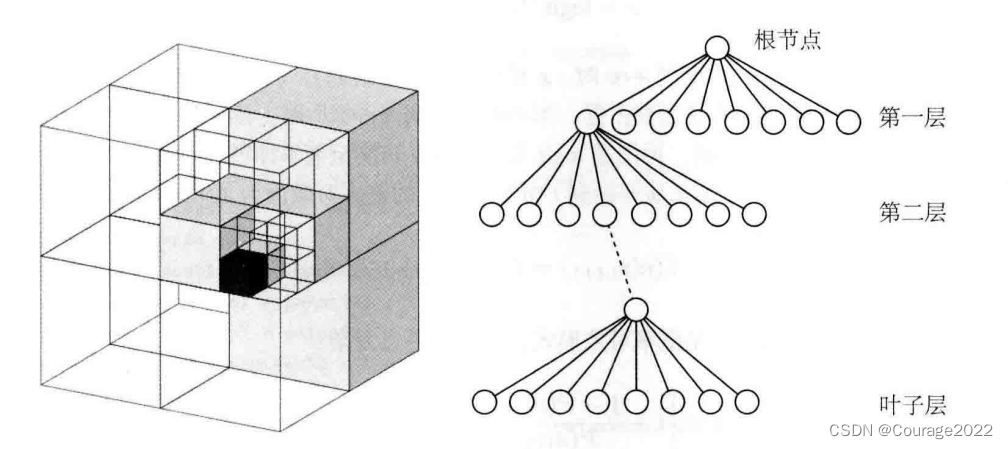
图 八叉树示意图 读者可能会疑惑,在点云的体素滤波器中,我们不是也限制了一个体素中只有一个点吗?为何我们说点云占空间,而八叉树比较节省空间呢?这是因为,在八叉树中,在节点中存储它是否被占据的信息。当某个方块的所有子节点都被占据或都不被占据时,就没必要展开这个节点。例如,一开始地图为空白时,我们只需一个根节点,不需要完整的树。当向地图中添加信息时,由于实际的物体经常连在一起,空白的地方也会常常连在一起,所以大多数八叉树节点无须展开到叶子层面。所以说,八叉树比点云节省大量的存储空间。
前面说八叉树的节点存储了它是否被占据的信息。从点云层面来讲,自然可以用0表示空白,1表示被占据。这种0-1的表示可以用一个比特来存储,节省空间,不过显得有些过于简单了。由于噪声的影响,可能会看到某个点一会儿为0,一会儿为1;或者多数时刻为0,少数时刻为1;或者除了“是”“否”两种情况,还有一个“未知”的状态。能否更精细地描述这件事呢?我们会选择用概率形式表达某节点是否被占据的事情。例如,用一个浮点数
来表达。这个
一开始取0.5。如果不断观测到它被占据,那么让这个值不断增加;反之,如果不断观测到它是空白,那就让它不断减小即可。
通过这种方式,我们动态地建模了地图中的障碍物信息。不过,现在的方式有一点小问题:如果让
区间之外,带来处理上的不便。所以我们不是直接用概率来描述某节点被占据,而是用概率对数值(Log-odds)来描述。设
为概率对数值,
其反变换为:
可以看到,当
从
变到
时,
,观测数据为
,
时刻为:
如果写成概率形式而不是概率对数形式,就会有一点复杂:
有了对数概率,就可以根据RGB-D数据更新整个八叉树地图了。假设在RGB-D图像中观测到某个像素带有深度
















 3021
3021











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











