







上篇:02 机器学习任务攻略-学习笔记-李宏毅深度学习2021年度
下篇:04 自动调整学习率(Learning Rate)-学习笔记-李宏毅深度学习2021年度
本节内容及相关链接
- 当loss不够好,且梯度接近为0时,应该怎么办?
- local minima和saddle point
- batch
- momentum
课堂笔记
local minima(局部最小值):在损失函数的迭代过程中,当前参数陷入了局部最小值,即当前gradient为0,且周围点的gradient都是向着loss增大的方向
三维空间中,如图:

二维空间中,如图:
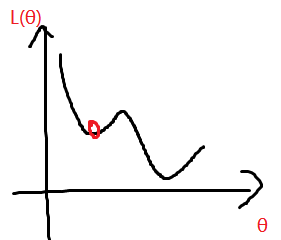
saddle point:当前参数的gradient为0,但是存在周围点的gradient是向着loss减小的方向。
三维图像,如图:

二维图像,如图:
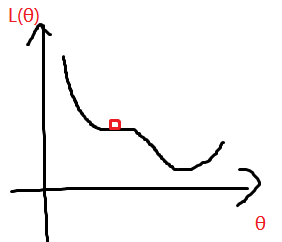
local minima 和 saddle point 统称为 critical point
当gradient接近0,且loss不够小,说明卡在了 critical point
使用矩阵的特征值可以判断当前是卡在local minima还是saddle point。对于saddle point,可以通过特征向量找到方向。详情请参考视频和PPT
解决 critical point 的方法:
1. 采用合适的Batch Size,通常采用较小的Batch Size
2. 在每个epoch后,对train set进行shuffle
3. 增加Momentum
Small Batch 与 Large Batch的比较:

Momentum:为梯度下降增加一个动量(惯性),使其可以逃离local minima
Momentum的具体做法:每次不仅考虑当前的梯度,还考虑上一次更新的梯度。
因为每一个时刻的梯度都考虑了上一时刻的梯度,所以也可换句话说:每次不仅考虑当前的梯度,还考虑之前的所有更新过得梯度
Gradient Descent + Momentum 的具体参数更新公式:

λ
\lambda
λ 为要调的超参数
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











