






1. 分类问题的输出其实是一个概率
2. 二分类:只有两个分类的问题(0和1)
3. 饱和函数:导函数图像类似于正态分布,x越接近0,图像斜率越大,离0越远,斜率越小,当超过某一阈值时,导数值越来越小,最后趋近于0
4. Logistic函数:西格玛(x)(Logistic函数用的很多,因为其能保证函数的输出值在0~1之间,这是一个很重要的性质;当需要输出值在-1~1之间即均值为0时,就要用到其他的sigmoid函数了)
5. logistic回归和线性回归区别就是:线性回归加了一个sigmoid函数,将其数值缩放到0~1之间
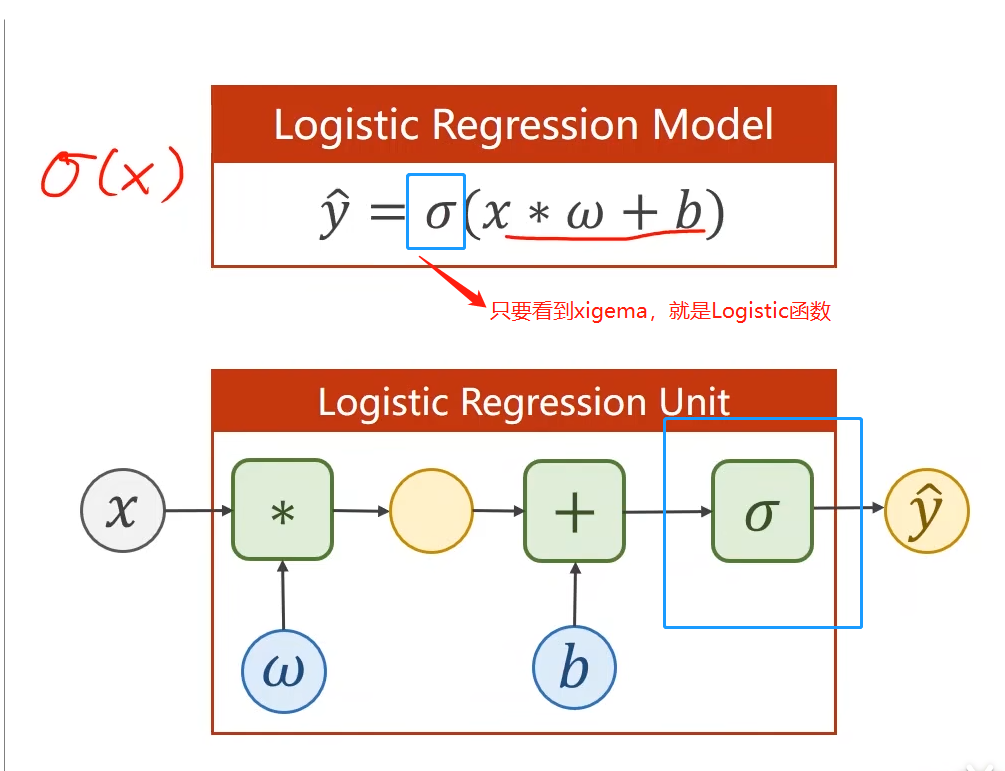
二分类的损失函数:
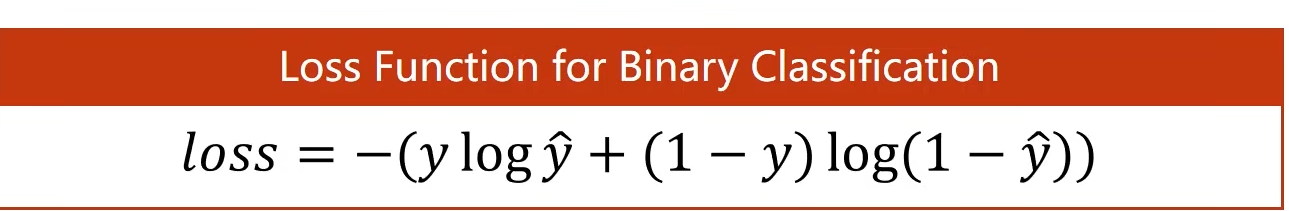
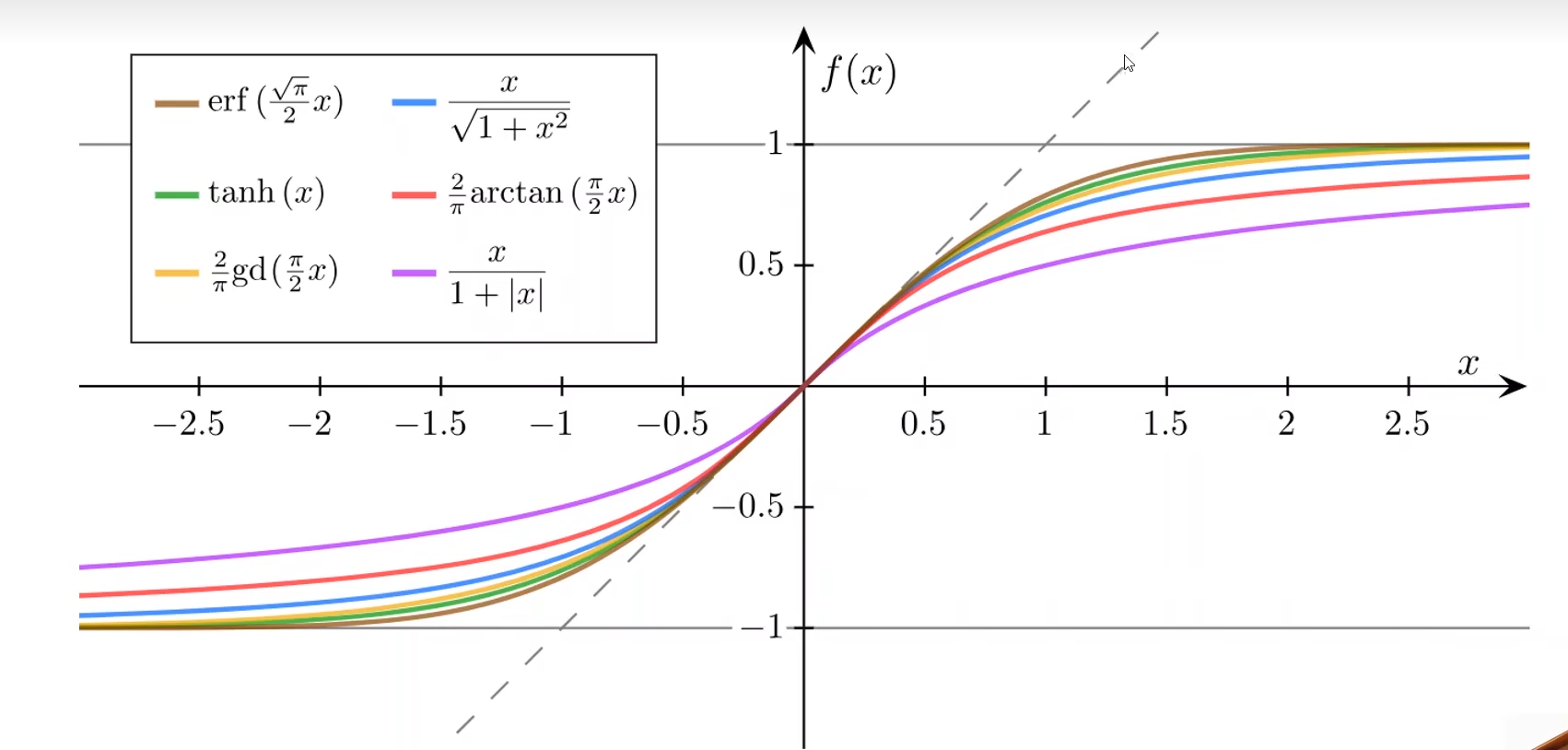
其他的sigmoid函数(sigmoid函数中最出名的就是Logistic函数,很多资料中说的sigmoid函数指的就是Logistic函数)
BCELoss:二分类交叉熵(Binary Cross Entropy)
torch.nn中的nn:Neural Networks
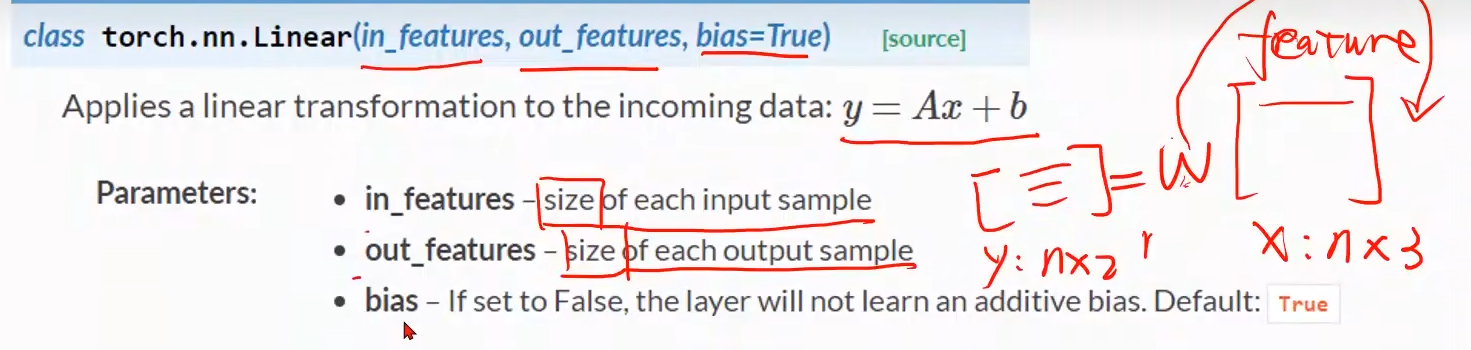
bias:表示是否要偏执量,默认为True
import torch
import numpy as np
import matplotlib.pyplot as plt
x_data = torch.tensor([[1.0], [2.0], [3.0]])
# 这里的y_data如果不加.float()会报错“Found dtype Long but expected Float”
y_data = torch.tensor([[0], [0], [1]]).float()
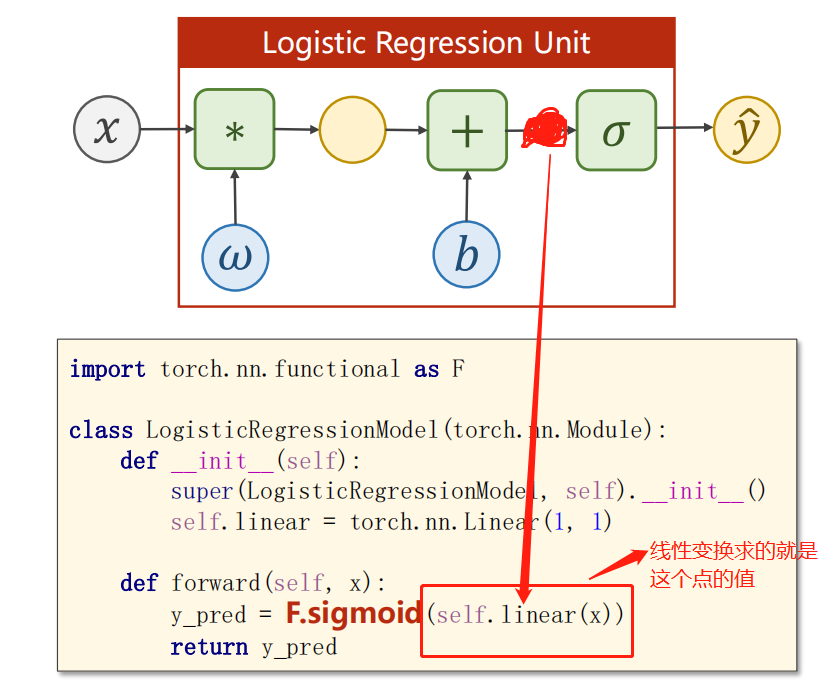
class LogisticRegressionModel(torch.nn.Module):
def __init__(self):
super(LogisticRegressionModel, self).__init__()
self.linear = torch.nn.Linear(1, 1)
def forward(self, x):
y_pred = torch.sigmoid(self.linear(x))
return y_pred
lemodel = LogisticRegressionModel()
criterion = torch.nn.BCELoss(reduction='sum')
optimizer = torch.optim.SGD(lemodel.parameters(), lr=0.01)
for epoc in range(1000):
y_pred = lemodel(x_data)
loss = criterion(y_pred, y_data)
print(epoc, loss.item())
optimizer.zero_grad()
loss.backward()
optimizer.step()
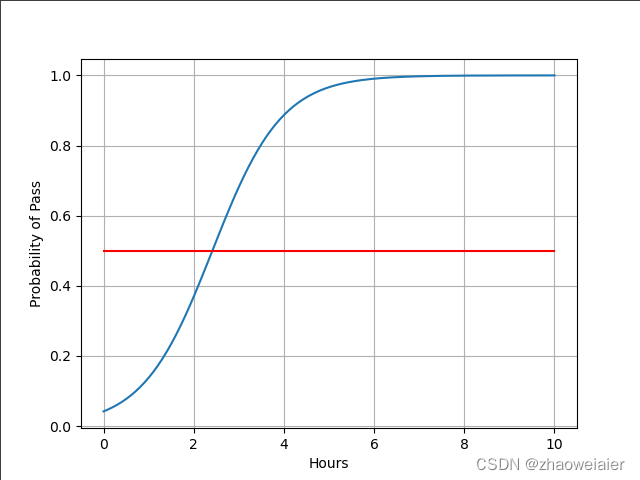
x=np.linspace(0,10,200)# 在0~10之间取200个点
x_t=torch.Tensor(x).view((200,1))#将这200个点变成200行1列的矩阵——张量
y_t=lemodel(x_t)# 将这个张量送到模型中就得到y
y=y_t.data.numpy()
plt.plot(x,y)
plt.plot([0,10],[0.5,0.5],c='r')
plt.xlabel('Hours')
plt.ylabel('Probability of Pass')
plt.grid()
plt.show()















 457
457











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









